블로그명: Some intuitions about large language models
블로그 링크: https://www.jasonwei.net/blog/some-intuitions-about-large-language-models
Some intuitions about large language models — Jason Wei
An open question these days is why large language models work so well. In this blog post I will discuss six basic intuitions about large language models. Many of them are inspired by manually examining data, which is an exercise that I’ve found helpful a
www.jasonwei.net
OpenAI 에서 연구하시는 Jason Wei 님의 블로그 글을 의역하고자 합니다. 오랫동안 연구하신 분으로 그의 경험과 시야를 공부하고 함께 공유하고자 합니다. 실제로 Jason Wei 님께서도 자신이 거대언어모델(LLM)을 연구하며 느낀 6가지 직관에 대해 모두를 위해 공유한다고 하니 진심으로 감사를 전합니다.
(직관이라고 했으니 정말로 그런지는 당연히 알 길이 없습니다. 하지만 이 분야에서 오랫동안 연구하셨으니 신뢰성은 충분하다고 생각합니다. 블로그에 다른 글도 있으니 시간되실 때 참고해보세요.)
1. Next Word Prediction 은 사실 Multi-task Learning 이다
"거대언어모델들은 사실 다음 단어만 예측하잖아?(Next Word Prediction)"
"저렇게 단순한 걸 시켰는데 왜 이렇게 성능이 좋은 거지?"

- 사실 다음 단어만 예측하는 단순한 일이 문법 교정, 번역, 감정 분류 등 다양한 문제를 푸는 것과 다름이 없다고 한다
- 위 그림에서 파란 글자를 예측하는 행위가 사실 저렇게 다양한 Task 를 푸는 것과 동일한다고 본다는 점이다
- 거대언어모델들은 BERT와 다르게 데이터의 양과 종류 역시 방대해지면서 Next Word Prediction 이 강력해졌다고 본다
- 그런데 이 표는 좀 이상적이다 (ideal). 좀 더 현실적으로 보면 아래와 같다.
- factual recall: 기억하고 있는 게 사실인지 확인하는 사실 검증이라고 보면 된다. 거대언어모델이 사실적인 답변을 만드는가 아닌가에 대해 확인하는 task 정도로 보면 좋겠다
- 이렇게 우리가 생각하는 것보다 훨씬 다양한 task 를 하게 된다고 저자는 주장한다
- 즉, Next Word Prediction 이라는 매우 간단한 목적함수가 방대하고 다양한 데이터를 만나면서 매우 높은 지적 수준을 요구하는 문제들을 풀게 된다고 본다
1번에 대한 내 견해
: I absolutely agree with you :)
2. <Input, Output> 관계를 배우는 과정을 Next Word Prediction 이라고도 볼 수 있다
- Next Word Prediction 이 워낙 광범위해서(general), In-Context Learning 의 핵심인 <input, output> 관계를 배웠다고 생각한다고 한다.
2번에 대한 내 견해
: 그런데 저자조차도 In-Context Learning 이 왜 가능한지에 대해 밝혀진 게 없다고 했다. 나도 그런 점에서 2번 직관에 대해서는 다소 가볍게 들으려고 한다. 나 역시 In-Context Learning 의 작동 원리를 알기 위해 여러 논문을 읽었는데 궁금하신 분들은 아래 논문들을 참고하길 바란다.
https://heygeronimo.tistory.com/57
[논문이해] Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers
논문명: Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers 논문링크: https://arxiv.org/abs/2212.10559 Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimiz
heygeronimo.tistory.com
https://heygeronimo.tistory.com/58
[논문이해] What learning algorithm is in-context learning? Investigations with linear models
논문명: What learning algorithm is in-context learning? Investigations with linear models 논문링크: https://arxiv.org/abs/2211.15661 What learning algorithm is in-context learning? Investigations with linear models Neural sequence models, especially
heygeronimo.tistory.com
3. Token 마다 갖고 있는 정보의 밀도가 다르기 때문에 거대언어모델은 생각할 시간이 필요하다
: 제목을 그대로 번역했다 - Tokens can have very different information density, so give language models time to think.
“I’m Jason Wei, a researcher at OpenAI working on large language ___”
- Token 마다 정보의 밀도가 다르다는 것을 이해하고자 예시를 들어보겠다.
- 빈 칸에 뭐가 들어가야 할까? 누가 봐도 model 이 들어가야 할 것 같다
“Jason Wei’s favorite color is ___”
- 빈 칸을 맞출 수 있을까?
- 그와 아는 사이가 아니라면 불가능에 가깝다
Question: What is the square of ((8 - 2) * 3 + 4) ^ 3 / 8 ?
(A) 1,483,492
(B) 1,395,394
(C) 1,771,561
Answer: __
- 이걸 바로 맞출 수 있을까? 매우 구하기 어려울 것이다
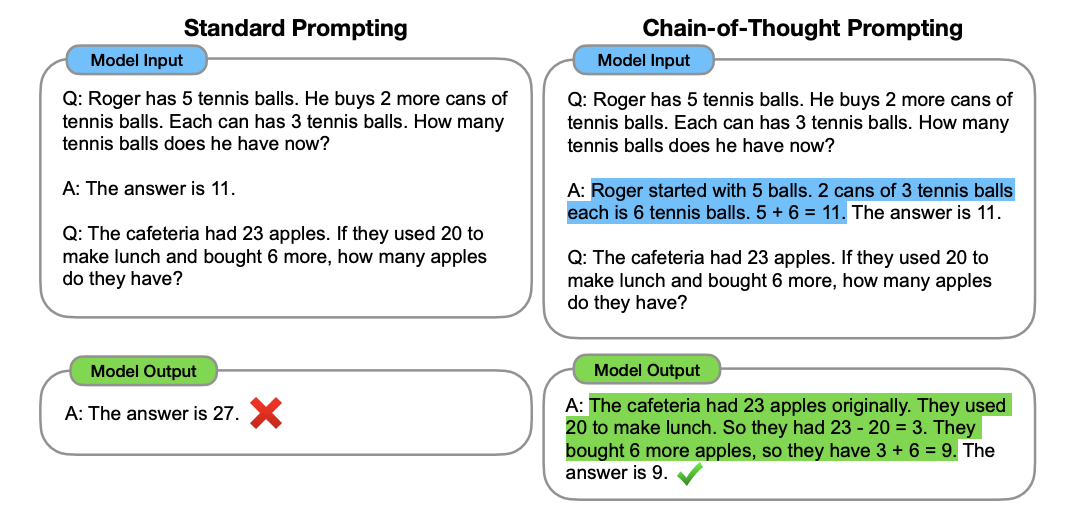
- 이런 문제를 풀기 위한 기법으로 'Chain of Thoughts' 가 있다
- 예컨대, 오른쪽처럼 정답뿐만 아니라 근거도 함께 생성하도록 지시하면 모델의 성능이 개선된다는 방법론이다
저자는 이렇게 말한다.
The key reason that the above next-word prediction tasks work is scaling, which means training larger neural nets on more data. Obviously it costs a lot of money to train frontier language models, and so the reason we do it is that we have reasonable confidence that using larger neural networks and more data will actually lead to a better model (i.e., performance probably won’t saturate when you increase the model and data size).
- Next Word Prediction 이 잘 먹히는 핵심 이유는 데이터와 모델 크기를 키운다는 점이다 (scaling)
3번에 대한 내 견해
: 확실히 3번을 번역하면 느낀 것은 글이 생각의 흐름처럼 작성된 것 같아서 아쉽다는 점이다.
그래서 왜 시간을 더 줘야 해?
- 에 대한 답변이 없다. 아직 밝혀지지 않았다고만 해도 좋았을 텐데.
- 굳이 1 ~ 3번을 통해 추론해보자면,
- ㄱ) 데이터셋에서 근거와 함께 정답이 제시된 분포가 많았기 때문에 1번에서 제시했듯이 '이유/근거와 함께 정답 풀기 태스크'를 진행하면서 거대언어모델이 Chain of Thoughts 능력이 생겼다.
- ㄴ) 정답 직전까지 적힌 문장들에 따라 토큰 정보 밀도/확률이 달라진다. 즉, 근거를 추가로 생성함으로서 밀도/확률이 우리가 원하는 방향에 가깝도록 조정하였다
4. 언어모델의 규모(데이터셋, 파라미터)를 키우면, Loss 를 꾸준히 개선한다
: 사실 LLM 논문을 읽어보면 다양한 실험을 통해 알 수 있다

- GPT4 논문에서 개인적으로 충격적이었던 것은 GPT4를 실험하기 전에 loss 를 예측하는 모델을 만들었다는 점이다
- 이 모델을 통해 대략적으로 이 정도의 파라미터와 이 정도의 데이터셋이면 이 정도의 성능을 내겠구나 예측했다
왜 scaling (규모를 키우는 행위)가 효과적인가
- 저자는 2가지 이유로 추측한다고 본다
- ㄱ) 파라미터 자체가 적을수록 많은 것을 기억할 수 없다 (Capacity 의 한계)
- ㄴ) 작은 언어 모델은 일차적인 상관관계만 학습하는 방면, 큰 언어 모델들은 복잡한 것도 학습할 수 있다
4번에 대한 내 견해
: 그래서 대체 왜 큰 언어 모델들은 복잡한 관계를 학습할 수 있냐고!!! 그걸 알고 싶다!!
5. 전체적으로는 잘 학습하는 것 같지만, 정확히는 창발적인 형태로 학습된다
: 이 제목은 글을 다 읽어야 이해가 가능하다. 그러니 아래부터 읽어보길 바란다.
Overall loss = 1e-10 * (loss of grammar task)
+ 1e-10 * (loss of sentiment analysis task) + …
+ 1e-10 * (loss of math ability task) + …
- 1번에 따르면, Next Word Prediction 은 다양한 태스크를 푸는 것이라 볼 수 있다
- 1번이 맞다는 전제 하에 사전학습 손실함수는 위처럼 다양한 task 에 대한 loss 로 분리할 수 있다
"이때 Overall Loss 가 4 에서 3 으로 줄었다고 가정하자. 과연 골고루(Uniformly) 학습되었을까?"
저자는 아니라고 말한다. Big Bench Dataset 은 200개가 넘는 데이터셋으로 이뤄져있는데 이 데이터셋으로 분석해본 결과, 특정 태스크는 빠르게 수렴하는 반면 특정 태스크는 학습이 좀처럼 이뤄지지 않았다고 말한다.

- 실제로 200개 중 8개의 손실함수 그래프를 나타냈다
- 모델 사이즈가 X축인데 어느 순간을 넘어서자 성능이 확 오르는 것을 볼 수 있다
Emergence: 창발적 능력
The term we use for qualitative changes arising from quantitative changes is “emergence”. More specifically, we call an large language model ability emergent if it is not present in smaller models, but is present in larger models.
- 양적 변화가 질적 변화로 넘어오는 것을 'emergence', 창발적 능력이라고 한다
- 정확히 말하자면 작은 모델들에게 없었던, 하지만 큰 모델들에게 생기는 능력을 의미한다
이에 대해 3가지 중요한 암시를 저자는 한다. 이 부분의 번역에서 오해가 생길까봐 원문을 남겨놓겠다.
There are three important implications of emergence:
1. Emergence is not predictable by simply extrapolating scaling curves from smaller models.
2. Emergent abilities are not explicitly specified by the trainer of the language model.
3. Since scaling has unlocked emergent abilities, further scaling can be expected to further elicit more abilities.
- 창발적 능력은 단순히 그래프를 통해 예측할 수 있는 게 아니다
- 창발적 능력은 학습 단계에서 구체적으로 명시한 게 아니다
- Scaling 이 창발적 능력을 깨웠다면, 더 Scaling 을 할수록 창발적 능력이 강화/가속화될 것이다
6. 진정한 In-Context Learning 은 거대모델에서만 일어난다

- 위 표는 In-Context Learning 에 대한 실험이다
- 일부러 상식적으로 맞지 않는 라벨을 붙여서 모델에게 줘봤다. 예컨대, "1 + 1 = 3 일 때, 2 + 2 는 얼마야" 처럼 물어본 셈이다. 위 실험에서는 긍정적인 문장에 부정이라고 표기했다.
- 이렇게 잘못된 형태로 예제(demonstrations)를 제공했을 때, 모델들의 반응을 살폈다. 만약 In-Context Learning 을 진짜로 할 수 있다면, 일부러 틀린 형태의 예제를 주면 함께 틀려야 할 것이다.
- 오른쪽 실험 결과, 거대언어모델들은 일부러 틀린 예제에 맞춰서 함께 틀렸다. 반면 작은 모델이나 비교적 SOTA 에 비해 부족한 모델(예시: GPT3)은 제공된 예제를 무시하고 정답을 맞췄다.
- 즉, 진정한 거대언어모델들은 <Input, Output> 의 관계를 살피고 있다고 한다.
위 실험과 관계된 논문들을 정리한 적이 있어서 아래에 남기며 이 글을 마치겠다.
https://heygeronimo.tistory.com/51
[논문이해] LARGER LANGUAGE MODELS DO IN-CONTEXT LEARNING DIFFERENTLY
논문명: LARGER LANGUAGE MODELS DO IN-CONTEXT LEARNING DIFFERENTLY https://arxiv.org/abs/2303.03846 Larger language models do in-context learning differently We study how in-context learning (ICL) in language models is affected by semantic priors versus
heygeronimo.tistory.com
https://heygeronimo.tistory.com/50
[논문이해] A Survey on In-context Learning
논문명: A Survey on In-context Learning 논문 링크: https://arxiv.org/abs/2301.00234 A Survey on In-context Learning With the increasing ability of large language models (LLMs), in-context learning (ICL) has become a new paradigm for natural language
heygeronimo.tistory.com
https://heygeronimo.tistory.com/53
[논문이해] Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
논문명: Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? 논문 링크: https://arxiv.org/abs/2202.12837 Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? Large language models (LMs) are able to in-co
heygeronimo.tistory.com
https://heygeronimo.tistory.com/56
[논문이해] Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations
논문명: Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations 논문링크: https://arxiv.org/abs/2205.12685 Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations Despite recent explosion of interests in in-contex
heygeronimo.tistory.com
'NLP > Insight' 카테고리의 다른 글
| [Insight] Successful language model evals (0) | 2024.06.04 |
|---|