논문명: Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
논문 링크: https://arxiv.org/abs/2202.12837
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Large language models (LMs) are able to in-context learn -- perform a new task via inference alone by conditioning on a few input-label pairs (demonstrations) and making predictions for new inputs. However, there has been little understanding of how the mo
arxiv.org
시작하기 전에

- Demonstrations: 지시사항(번역해줘)이나 예시(16개, 32개, 2개 등 다양함)를 다 합쳐서 부르는 말
- Test Example: 결국 내가 궁금한 것. 모델이 맞춰줬으면 하는 것.
- 당연히 In Context Learning 은 저걸 다 입력에 넣는 방식이라, finetuning 처럼 parameter update가 발생하지 않는다.
발단
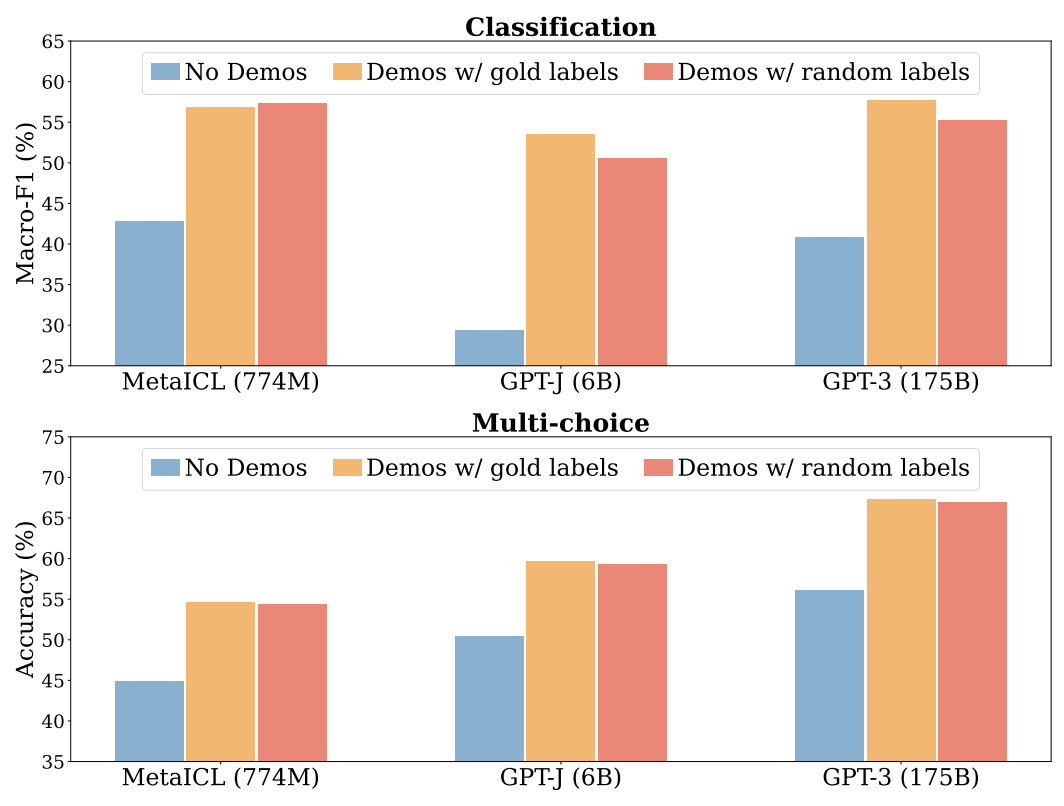
- 정답이 아닌 오답을 줘도 성능이 높네?
- 오답인 예시라도 주는 게 성능 향상에 도움이 많이 되네?
- 모델이 과연 예시를 인간이 이해하는 것처럼 받아들이는 건 맞아?
- 직관적으로는 인간에게 문제를 풀라고 할 때, 틀린 예제를 주는 것보다 차라리 아무것도 안 주는 게 더 잘 해야 하는데 모델은 반대로 하고 있어서 의아하다.
- 좋아, 실험을 제대로 해보자.
실험 설정
모델
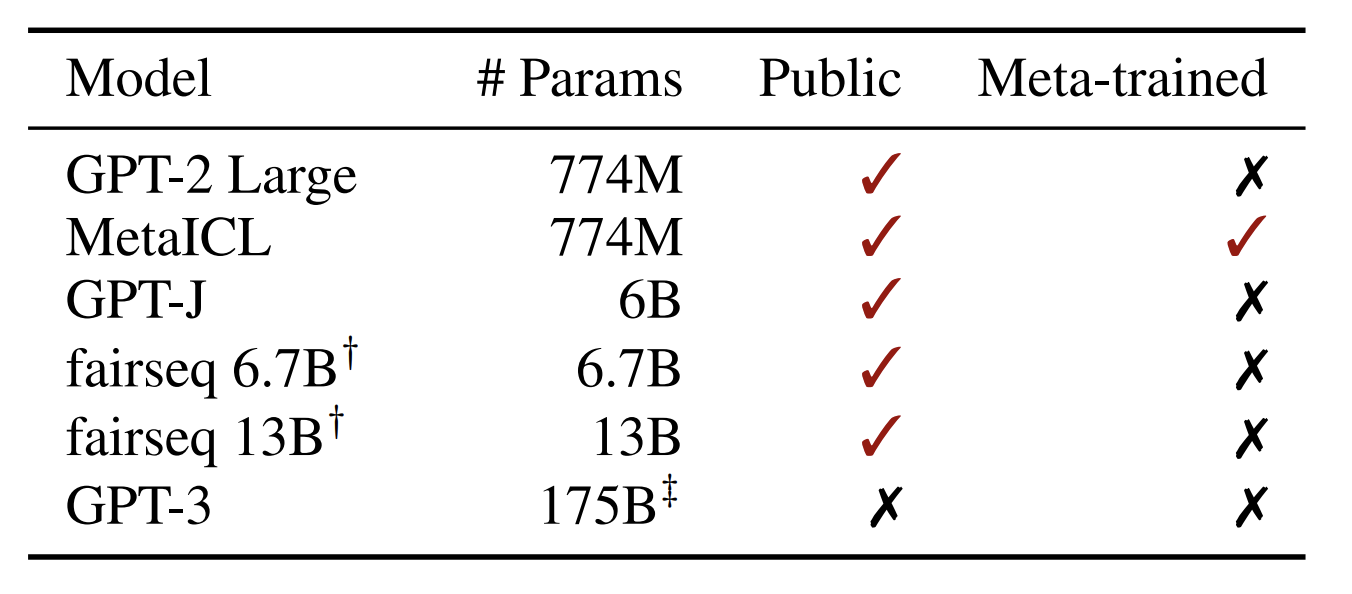
- 나머지는 대충 다 알 텐데, 모를 것 같은 것 2개만 짚겠다.
- MetaICL: 이건 GPT2 Large 랑 파라미터 개수가 똑같다. 즉, 베이스라인 모델로 사용해서 학습한 건데 In Context Learning 을 더 잘 하기 위해 Meta Learning 을 했다고 보면 된다. 그냥 In Context Learning 더 잘 하는 놈으로 봐주자.
- GPT3: API로 대화했다고 한다. Instruction tuning 이 아예 없다는 점 참고하자.
데이터셋

- 다 Classification 아니면 multi choice dataset 이다.
- 26개고 다양하게 골랐다, 이걸 평균낸다, 정도만 알자.
학습
- 예제 개수가 아무 말 없으면 16개다. (사견: In Context Learning 에 쓰이는 예제가 few shot 이라고 해놓고, 100개 넘는 것도 봤는데 few 의 개념이 나와 완전히 다른 사람들이 있는 듯)
- 예제는 학습 데이터셋에서 uniform sampling 을 통해 추출하였음
- seed 5개 평균 성능을 측정하였다고 함
- 단, 모델이 큰 13B나 GPT3는 비용과 시간 문제로, 6개 데이터셋 일부와 3개의 seed 로 측정했다고 함
평가 지표
- Macro F1 score 를 사용했다고 함
- 사견: 이 부분이 좀 아쉬움. micro / weighted / macro F1 score 를 검색해보면 알겠지만, 성능이 제대로 측정될 수 있는가에 대해 의구심이 들 수 있음. 이에 대한 아쉬움은 이 논문에서도 제시하는데, 이건 나중에 읽어보시길.
What is Channeling?
- 뒤에 실험 결과를 보다보면, direct 와 channeling 이 맞붙는다.
- channeling 은 기존 방식과 다르게 추론하는 건데, 저자가 예전에 썼던 논문을 여기에도 끌어왔다고 보면 된다.

- 원래, 입력을 넣고 정답을 추론하는 게 direct 다.
- channeling 은 정답을 넣고 입력을 생성할 확률을 구하는 걸 의미한다. Bayesian Rule 을 적용했다고 보면 된다.
- 자세한 건 여길 봐주시길 : https://heygeronimo.tistory.com/52
[논문이해] Noisy Channel Language Model Prompting for Few-Shot Text Classification
논문명: Noisy Channel Language Model Prompting for Few-Shot Text Classification https://arxiv.org/abs/2108.04106 Noisy Channel Language Model Prompting for Few-Shot Text Classification We introduce a noisy channel approach for language model prompting i
heygeronimo.tistory.com
실험1: Gold labels vs Random labels

- No demos: zero shot 이랑 같다. 그냥 바로 추론하는 것.
- 여기서 지켜봐야 하는 건, 앞에 나온 발단과 같다
- 1) random labels 를 줘도 gold labels 랑 차이가 별로 안 나네? 심지어 높은 것도 있네?
- 2) random label 을 넣는 게 아무것도 안 주는 것보다 성능이 오히려 낫네?
- 참고로 random 은 아무 단어를 넣었다는 게 아니라 정답 후보 중 무작위로 뽑았다는 ㄱ
실험1-1: 정답 비율에 따라 다르지 않을까?

- 정답비율에 따라 떨어지는 경향을 보이긴 하나, 확실한 건 no demos 가 더 낫다.
실험1-2: 개수가 영향을 미친 것은 아닐까?
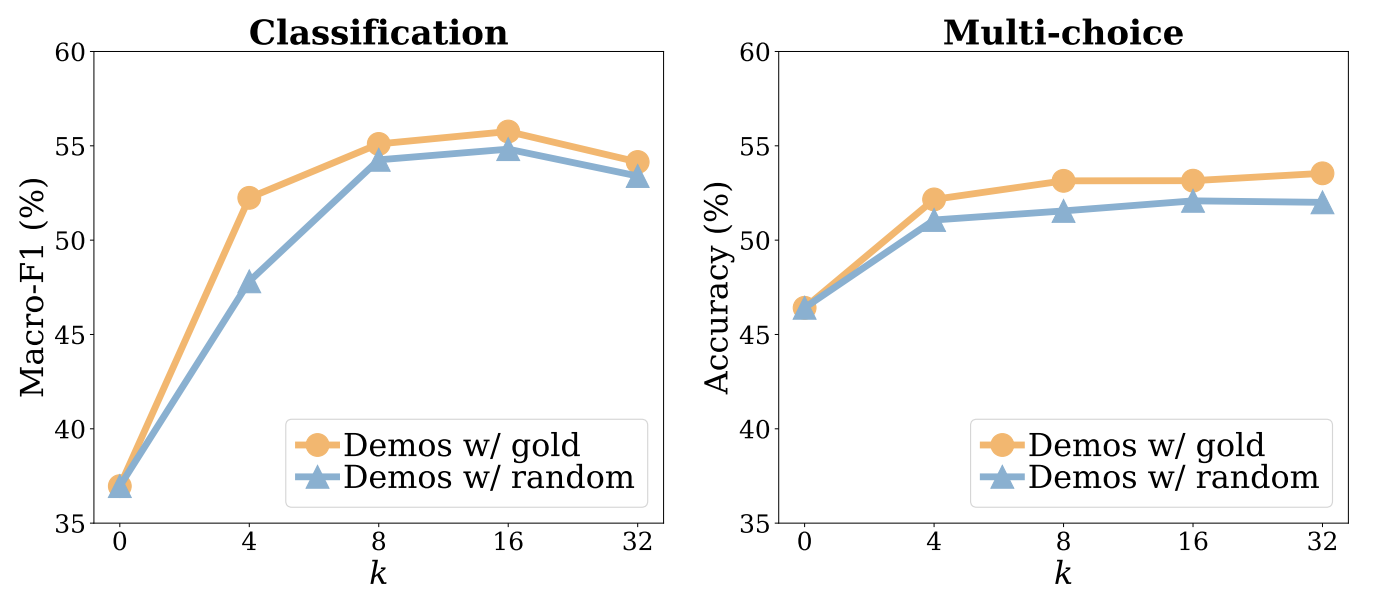
- 개수에 관계 없이 random labels도 gold labels 만큼 좋은 성능을 보여준다
- 둘다 16개 이후로는 오히려 성능이 유지되거나 감소하는 모습을 보인다
Template

- manual templates: 손수 직접 해당 데이터셋의 특성을 반영하여 만든 양식이라고 보면 된다
실험2: Template 이 영향을 미치는가

- 미미한 영향을 줬다. 데이터셋의 특성을 반영하는 것이 성능 향상을 의미하진 않는다.
사견: 이건 실험을 열심히 하셨겠지만, 잘 모르겠다. 훨씬 거대한 모델들은 민감하다는 걸 경험적으로도 많이 느낀 바가 있고, 인간이 작성하는 것도 주관적이라서 누가 작성했느냐에 따라서 달라질 수 있다. 즉, 해당 실험 결과가 유의미한 결론으로 다가오진 않는다, 적어도 나에겐.
In Context Learning 을 이루는 4가지 요소

- Distribution of inputs: 입력을 아예 데이터셋에서 벗어나 외부에서 가져와도 잘 작동할까?
- Label space: [긍정, 부정, 중립] 이외에 아예 다른 단어(사과, 비행기, 주식)을 사용해도 잘 작동할까?
- Format: 앞에서 언급한 템플릿. 어떻게 제공하는 것이 맞을까?
- Input-label mapping: (입력, 정답) 형태가 아닌 입력이나 정답만 있어도 잘 작동할까?
사견: 이 글은 논문에서 보여주는 실험 자료 흐름을 그대로 따랐는데, 중구난방이라는 느낌이 좀 든다. Channel 방식도 추가하고 싶었고, 다양한 요소들에 대한 실험도 하고 싶었던 것 같다. 확실히 해당 논문이 In Context Learning 을 어떻게 분석하는 것이 좋고, 작동 원리에 대한 시야를 넓혀준다. 다만, 너무 많은 것들이 담겨 있고, 평가 방식도 조금 아쉬워서 읽기가 수월하진 않았다. 실제로 해당 논문의 문제점을 지적하고 개선한 논문이 나왔다. 물론 이건 개인적인 견해이며, 제 실력이 낮아서 그럴 수 있습니다.
실험3: 입력의 분포를 벗어나도 되는가

- 외부에서 무작위로 문장을 추출해왔다
- 보라색: 외부에서 가져온 문장들은 성능을 확실히 떨어뜨린다
- 심지어 No demos 보다 성능이 떨어지기도 한다
실험4: 답이 분포를 벗어나도 되는가

- 정답이 [긍정, 부정, 중립]만 있는데, 사과, 비행기, 영화가 정답으로 있는 걸 말함
- 이 역시 외부에서 뽑아왔으며, Random English words 라고 부른다
- Direct: 외부에서 가져온 경우 성능이 상당히 떨어진다
- Channel: 사실 channel 방식으로 어떻게 실험했는지 와닿지 않는다. 다만 저자는 이 방식은 label에만 영향을 받지, label space 의 영향을 받지 않는다고 한다.
실험5: 양식을 지키거나 어기거나

- OOD + random labels: 오직 (입력, 답) 양식만 지킨 것. 입력도 범위를 벗어났고, 답도 무작위로 제공했기 때문이다
- Random labels only: No input
- No labels: only input
- OOD + random labels vs Random labels only: 둘 다 내용은 분포를 벗어났는데, 양식을 지켰냐 안 지켰냐의 차이만 있다. 그 결과 상당한 성능 차이가 있는 것으로 미루어 볼 때, (입력, 답) 양식을 지키는 것이 매우 중요하다는 걸 알 수 있다.
- No labels vs No demonstrations(zero shot): 아무것도 안 주는 것보다는 입력이나 답이라도 주는 게 성능 향상에 상당한 도움이 된다.
결론
- 모델은 사전 학습 때 배운 지식으로 답변을 하되, In Context Learning 에서는 domain 과 format 을 파악하는 것 같다.
- 그래서 내용/의미 상 문제가 있거나 다소 상식에 어긋나는 예제를 제공하더라도 성능이 오르는 것으로 추정된다.



