논문명: Noisy Channel Language Model Prompting for Few-Shot Text Classification
https://arxiv.org/abs/2108.04106
Noisy Channel Language Model Prompting for Few-Shot Text Classification
We introduce a noisy channel approach for language model prompting in few-shot text classification. Instead of computing the likelihood of the label given the input (referred as direct models), channel models compute the conditional probability of the inpu
arxiv.org
In Context Learning 에 관심이 있어서 해당 논문을 읽었다. ICL의 관점에서만 본다면, Channeling 방식은 해당 모델을 load할 수 없는 경우엔 사용할 수 없는 것 같다.
논문 제목 분석
- Noisy: 보통 AI 논문에서는 데이터의 품질이 좋지 않다고 하는 것 같다. 실제로 이 논문은 데이터셋이 불균형이거나 매우 적거나, 아직 본 적 없는 정답(unseen label)에 대해서도 효과적이라고 말하기 때문이다.
- Channel: channeling 이라는 방식이 있다. 이 방식은 저자가 애용하시며, 실제로 후속 논문에서도 등장한다. 성능도 좋다. 하여튼, 이런 방식이 있구나 정도로 넘어가면 된다.
- Few shot: 현재 자연어 처리 분야는 용어가 혼잡해서 정리가 필요했는데, 이 당시엔(2021) In Context Learning 이라는 표현이 널리 쓰이지 않았던 것 같다. 그리고 논문에서 few shot finetuning 과 In Context Learning with few examples 모두 실험한다. 그러니, few shot 의 의미가 In Context Learning 에 프롬프트로 쓰이는 예제 개수일 수 있고, finetuning 을 위해 쓰이는 예제 개수일 수 있겠다.
What is Channeling?

Direct
- 영화 후기를 긍정/부정으로 분류한다고 가정하자.
- 입력: A three hour cinema master class, 출력: It was great / It was terrible
- 보통 이 경우에, It was great 와 It was terrible 이 나올 확률 중 높은 게 출력되며 그걸 정답으로 간주한다.
- 이런 방식을 Direct 라고 한다.
Channel
- Bayesian Rule 을 정리하면, P(x | y) 로 표현가능하다. (이걸 모른다면, Bayesian 정리를 찾아볼 것)
- 입력과 출력을 바꿔 넣는 방식을 Channel 이라고 한다.
- 실제 논문에서 related work로, 2000년대부터 번역 등 다양한 분야에서 쓰인 방법이라고 밝힌다.
의의
- noisy channel approach 를 통해 demonstration method(In Context Learing)과 prompt tuning(fine tuning)에서 모두 기존 direct 방식보다 성능이 뛰어났다.
- 이 방식은 데이터셋이 불균형하거나 적을 때, 혹은 등장하지 않은 정답에도 강력하다.
- ablation study 를 통해 상황에 따라 어떤 방법론을 사용하는 것이 더 좋을지에 대해서도 제시한다.
Method
Demonstrations method

기호 설명
- x: 입력 (예시: '영화보다가 잠든 건 처음이다', '이 영화를 몰랐다면 얼마나 불행했을까.')
- c: 답 (예시: 0, 1, 'Positive', 'Negative' etc)
- v: verbalizer 라고 하는데, 예컨대 'Negative'를 'It was terrible'이라고 바꿔주는 장치를 의미한다.
- x1, v(c1): 이렇게 한쌍이다. (입력, 답) 한쌍을 예시로 줬다는 의미다. 순서가 바뀌면, (답, 입력) 형태로 준 것이다.
입력 방식
- zero shot: 어떤 예시도 주지 않은 채, 맞춰보라고 한 것. 방식간의 차이가 가장 명확히 드러나는 부분이다.
- concat - based demonstrations: 예시를 함께 제공한 것
- ensemble - based demonstrations: 이건 예시를 들어서 이해하는 게 쉬우니 K = 4 라고 가정하자. 한번에 예시를 4개를 주면, 발생하는 문제 중 하나는 예시의 순서에 따라서도 성능이 달라진다는 점이다. 이걸 방지하고자, 예시를 하나씩만 넣어서 확률을 구한다. 그러면 확률 4개를 구할 수 있는데, 그걸 곱해서 결과를 내자는 것이다. 이렇게 하면 예시의 순서와 관계 없는 결과를 낼 수 있다. 위 표를 보면, 유일하게 확률곱으로 이뤄진 걸 확인할 수 있다.
Direct++ (사견)
- Direct 를 개선한 방식이라는데, 설명이 짧고 내 견문이 좁아서 명확히 이해하지 못했다.
- zero shot 수식을 보면, 아무것도 넣지 않았을 때의 확률로 나눠주는 걸 보면 모델의 편향성을 제거하는 것처럼 보인다.
- 예컨대, 모델 A는 아무것도 넣지 않아도 'Great' 보다 'Terrible' 을 생성할 확률이 4배 높다고 가정하자. 마치 매사 부정적인 사람에게 긍정/부정을 평가해달라고 하면, 편향성이 남아서 태스크 성능에도 영향을 미칠 수 있다는 것이다. 그래서 나눈 것이 아닐까 하는 추측을 해본다.
Tuning method

- 노란색만 학습한다고 보면 된다.
- All finetuning: 우리가 다 아는, 모두 학습하는 방식
- Head tuning: Head 만 학습하는 방식
- Transformation tuning: 기존 파라미터는 두고, 새롭게 층을 추가하여 그것만 학습함
- Prompt tuning: LM을 blackbox라 가정하고, prompt 를 N개 추가해서 그것만 학습하는 방식
위 방식에서 실험해서 어디서 무엇이 효과적인지 밝힌다고 한다. 다만, 이건 In Context Learning 이 아니고 parameter update 가 발생한다는 점이 Demonstrations method와 다르다는 걸 기억하자.
실험
데이터셋
- 분류를 한다고 논문 제목에 쓰여 있었고, class 개수만 간단히 보고 가면 된다.
실험 설정
- 예시는 별 말 없으면 K = 16 이다.
- 모델은 GPT-large 인데, 실험에 따라 달라질 수 있다.
- 성능은 평균/최악을 표기한다. 최악을 표기하는 이유는 편차가 심하지 않다는 걸 확인할 수 있기 때문이다.
Demonstartions Method 실험

- Direct vs Direct++: 확실히 성능이 대부분 개선되었음을 볼 수 있다. 이건 나중에 관련 논문을 봐야 할듯.
- Direct++ vs Channel: 대부분에서 성능이 개선되었음을 확인할 수 있다. 표준편차는 부록에서 확인 가능하며, 이를 통해 channel 이 성능 개선뿐만 아니라 완강함(robustness)도 끌어올렸음을 확인할 수 있다.
- Concat vs Ensemble: 앙상블 방식이 기존 방식보다 최악/평균 성능 모두 개선되었음을 알 수 있다. 하지만 앙상블 방식은 channel 에게 항상 효과적이지 않은데, 길이가 긴 데이터셋에서만 좋은 경향이 있다.
- zero shot vs few shot: Direct 방식에서는 오히려 성능이 하락할 수 있다. 하지만 Channel 은 few examples 로부터 성능 개선을 이뤄냈다.
Tuning method 실험

- Direct vs Channel in Prompt tuning: 해당 방식에서 Channel 이 우수함을 확인할 수 있다. 그것도 10% 이상 차이가 난다. 부록에서 표준편차를 확인할 수 있는데, 최고 성능은 Direct 가 높은 경우가 있는데 그만큼 최저 성능은 낮아서 완강함까지 고려하면 Channel 이 압도한다고 볼 수 있다.
- Head tuning: Direct 기준 3가지 방법 중 성능이 압도적이다. 일부 데이터셋에서는 Channel 보다 성능이 좋은데, 질의응답과 주제 분류 태스크라서 Head 를 직접 update 하는 게 더 좋았던 것 같다고 말한다.
- 물론 Channel all finetuning 이 가장 성능이 좋았다고 한다.
예제 개수에 따른 실험
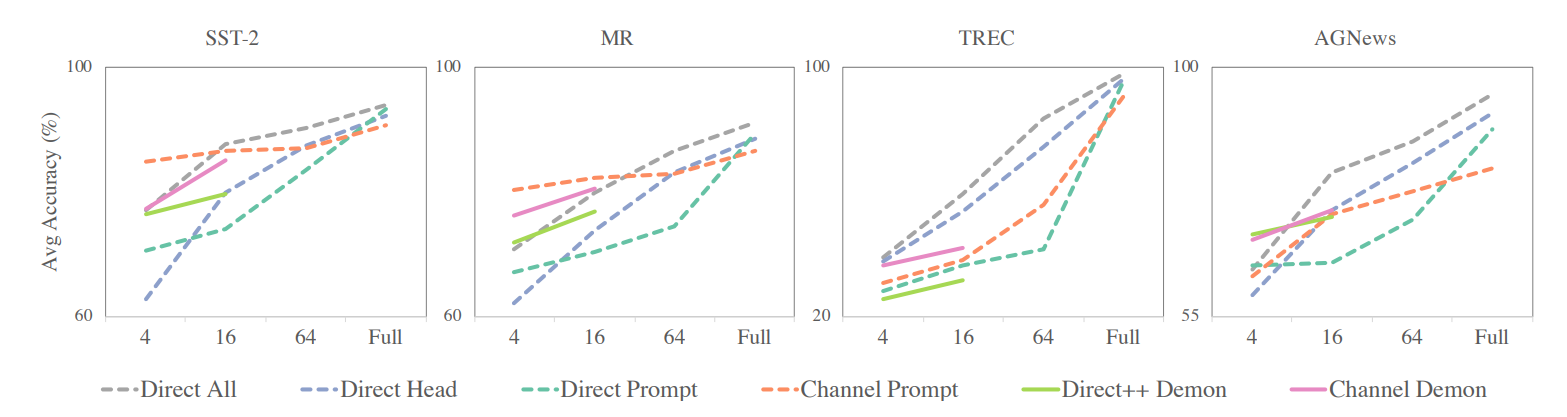
- 모든 방법이 개수에 따라 성능이 증가함
- 개수가 커짐에 따라, Channel 방식의 성능이 head tuning, direct all 방식에 밀리는 걸 확인할 수 있다. 이 점을 미루어 보아, 개수가 적을 때 Channel 이 그 소수의 예제들만으로도 충분히 능력을 끌어낸다고 볼 수 있다.
불균형 실험

- p-: 이진 분류에서 negative 를 뽑을 확률로, 데이터 불균형을 조절하는 hyperparameter 다.
- 일직선으로 그려진다는 건 관계 없이 성능이 유지된다는 것인데, channel prompt 방식이 압도적이다. 즉, channel 방식은 불균형에도 강하다.
본 적 없는 것에 대하여(unseen label)
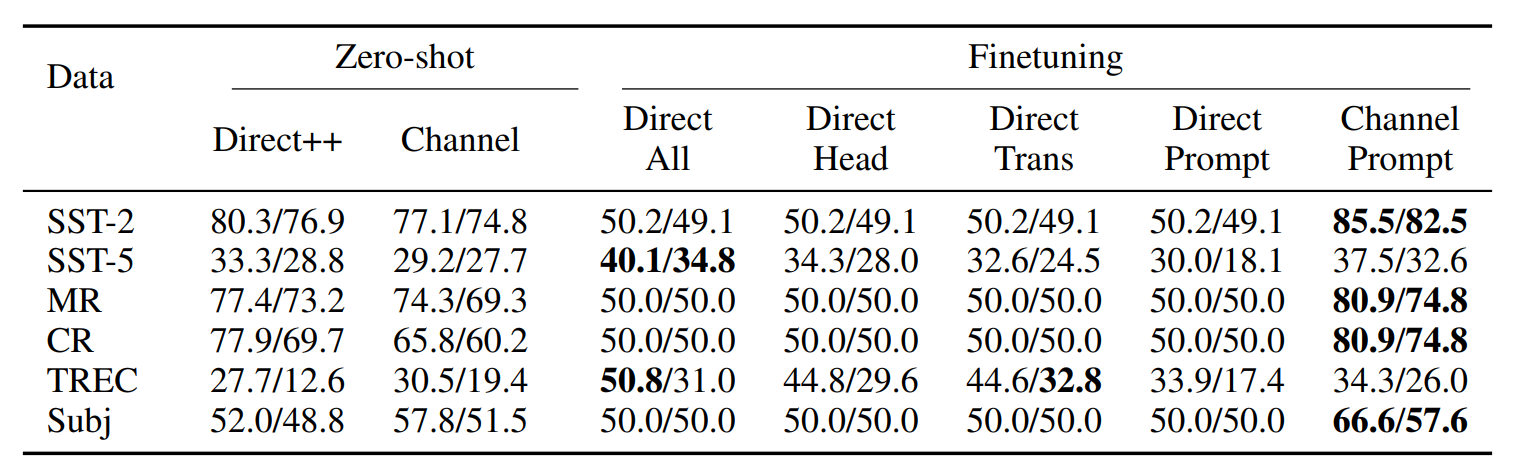

- 극단적인 설정이지만, 현실에선 충분히 일어날 수 있는 경우다.
- K개를 뽑을 때, 하나의 label 을 제외하고 뽑는다.
- direct 방식은 학습 시에 본 적이 없는 데이터를 예측할 수 없었다고 한다.
- Channel 방식은 zero shot 보다 성능이 높다고 한다. 즉, 본 적 없는 경우엔 Channel 방식이 강력함을 보여준다.
- 물론 TREC dataset 에서 성능이 좀 다른데, 이 데이터셋은 head tuning 이 가장 높았던 경우이기도 하다.
한계
- GPT2-Large 로만 했기 때문에 그 뒤에 등장한 거대 모델들에 대해선 알 수가 없다.
- text classification에 대한 결과이기 때문에 다른 태스크에 대해선 실험을 진행해봐야 한다.
'NLP > 논문이해' 카테고리의 다른 글
| [논문이해] Z-ICL: Zero-Shot In-Context Learning with Pseudo-Demonstrations (0) | 2023.07.20 |
|---|---|
| [논문이해] Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? (2) | 2023.07.20 |
| [논문이해] LARGER LANGUAGE MODELS DO IN-CONTEXT LEARNING DIFFERENTLY (0) | 2023.07.13 |
| [논문이해] A Survey on In-context Learning (0) | 2023.07.10 |
| [논문이해] Let's verify step by step (0) | 2023.06.21 |



