논문명: LARGER LANGUAGE MODELS DO IN-CONTEXT LEARNING DIFFERENTLY
https://arxiv.org/abs/2303.03846
Larger language models do in-context learning differently
We study how in-context learning (ICL) in language models is affected by semantic priors versus input-label mappings. We investigate two setups-ICL with flipped labels and ICL with semantically-unrelated labels-across various model families (GPT-3, Instruc
arxiv.org
부록이 매우 긴 논문이라서, 부록은 제외하고 핵심과 실험만 정리했음을 밝힙니다.
요약
: 초록에서 핵심이 다 나오니, 이것만 읽어도 된다
- 모델은 크기가 커질수록, 기존에 갖고 있던 상식보다 주어진 문맥을 파악해서 답변할 수 있다.
- 반대 답변(flipped labels): 누가봐도 positive 인데 negative 라고 예시를 주면, 작은 모델은 이런 예시를 무시하고 기존 상식에 부합하는 답을 내는 반면, 거대 모델은 예시에 따라 반대로 답변한다.
- 무관한 답변(semantically unrelated labels): 예컨대, 긍정은 고양이, 부정은 호랑이로 치환해서 예제를 주면, 거대 모델은 그런 경우를 무시하고 답을 잘 한다.
- 즉, 모델의 크기가 커짐에 따라, 예시가 기존 상식에서 벗어난 규칙성을 띄더라도 그 규칙성에 따라 답변한다.
실험 설정
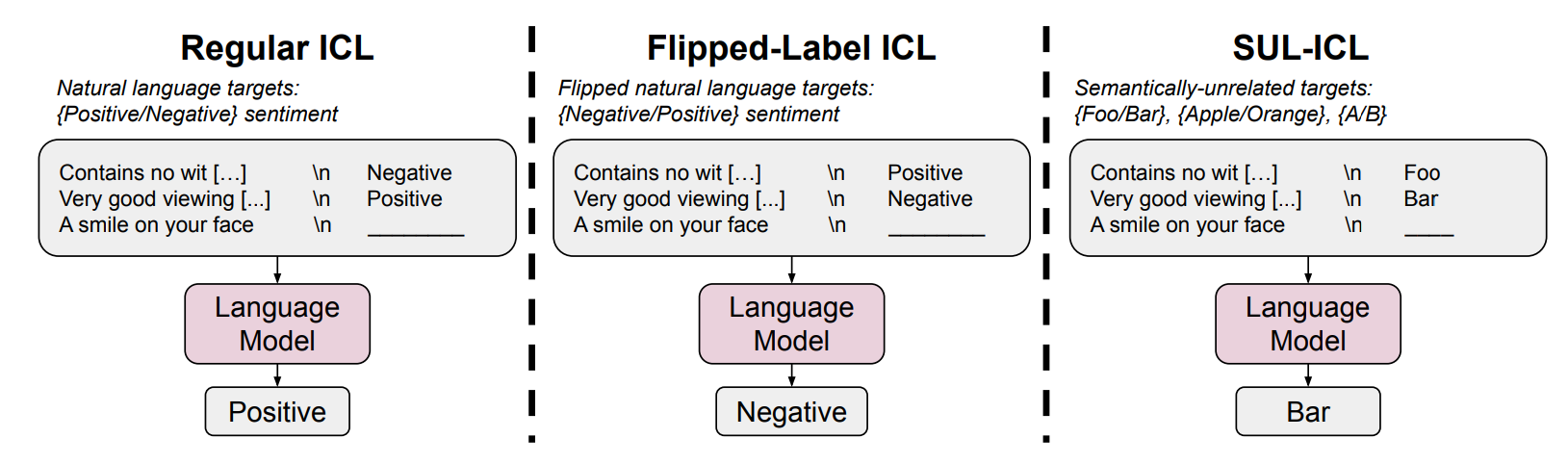
이 논문은 요약에서 언급했듯이, 정답에 변화를 준다. 즉, 입력과 정답과의 관계를 모델이 어떻게 이해하는가를 다양한 실험에 따라서 나눴다고 보면 된다.
- Regular ICL: 우리가 상식적으로 사용하는 데이터 (예시: 나는 네가 좋아 - 긍정)
- Filpped-Label ICL: 정답과 반대로 연결된 데이터 (예시: 나는 네가 좋아 - 부정)
- SUL-ICL: 정답과 무관하게 연결된 데이터 (예시: 나는 네가 좋아 - 수박)
모델 목록
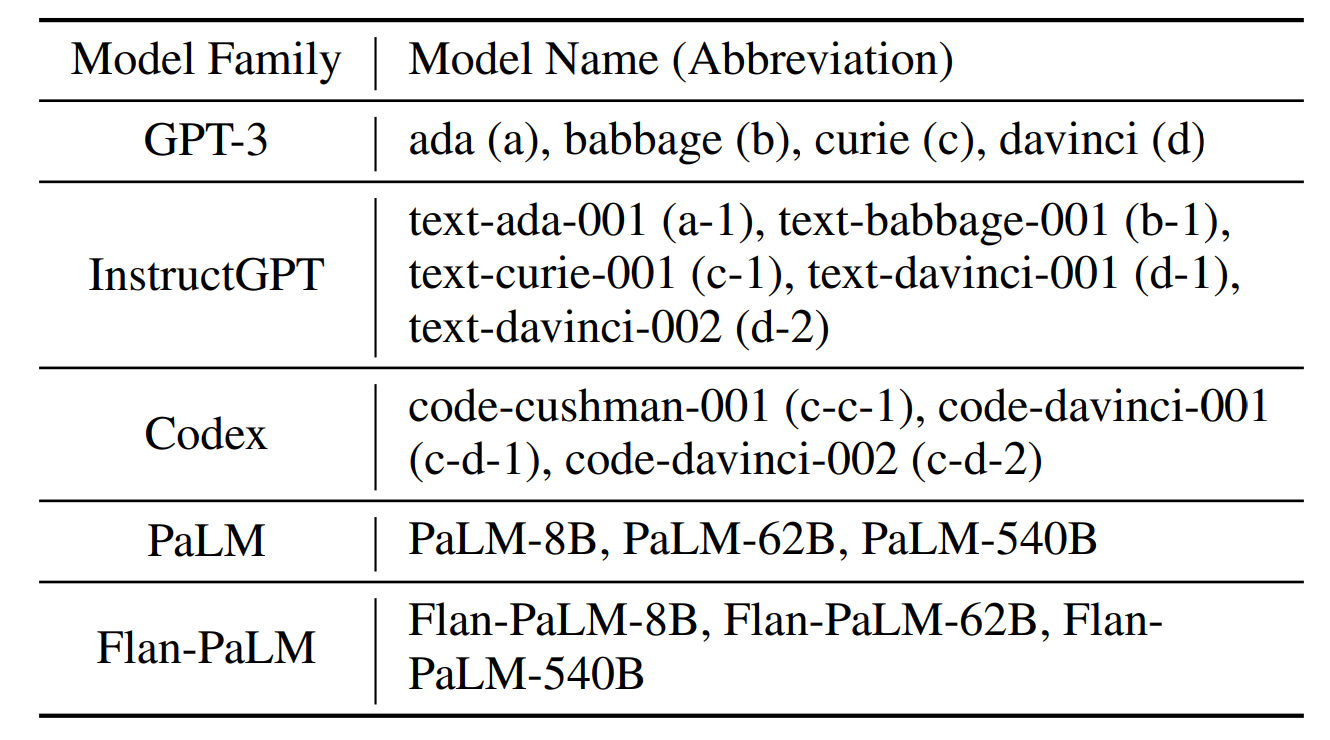
- 이 논문에선 모델의 크기가 적힌 순서대로 점점 커진다, 오름차순이라고 이해하면 좋다.
- 실험 설정은 예제가 기본적으로 16개가 In Context Learning 에 활용된다는 정도만 알면 된다.
다만, 최근에 등장한 GPT4에 관한 실험은 없어서 아쉽다.
실험1: 반대인 오답이 연결된 예제를 주면, 어떻게 될까
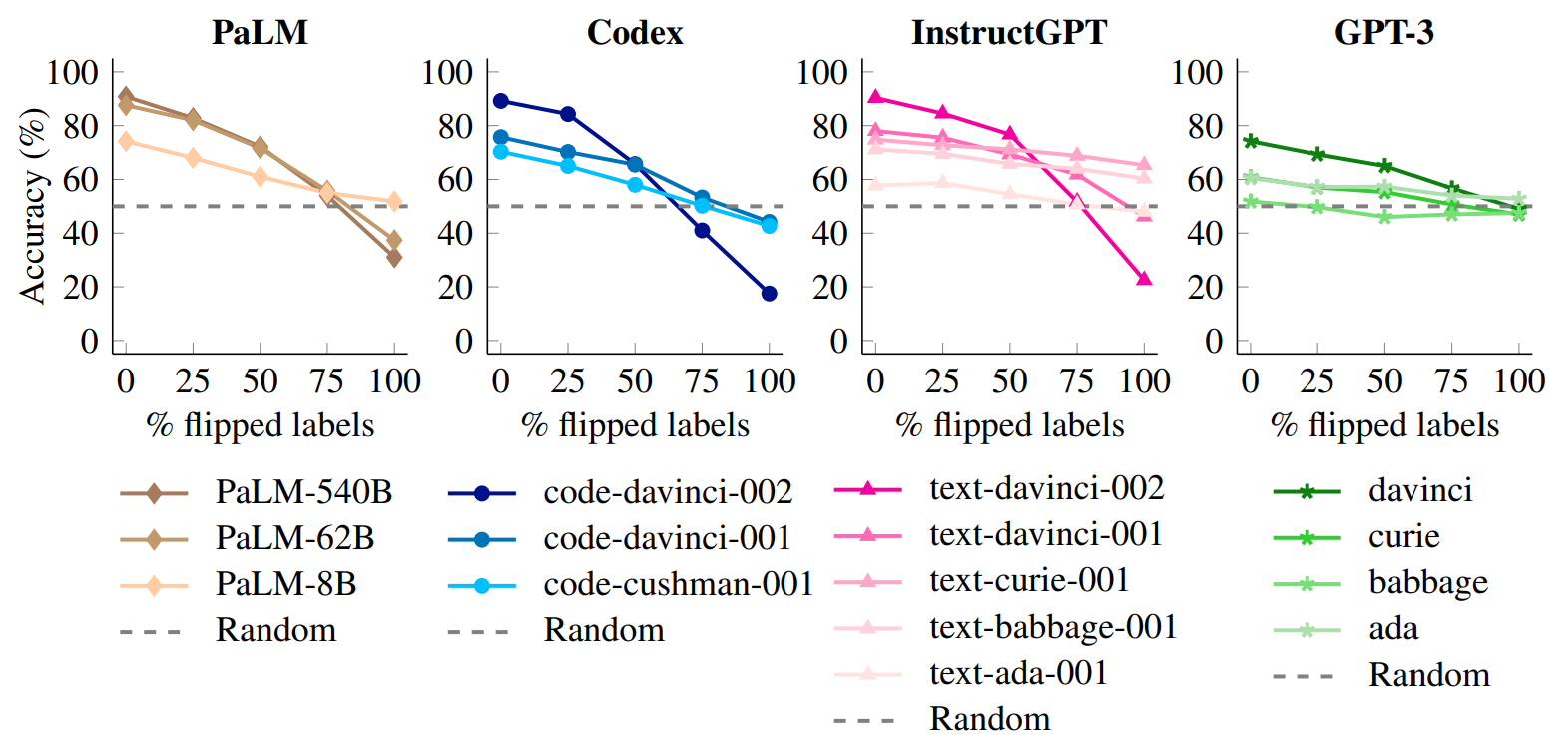
- 평가할 때는 데이터셋에 손대지 않았기 때문에 반대 예시를 잘 따를수록 성능이 저하되어야 한다.
- 거대한 모델일수록 성능이 하락폭이 높다, 즉 기존 상식보다 주어진 예제를 더 잘 따른다.
실험2: 아예 관계 없는 걸 답으로 주면 어떻게 될까

- 연한 색상이 관련 없는 답, 진한 색상이 정답을 연결한 결과다.
- 예컨대, positive 는 foo, negative 는 bar 라고 한다.
- 큰 모델들은 대부분 관련 없는 답에 영향을 받지 않고 기존과 같은 성능을 보인다.
- 반면 작은 모델들은 관련 없는 답에 크게 영향을 받아 성능이 감소한다.
- 모델이 커질수록 두 설정 모두 성능은 증가한다.
실험3: 예제의 개수가 중요할까

- 개수가 늘어날수록 성능이 증가한다. 이때 증가하는 폭은 모델의 크기가 클수록 빠르다.
- 즉, 모델이 크면 빠르게 예제로부터 학습한다고 볼 수 있다.
실험4: 모델 크기가 전부다
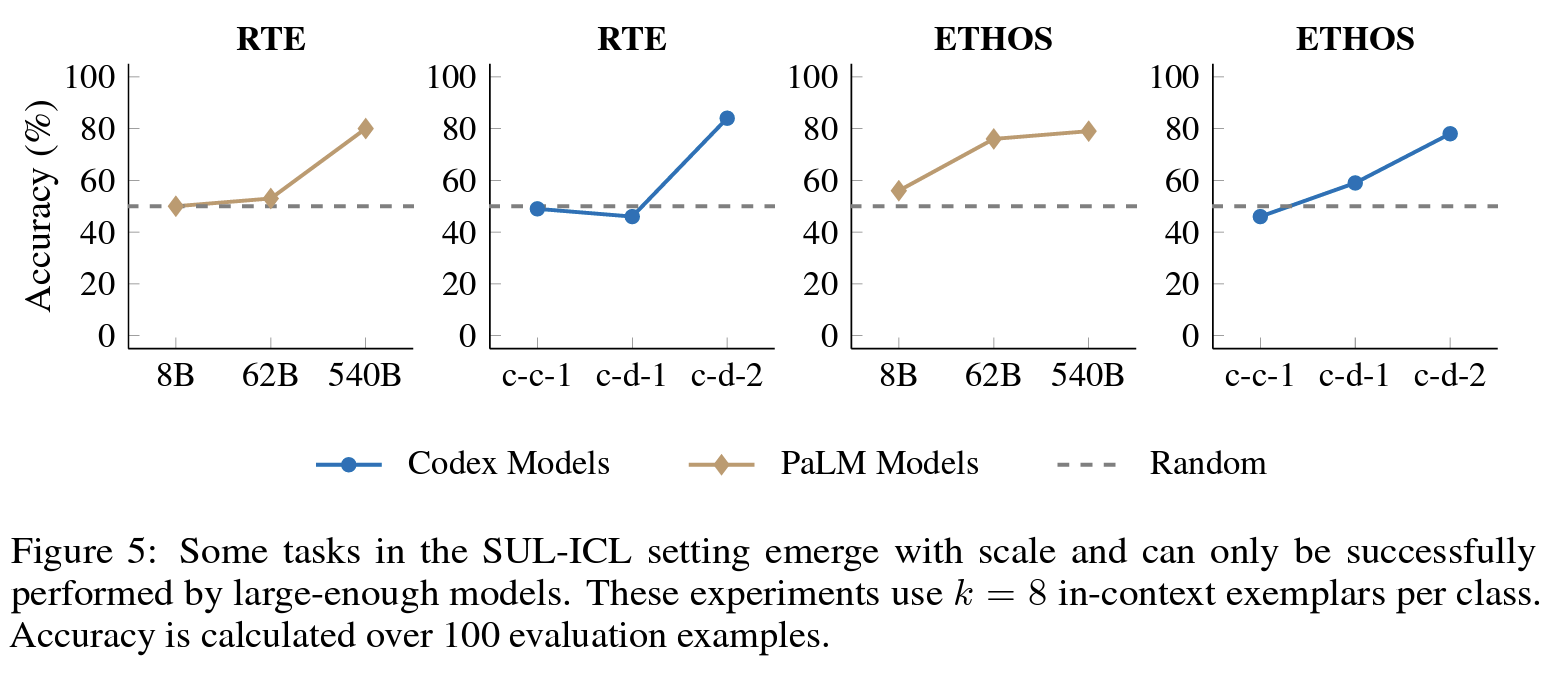
- RTE, ETHOS 라는 데이터셋에서 성능을 측정했다.
- 각 데이터셋 별로 성능이 오르는 구간이 비슷하다. 이 점으로 미루어 볼 때, 관련 없는 답을 연결해도 성능을 낼 수 있는 요인은 모델 크기가 유일하다는 걸 알 수 있다.
(사견: 사실 거대 모델이 주목받는 이유 중 하나가 바로 이런 점인 것 같다. 단순히 모델의 크기가 증가했다는 이유지만, 그 이유 하나로 다양한 능력을 갖게 되었으며, AI의 폭발적인 성능 향상을 불러온 듯 하다.)
실험5: Instruction model 은 어떨까
기본 성능 확인

- PaLM 을 instruction tuning 한 모델이 Flan-PaLM 이라고 보면 된다.
- GPT3와 InstructGPT를 비교하지 않은 이유는 공개가 안 되어 있어서 애초에 같은 모델로 시작했다는 증거도 없고, 무엇으로 학습했는지 불명확하기 때문에 PaLM에 대해서만 실험했다고 한다.
- 우선 위 그림을 보면 알 수 있듯이, 기본적으로 Flan-PaLM의 성능이 더 높은 것으로 볼 때 instruction finetuning은 In Context Learning 에 도움이 된다.
기존 상식을 더 따른다

- 반대인 답을 넣어서 예제로 제공한 결과, 반대로 답하지 않고 기존 상식에 부합하게 답을 했다.
- 그래서 성능이 별로 하락하지 않았는데, instruction 기반 모델은 오히려 자신의 상식을 따른다고 한다.
사견: 이 결론이 모든 instruction model에게 통용된다고는 볼 수 없는 게, GPT3.5와 GPT4로 간단히 실험해본 결과 GPT4는 놀라웠다.
'NLP > 논문이해' 카테고리의 다른 글
| [논문이해] Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? (2) | 2023.07.20 |
|---|---|
| [논문이해] Noisy Channel Language Model Prompting for Few-Shot Text Classification (0) | 2023.07.14 |
| [논문이해] A Survey on In-context Learning (0) | 2023.07.10 |
| [논문이해] Let's verify step by step (0) | 2023.06.21 |
| [논문이해] Less is More: CLIPBERT for Video-and-Language Learning via Sparse Sampling (0) | 2023.02.24 |



