논문명: Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations
논문링크: https://arxiv.org/abs/2205.12685
Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations
Despite recent explosion of interests in in-context learning, the underlying mechanism and the precise impact of the quality of demonstrations remain elusive. Intuitively, ground-truth labels should have as much impact in in-context learning (ICL) as super
arxiv.org
논문을 읽기 전에
- 본 논문은 이 논문에 대한 반박과 함께 개선을 시도한 논문이니, 이것부터 읽어볼 필요가 있다
사견: 같은 한국인끼리 논리적인 대화를 논문으로 주고 받는 것 같아서 연구자의 자세에 대해서도 돌아보게 되었다.
기존 연구의 문제점 지적
최근 In Context Learning 분야에서 Demonstrations 에 예제가 정답이 아니여도 크게 상관 없다는 논문이 나왔다. 그러나 해당 논문에는 크게 3가지 문제가 있었다.
1. 실험환경을 바꾸면 결과가 다르게 나온다

- 본 논문의 저자가 다른 데이터셋이나 모델을 사용했을 때 비슷한 결론이 나지 않기도 했다.
- 위 그림은 정답을 제대로 준 예제와 무작위로 준 예제의 비율을 의미한다. 100%에 가까울수록 제공된 모든 예제가 올바른 답과 함께 입력되었음을 의미한다.
- 과거 논문에서는 0%나 100%나 큰 차이가 없었다. 그러나 본 논문에서 실험해본 결과, 정답 비율이 낮아질수록 성능이 확연히 낮아지는 모습을 볼 수 있다.
2. 그 논문에서 사용한 metric 은 지나치게 일반화한다
- macro F1 score 자체도 일반화 경향이 심한 지표인데, 이 지표를 사용하여 여러 개 데이터셋 성능의 평균을 제시하니 정확한 결론을 내리기 어려웠다. 예컨대, A반의 토익 점수가 990, 990, 10, 10점인데 평균 500점으로 중위권이라고 결론 짓는 건 이상하지 않은가. 즉, 평균과 분산을 함께 제시했을 때 이러한 경향이 일반적인지 혹은 경우마다 다른지 정확히 알 수 있다는 것이다.
- 그리고 실험이나 지표가 해당 결론을 지지하기엔 불충분하다고 밝힌다.
3. 있나없나가 아니라 얼마나에 대하여
- 그런 경향이 있다 없다에 관해서만 결론을 내리는 걸로는 불충분하며, 경향이 있다면 어느 정도 있는지를 측정할 필요가 있다고 본 논문에선 이야기한다.
본 논문은 다음 세 가지를 기여한다
- 최근 In Context Learning(이하 'ICL')에서 발견된 현상 중 하나인 'input label mapping 과 성능이 서로 연관이 크게 없다'는 점을 다시 짚고자 한다.
- ICL에서 ground truth label 이 미치는 영향을 보다 정확히 측정할 수 있는 지표 2개 'sensitivity' 와 'GLER' 을 제시한다.
- ICL의 다양한 요소가 모델에 미치는 영향을 분석하여 향후에도 응용할 수 있도록 한다.
측정 지표
Label-Correctness Sensitivity

- s: 예제가 정답인 비율
- y: 성능 지표 (accuracy, f1 score)
- 이때 선형 회귀로 구했을 때의 기울기를 sensitivity 로서 얼마나 정답 비율에 대해 성능이 민감하게 반응하는가를 측정함
Ground-Truth Label Effect Ratio (GLER)

- GT: 올바른 답을 예제로 제공했을 때의 성능
- RL: random label, 즉 무작위로 답을 제공했을 때의 성능
- 0: zero shot 성능
- 위 식을 통해 구한 지표로, 정답에 얼마나 예민한가를 가늠해볼 수 있다
- GLER 이 높다 → zero shot 보다 Random Label 성능이 낮다 → 오히려 오답인 label 을 주는 게 성능 하락을 불러일으킨다 → 즉, label 에 민감하다
- GLER이 낮다 → zero shot 보다 Random Label 성능이 높다 → label 에 정답 유무에 상관없이 성능이 오른다 → label 에 둔감하다
실험1: 정답의 올바름이 성능에 영향을 미친다

- R^2: 1에 가까울수록 양의 상관관계가 높다는 말이다. 즉, 정답 비율이 높을수록 성능이 올라간다.
- Coefficient: 올라가는 양을 의미한다. 정답 비율이 1% 증가하면, 평균 성능 0.3%가 오른다고 보면 된다.
- 즉, 정답 비율과 성능이 실제로는 관련이 있음을 보여준다
실험2: 개별적으로 보면 평균 경향이 없다
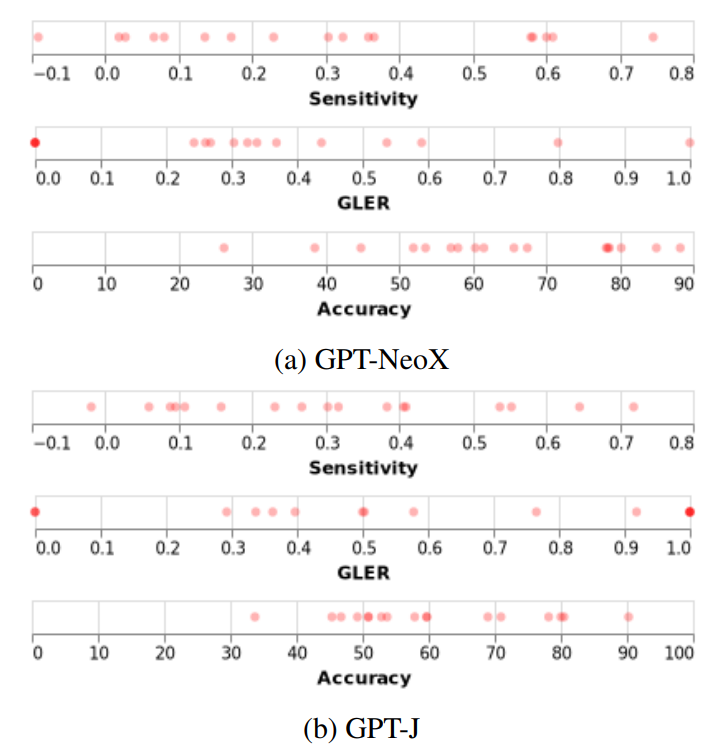
- 데이터셋마다 측정한 sensitivity와 GLER, Accuracy 를 보면 천차만별이라는 게 눈에 띈다.
- 특히 sensitivity가 음수인 데이터셋은 정답 비율을 내려야 성능이 오른다는 의미다.
- 대체로 양끝에 점이 찍힌 걸로 볼 때, 데이터셋마다 편차가 심하다. 즉, 평균을 내서 결론을 도출하기엔 표준편차를 고려하지 않았으므로 적어도 지금 상황에서는 어떤 경향에 대해 이야기하기 어렵다.
사견: 이건 훌륭한 지적이라고 생각한다. 경향이 이렇게 다양한데, 평균으로 결론을 내리려고 했다는 시도가 참 아쉽다. 비판당한 논문이 후속논문을 더 내는 것으로 알고 있는데, 그 논문들에선 평균적인 성능뿐만 아니라 표준편차에 대한 고려가 함께 있으면 좋겠다.
실험3: 난이도와 sensitivity 는 관련이 있다

- 난이도(difficulty) 정의: Ground truth 사용한 성능 - zero shot 성능
- 난이도가 높을수록 ICL 성능이 높을 것이다라고 추측한 이유는 예제를 통해서 더 많이 배우려고 할 것이기 때문이다.
- 결론: 기존 성능에 비해 ICL 성능이 높을 수록 난이도가 높다는 것이고, 그럴 수록 정답 비율에 예민하다
그렇다면, 언제 민감도가 증가하고 감소할까?
- 이걸 잘 활용하려면, 다양한 상황과 설정에 따라 어떻게 달라지는지에 대해 실험할 필요가 있다.
실험4: Channel vs Direct
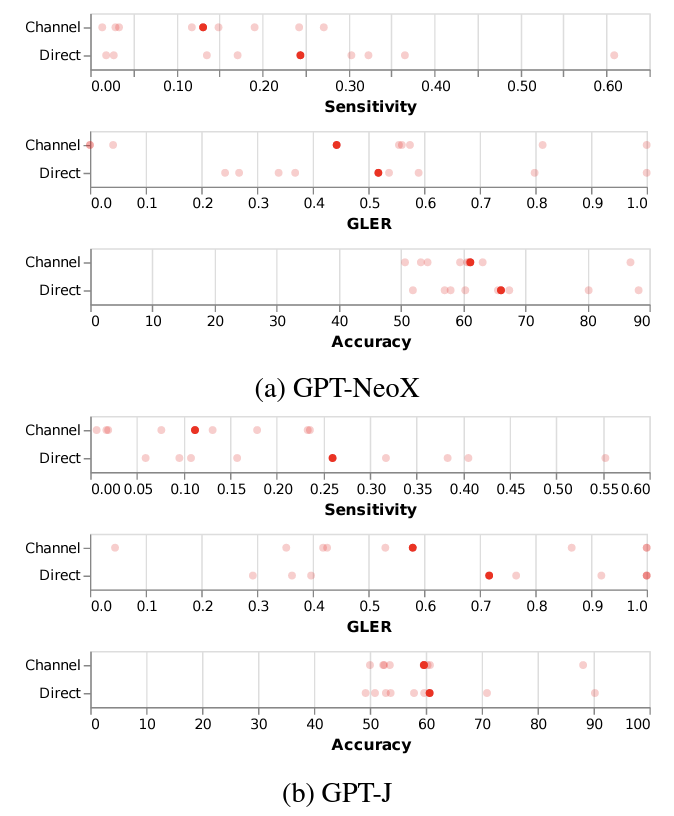
- Channel: Sensitivity 와 GLER 가 전체적으로 감소하면서 성능이 유지된다.
- 해당 방법론은 insensitivity 를 증가시킨다.
실험5: CBU vs Direct

- CBU는 이 논문의 Direct++ 와 같은 방법론이니 읽어보길 권한다.
- CBU 역시 Channel 처럼 insensitivity 를 증가시키면서 성능은 유지한다.
실험5: K & prompt template verbosity
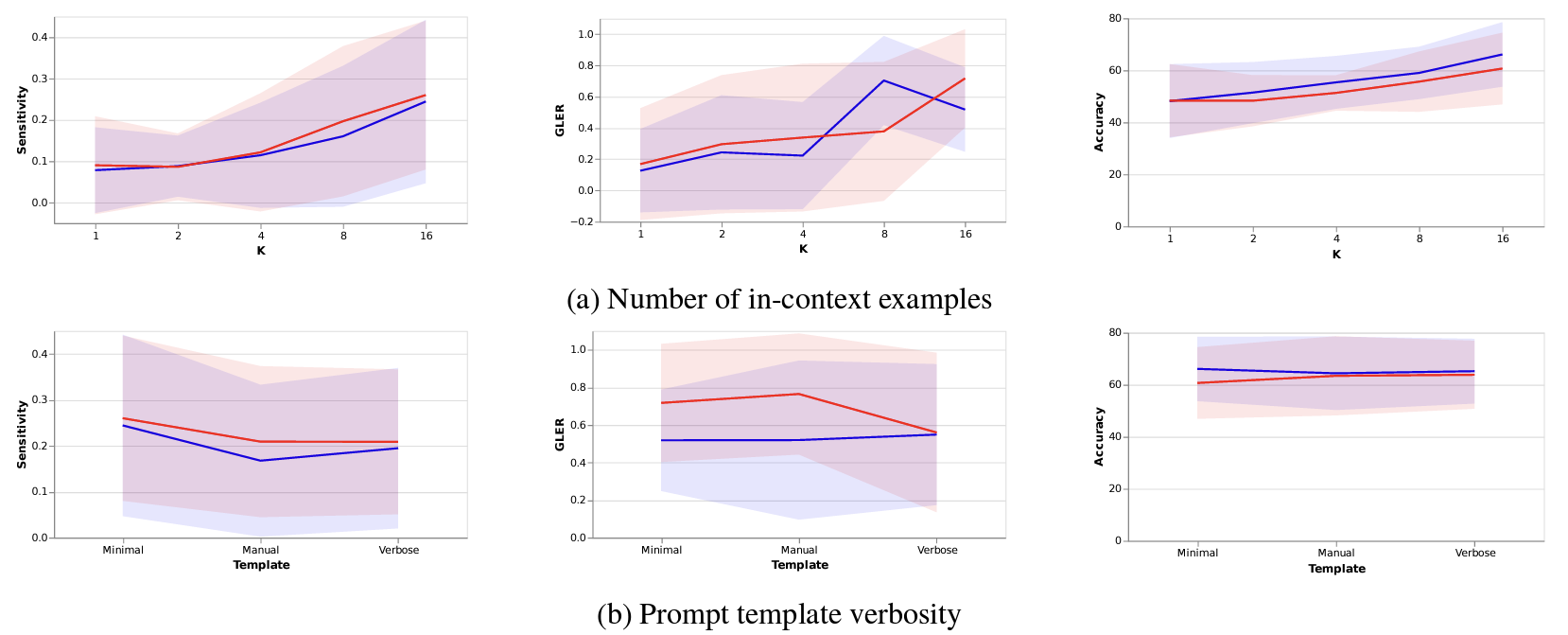
- 예제 개수가 증가함에 따라 모든 지표가 올라간다. 이건 이미 알려진대로다.
- template 양식은 크게 연관이 있지 않은 것으로 보인다.

- 모델 크기가 커질수록 다 증가한다
- 예제로부터 더욱 많은 정보를 얻을 수 있고, 학습할 수 있는 것으로 보인다
- 모델 크기가 커짐에 따라 ICL 능력이 향상된다
- 다만, Sensitivity 와 GLER 은 중간에 꺾이는 것으로 볼 때 마냥 예제에 의존하지 않고 사전학습된 지식 역시 잘 활용하는 것으로 보인다



