
논문명: Generating Equation by Utilizing Operators : GEO Model
한글 논문 링크: https://s-space.snu.ac.kr/handle/10371/175890#export_btn
영어 논문 링크: https://aclanthology.org/2020.coling-main.38.pdf
SNU Open Repository and Archive: 템플릿 기반의 방법을 이용한 문장형 수학 문제 풀이
템플릿 기반의 방법을 이용한 문장형 수학 문제 풀이 Automatically solving math word problem using template-based methods Issue Date 2021-02 Publisher 서울대학교 대학원 Keywords 자연어 이해 ; natural language understanding ;
s-space.snu.ac.kr
논문을 정리하기 전
- 한글로 된 논문이라 Math Word Problem 에 대해 이해하기 쉬운 논문이라 입문용으로 추천한다. 특히, 2장에서 적힌 MWP 분야의 관련 연구에 대한 내용은 기초지식을 쌓기에 적절하고, 3장에 적힌 실험과 2개의 모델에 대한 설명은 기존 논문에 버금갈 정도로 그림과 함께 상세히 설명을 해주셨다.
- 단, 한글로 되어 있어서 쉽다는 것이지 내용이나 수준은 높은 편이다. 특히 모델을 제시하는 4장부터는 이해가 다소 어려운 부분들이 많다. 또, 궁금하면 영어 논문도 있다. 한글 논문은 매우 긴데 반해, 영어 논문을 짧다. 잘 선택하는 게 좋다.
- 이 논문은 처음에(3장에서) 실험 결과를 보여주고, 그 결과를 바탕으로 모델을 제시하고 실험한다는 점을 알면 좋다. 즉, 모델 구조만 궁금하다면, 중간부터 보면 된다.
요약
기계학습 모델의 문제풀이 정답률을 높이기 위해서는 3가지 문제가 해결될 필요가 있다.
- 1. 모델이 올바른 정답식을 도출할 수 있어야 한다.
- 2. 모델이 내포된 숫자와 변수의 관계를 이해할 수있어야 한다.
- 3. 모델이 문제를 이해하는데 필요한 세계지식을 이용하여 문제 내에 생략된 정보를 파악해야 한다.
논문에선 3가지 문제를 해결하기 위해 다음을 제시한다.
- 템플릿 기반의 다중 작업분류 모델(Template-based Multi-task classification)
- 템플릿기반의 다중 작업 생성 모델(Template-based Multi-task generation)
- 연산자 활용 기반의 생성(Generating Equation by Utilizing Operators:GEO) 모델
문제와 해결책을 연관지으면, 다음과 같다.
- 첫 번째 문제를 해결하기 위해, 필자는 2개의 서로 다른 정답 식도출 방법인 정답 식 분류(equation classification)와 정답 식생성(equation generation)방법을 비교한다.
- 두 번째 문제를 해결하기 위해, 숫자와 변수사이의 관계를 이해하는 operator identification layer과 two auxiliary tasks/operation feature feed forward layer 를 제안할 것이다.
- 마지막으로, 세 번째 문제를 해결하기 위해 BERT와 ELECTRA와 같은 언어 모델(language model)을 사용할 것이다.
본 연구의 최종 모델인 GEO 는 다음과 같은 성적을 거두었다. (논문은 21.01 기준이다)
- MAWPS에서 85.1, Math23K에서 84.4, DRAW-1K에서 62.5로 최고성능을 기록함.
- ALG514에서 82.1로 hand-crafted feature 를 사용한 선행연구와 대등한 수준의 결과를 얻음.
용어 정리
- 정답식: 정답을 구할 때 쓰이는 결정적인 식
- 템플릿: 정답식의 숫자를 변수화/정형화(normalized)한 형태. 이걸 하는 이유는 템플릿의 유형을 줄이기 위해서다. 예컨대, 아래 그림과 같은 정답식(X = 12 + 34)은 흔치 않아도 템플릿(X = N0 + N1)은 많다.
- 정답: 질문에 대한 답

실험
: 일반적인 논문의 형식과 다르게 실험을 먼저 제시한다. 순서는 다음과 같다.
- 실험목적: 왜 이 실험을 하는가?
- Input normalization: 실험에 쓰이는 데이터 형식
- 비교대상: 실험에 쓰이는 classification 과 generation 모델 소개
실험 목적
- 템플릿을 통해 MWP 에서 도출가능한 식의 개수가 현저히 줄어들었다.
- 이렇게 줄어든 템플릿을 도출하는 방식은 크게 분류(classification)와 생성(generation)이 있다.
- 그런데, 아직까지 동일한 데이터셋을 기준으로 2개의 방식을 비교 및 분석한 연구가 없었다.
Input normalization
: 해당 실험을 위해 input 을 전처리할 필요가 있다.
용어 정리
- INC (Index for numeric constants): 숫자/상수를 색인(index)를 가진 변수로 치환한 것
- NET (Normalized equation template): equation template 을 일반화한 것
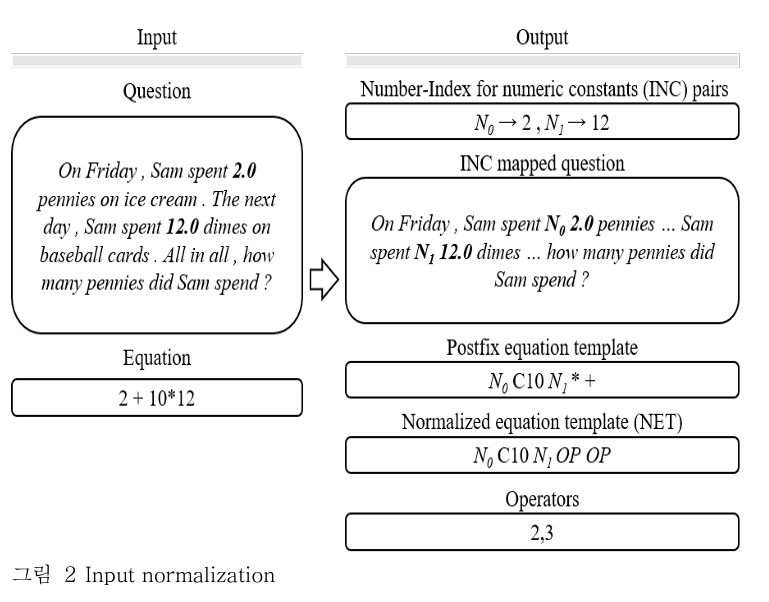
과정
ㄱ. INC 생성
- question 에 존재하는 number 가 존재하면, 모두 그에 상응하는 INC 를 pairing 한다.
- 이때, 대문자 'N'을 사용하되, 등장하는 순서대로 index 를 할당한다.
ㄴ. postfix equation template 생성
- equation 을 postfix 형태로 변경한다.
- 숫자 대신 INC 로 치환한다.
- 이는 TM-generation 이나 TM-classification 의 최종 결과값이다.
ㄷ. NET 생성
- postfix equation template 에서 연산자를 OP token 으로 치환한다.
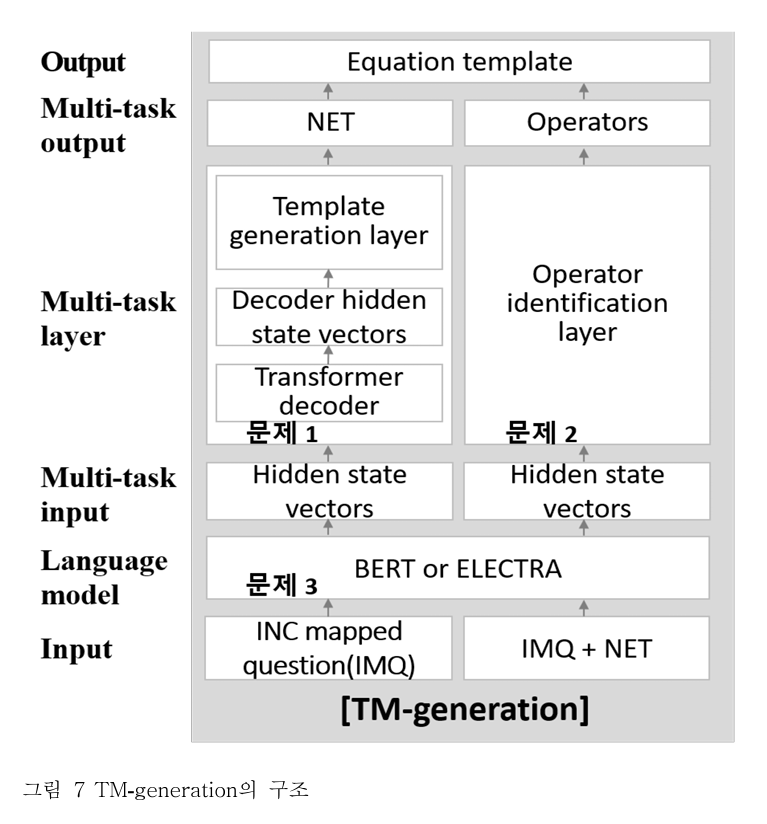
비교대상1 - Model: TM-classification

위 그림에서 나타나는 문제들은 다음과 같다.
- 문제1. 모델이 올바른 정답식을 도출할 수 있어야 한다.
- 문제2. 모델이 내포된 숫자와 변수의 관계를 이해할 수 있어야 한다.
- 문제3. 모델이 문제를 이해하는데 필요한 세계지식을 이용하여 문제 내에 생략된 정보를 파악해야 한다.
이 문제를 어떻게 해결하는지 아래 그림들로 자세히 설명하고자 한다.
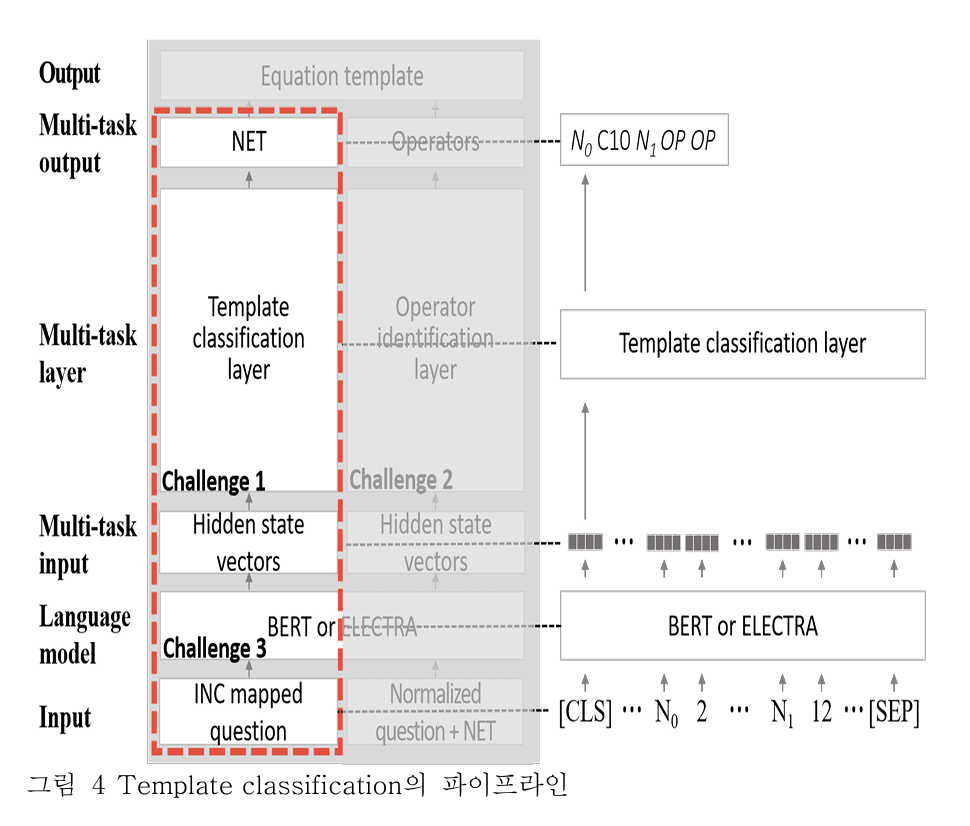
문제3. 모델이 문제를 이해하는데 필요한 세계지식을 이용하여 문제 내에 생략된 정보를 파악해야 한다.
해결책
- BERT, ELECTRA 와 같은 사전학습된 언어 모델을 통해 세계지식을 넣는다.
방식
- 입력으로 INC mapped question 을 사용한다.
- 이후 생성된 hidden state vector 중 [CLS] 토큰만 Template classification layer 에 넣는다.
- 여기서 [CLS] 토큰만 쓰이는 이유는 선행연구에서 문장 전체의 의미를 담을 수 있는 토큰으로 제안되었기 때문이다.
문제1. 모델이 올바른 정답식을 도출할 수 있어야 한다.
해결책
- Template classification layer 를 통과하여 가장 가까운 템플릿을 도출한다.
방식
- 입력으로 [CLS] 토큰을 사용한다. 그 이유는 문제3의 방식에 작성되어 있다.
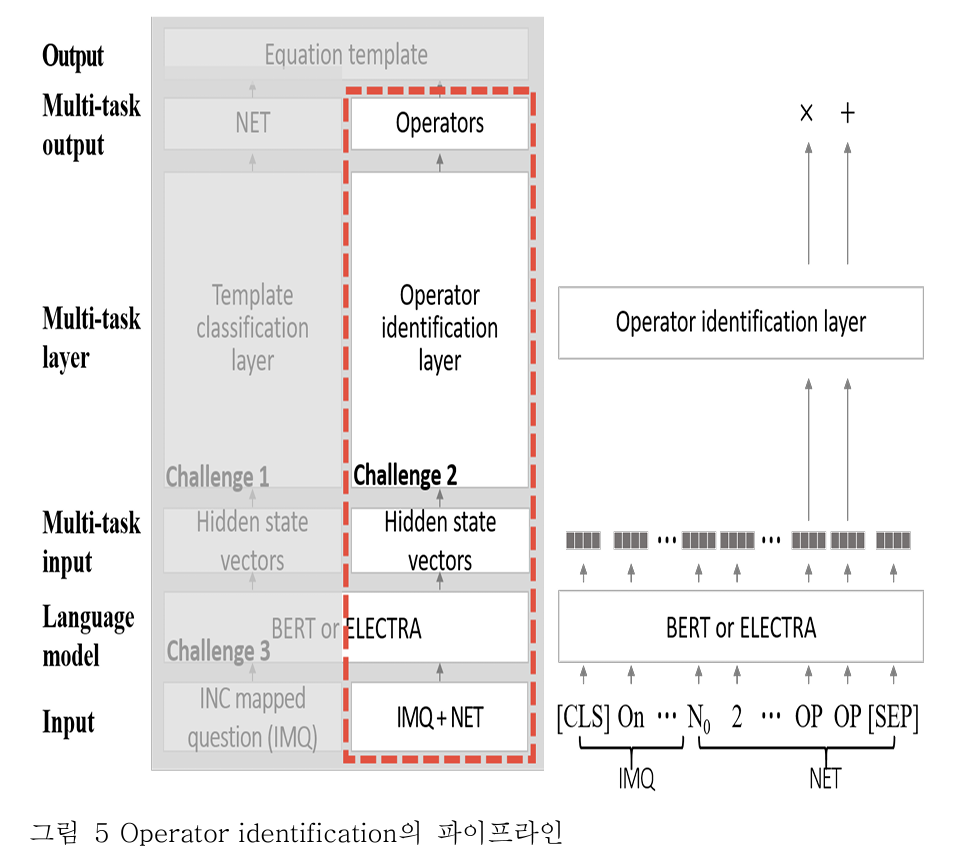
문제2. 모델이 내포된 숫자와 변수의 관계를 이해할 수 있어야 한다.
해결책
- Operation identification layer 를 통과하여 가장 가까운 연산자를 도출한다.
방식
- 입력으로 IMQ + NET 를 사용한다.
- BERT or ELECTRA 와 같은 사전학습된 언어 모델을 통해 임베딩한다.
- hidden state vector 중 OP 토큰만 사용하여 operation identification layer 에 넣는다.
- operator 를 생성한다.
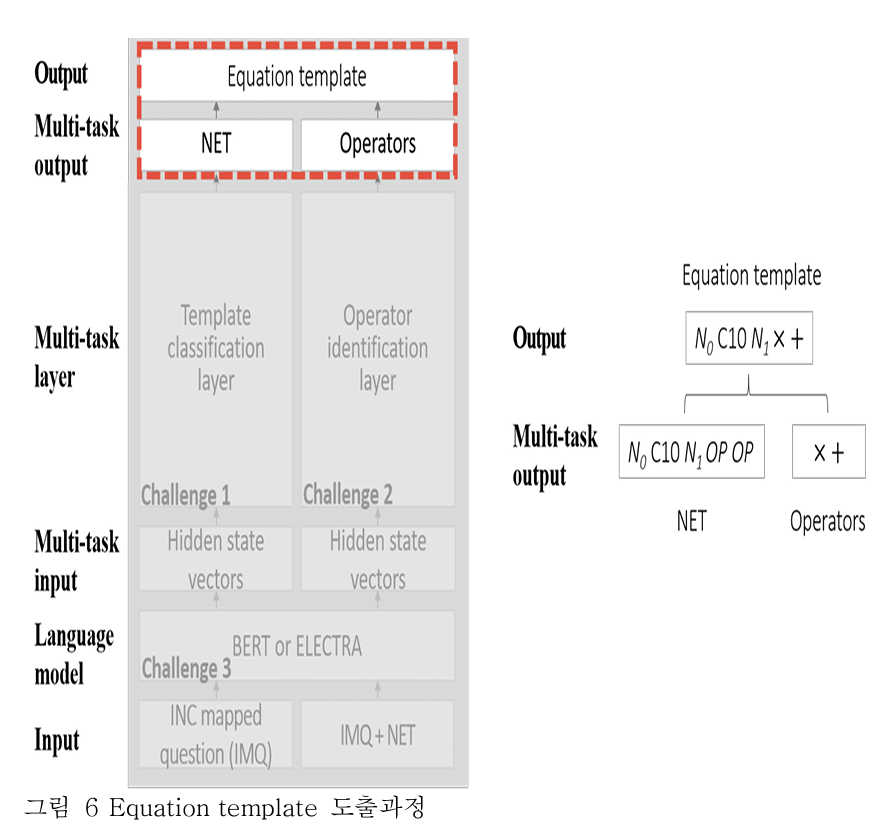
마지막으로 NET 와 Operators 를 치환하여 합친다. 최종 output 으로 정답식을 도출한다.
비교대상2 - Model: TM-generation
위 과정을 분류(classification)이 아닌, 생성(generation)으로 해결하고자 한다.
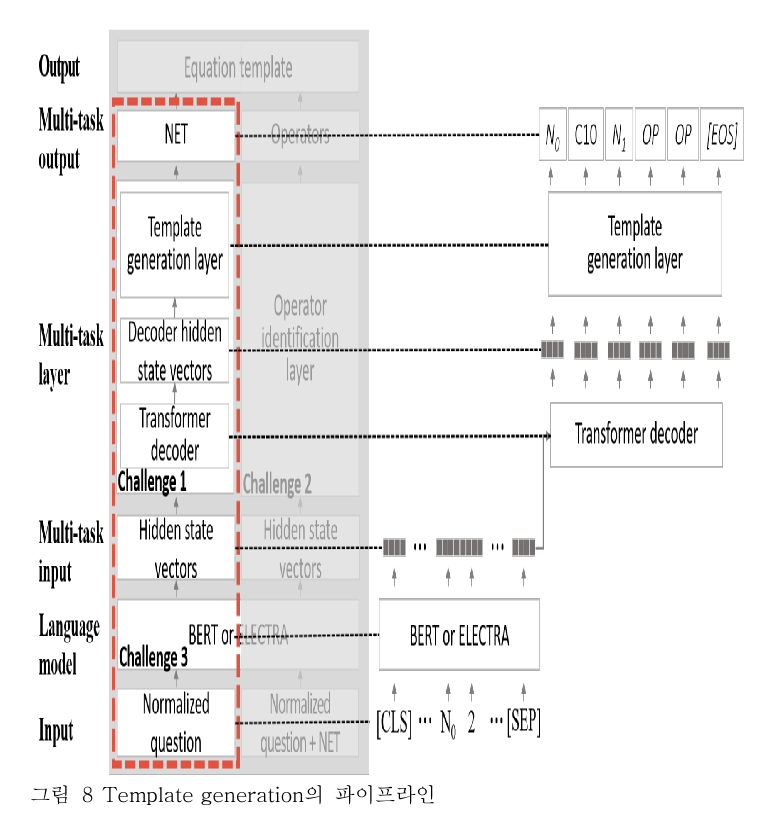
문제3. 모델이 문제를 이해하는데 필요한 세계지식을 이용하여 문제 내에 생략된 정보를 파악해야 한다.
해결책
- BERT, ELECTRA 와 같은 사전학습된 언어 모델을 통해 세계지식을 넣는다.
방식
- 입력으로 INC mapped question 을 사용한다.
- 이후 생성된 hidden state vector 중 [CLS] 토큰만 Template classification layer 에 넣는다.
- 여기서 [CLS] 토큰만 쓰이는 이유는 선행연구에서 문장 전체의 의미를 담을 수 있는 토큰으로 제안되었기 때문이다.
문제1. 모델이 올바른 정답식을 도출할 수 있어야 한다.
해결책
- Multi-task layer 를 통과하여 가장 가까운 템플릿을 도출한다.
방식
- Multi-task layer 는 Transformer decoder 와 Template generation layer 를 합친 걸 의미한다.
- 먼저 Transformer decoder 에서 hidden state vector 를 생성한다.
- hidden state vector 를 template generation layer 에 넣는다.
문제2를 해결하는 방식은 'TM-classification' 과 동일하다. 당연히 동일해야 실험을 할 수 있고, 비교가 의미가 있다.
실험 계획
실험 데이터

복잡도
템플릿을 구성하는 평균 토큰수가 높을 수록 문제가 복잡하다. 심지어 평균 토큰수가 템플릿당 문제 수가 적다면, 모델은 적은 데이터를 통해서 학습해야 하므로 난이도가 높다고 볼 수 있다. 그런 점에서 아래와 같은 분류가 가능하다.
- 복잡도가 낮다 → MAWPS, Math23k
- 복잡도가 높다 → ALG514, DRAW-1K
그래서 순수한 신경망 모델들은 MAWPS, math23k 와 같은 데이터를 선호할 수 밖에 없었다. (실제로 MWP 분야 논문을 몇 개 훑어본 사람으로서, ALG514, DRAW-1K 는 처음 들어봤다.). 하지만 본 논문에서는 그럼에도 불구하고 개선점을 찾기 위해 사용하기로 했다고 밝힌다.
(실험에 대한 상세한 설정에 대해선 생략하겠다. 논문에 도표로 자세히 설명되어 있으니, 참고바란다.)
실험 결과
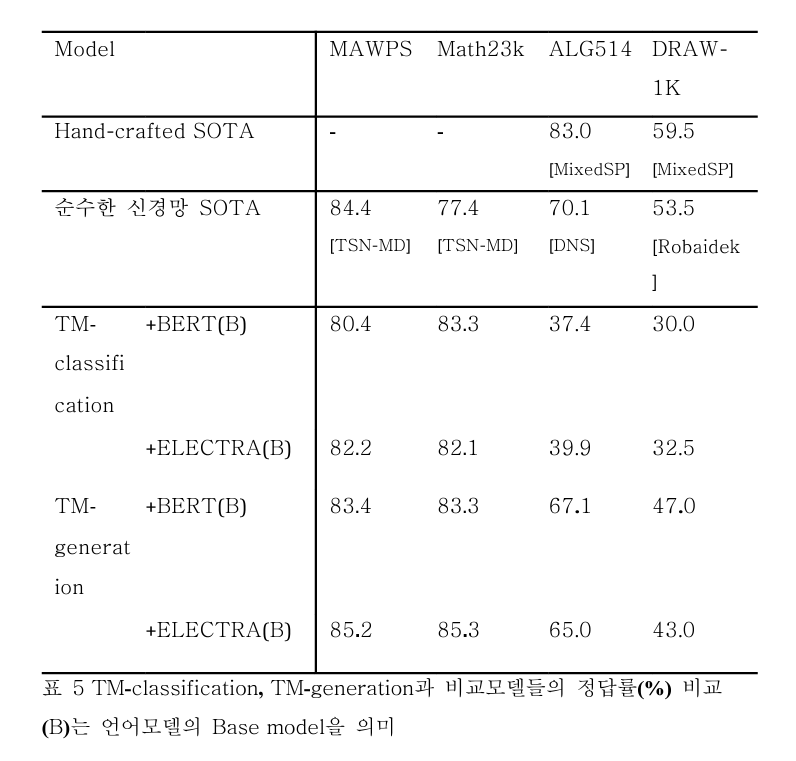
모델 설명
- Hand-crafted SOTA: hand-crafted feature 방식으로 된 논문 중 최고 성능을 가져왔다. 복잡도가 높은 데이터셋(ALG514, DRAW-1K)의 성능을 비교하기 위함이다.
- 순수한 신경망 SOTA: 순수 신경망에서 SOTA 를 찍은 모델들의 성능을 가져왔다. 자세한 모델명은 수치 아래 '[model_name]' 형식으로 적혀있다.
- TM-classification, TM-generation: '분류냐, 생성이냐'를 비교하기 위해 쓰였다. 여기서 pretrained Language Model 로 BERT, ELECTRA 모두 사용해본다.
결과 분석
- TM-generation with ELECTRA 는 MAWPS, math23k 에서 뛰어난 성능을 보였다.
- 하지만 복잡도가 높은 데이터셋에서는 낮은 정확도를 보였다.
- 위를 개선하기 위해, MAWPS와 math23k 를 기반으로 ablation study 를 진행하고자 한다.
Ablation study
1. 올바른 정답식 도출
- 8개 실험 중 7개에서 생성(generation) 방법이 더 좋았음.
- 이러한 결과는 모델의 정답 식 도출과정에서 '탐색 범위가 넓지만 학습난이도가 높은 생성 방법'이 '탐색 범위는 좁지만 학습 난이도가 낮은 분류 방법'에 비해 효과적이기 때문인 것으로 판단됨.
→ 그러므로, 생성 모델을 사용하겠다.

2. 숫자와 변수 사이의 관계 이해
- 실험 결과, 분류 생성 모두 operation identification 과정의 효과를 검증하였다.

3. 세계 지식을 이용하여 생략된 정보를 파악하는 것
- BERT, ELECTRA 를 사용하지 않았을 때가 모두 성능이 낮다.
- 이를 미루어 보아, 사전학습 언어 모델을 통해 세계 지식을 습득하는 것으로 보인다.
결론
- 위 3가지 모두 MAWPS, math23k 에선 우수한 성능을 보임.
- 하지만, 복잡도가 높은 ALG514, DRAW-1K 에선 Hand-crafted SOTA 에 비해 성능이 떨어짐.
- 이는, 숫자와 변수 사이의 관계를 추출하는 과정인 operation identification 에 개선의 여지가 있다고 볼 수 있음.
- 숫자의 양적 정보를 활용한 MixedSP 가 최고 성능을 기록하는 걸로 보아, 필자는 2가지 요소를 추가하여 새로운 모델을 제시하였음.
GEO: Generating equations by utilizing operators
: TM-generation 의 변형 모델
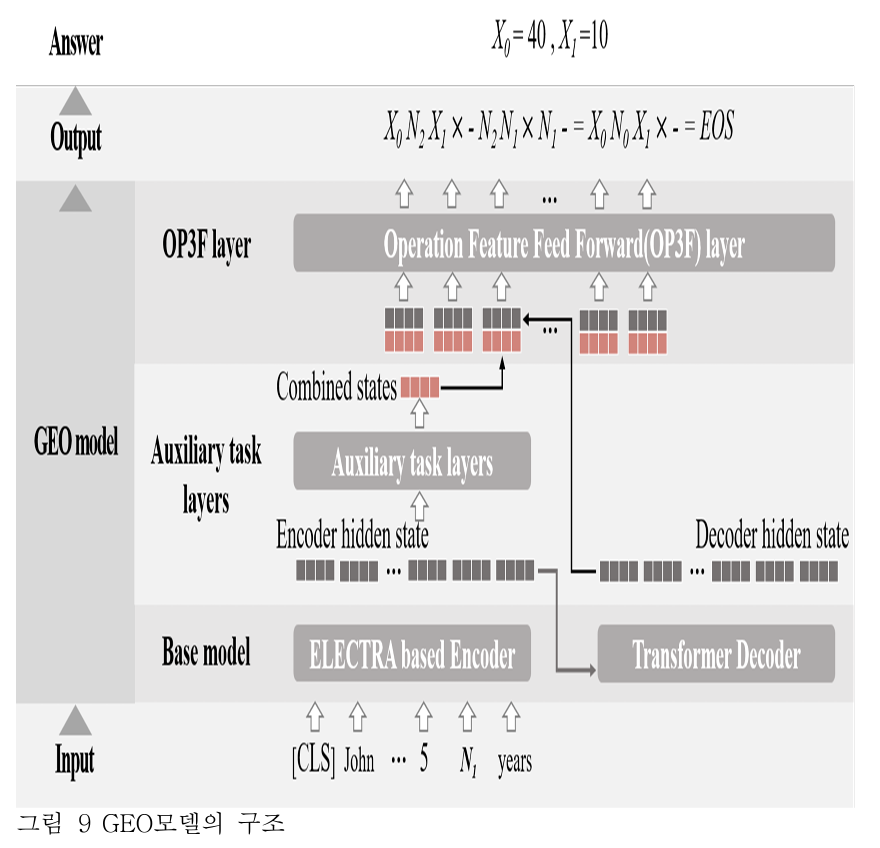
1. Auxiliary(보조의) task layers
- 설계 목적: 알고리즘이 추가로 문제에 내포된 숫자와 변수 관계를 추출할 수 있기를 기대한다.
- 기능: encoder 의 output 을 입력으로 받아 combined states 를 출력한다.
2. OP3F layer: Operation Feature Feed Forward layer
- 설계 목적: 숫자와 변수 관계를 encoder 에서 손실 없이 decoder 에서 활용할 수 있도록 하였다.
데이터 전처리
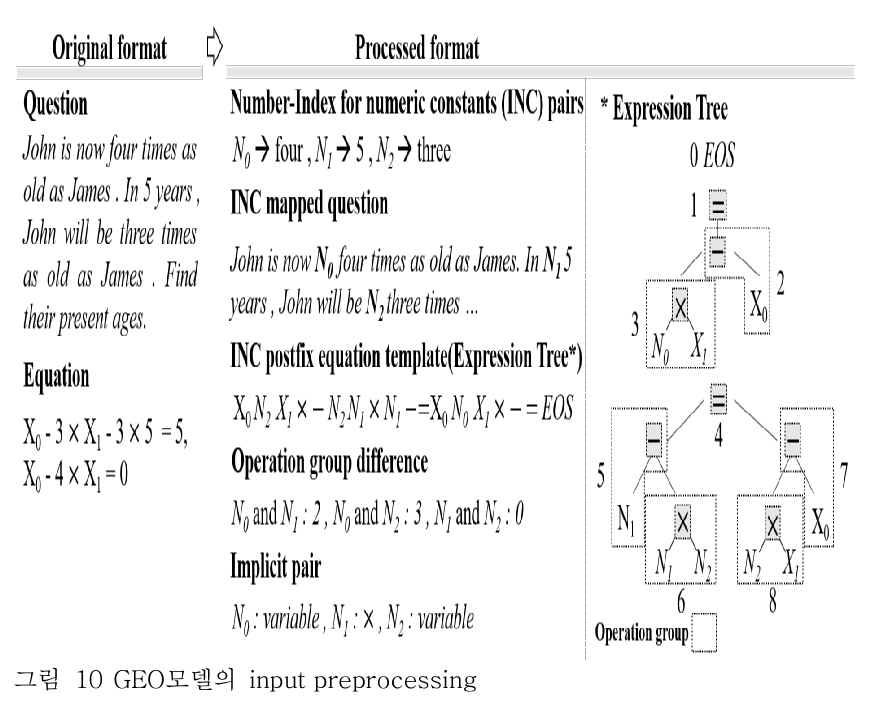
(Number-INC pairs와 INC mapped question, INC postfix equation 은 앞에서 이미 정리해서 생략함)
문제 해석 (개인적으로 Expression Tree 를 설명하기 위해 어려운 문제를 가져온 것 같다)
- John 은 현재 James 나이의 딱 4배다.
- 5년 뒤엔, 3배가 된다고 한다.
- 이때, 그들의 나이는 몇 살일까?
기호
- John 나이 = X0
- James 나이 = X1
- N0 = four, N1 = 5, N2 = three (문제에서 숫자가 나온 순서대로 변경함)
Equation
- X0 - 3 * X1 - 3 * 5= 5,
- X0 - 4 * X1 = 0
Equation Template
- X0 - N2 * X1 - N2 * N1 = N1
- X0 - N0 * X1 = 0
INC postfix equation template (Equation Tree)
(사실 이 부분에 대한 설명이 갑작스러울 정도로 불친절하다. 논문에서 이 부분을 만들어나가는 과정이 많이 생략되었다. 내가 예시를 정리하고 분석한 결과, 다음과 같은 방식으로 진행된 것이 아닌가 추측해본다. )
- 1. Equation Template의 좌변을 0 으로 두고, 우변으로 모두 옮긴다.
- 2. 이때, 좌변의 항들은 최우측부터 하나씩 옮긴다.
- 3. 그 후, 첫번째 식의 우변 = 두번째 식의 우변 = <EOS> 와 같이 변형한다.
[1, 2번 후 결과]
- 0 = N1 - N2 * N1 + N2 * X1 - X0
- 0 = N0 * X1 - X0
[3번 후 결과]
- 후위 표기법 변경 전: N1 - N2 * N1 + N2 * X1 - X0 = N0 * X1 - X0 = 0
- 후위 표기법 변경 후: N1 N2 N1 * - N2 X1 * X0 - += N0 X1 * X0 - = 0
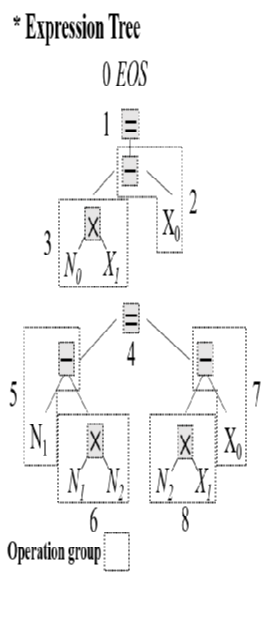
(그러면 예시에 있는 트리 구조와 얼추 맞다. 그런데 위에 빨갛게 칠해놓은 연산자는 왜 없는지 모르겠다. 물론 내가 틀렸을 수도 있지만, 그러기엔 논문에 '손실업이' 와 같은 오타가 있어서 혹시나 하는 마음에 의혹을 제기해본다.)
Operation difference

- INC postfix equation template 의 최우측부터 Expression Tree 를 만들어간다.
- 이때 연산자가 등장할 때마다 번호를 매긴다. EOS token 부터 0으로 시작한다.
- 피연산자의 번호는 연산자의 번호를 따라간다.
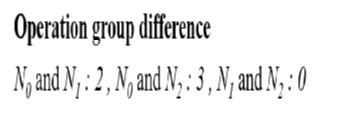
(나는 처음엔 N0, N1, N2 의 operation group 마다 번호가 고정적으로 붙는 줄 알았다. 예컨대, N0는 3, N1 은 5, N2 는 6 이런 식으로 말이다. 그런데 N1과 N2의 차이가 0인 게 말이 안 된다. 그래서 N0, N1, N2 가 각각 여러 개의 operation group 에 속해 있으면, 그 값들을 모두 가질 수 있고 차이를 구할 때 가장 작은 차이를 내는 숫자들을 선별하는 것 같다.)
Implicit pair

- INC postfix equation template 에서 Number index(N0, N1, N2)의 앞뒤에 변수(X0, X1)이 붙어 있는지 확인한다.
- 예컨대 N0, N2 는 모두 붙어 있지만 N1 은 그렇지 않다.
- N1와 같이 붙어 있지 않은 경우엔 같은 operation group 에 속한 연산자(operator)를 이용한다.
- 만약, 2번 이상 등장하면 가장 왼쪽 INC 를 따른다. 이렇게 하는 이유는 효율성을 위해서다. 예컨대, N1은 2번 등장하지만 모두 가까운 변수가 없어 연산자 곱하기, 빼기 중 사용해야 한다. 이중에서 가장 왼쪽은 곱하기니, 자연스레 곱하기를 사용한다.
Base Model
ELECTRA encoder + Transformer decoder
Auxiliary Task
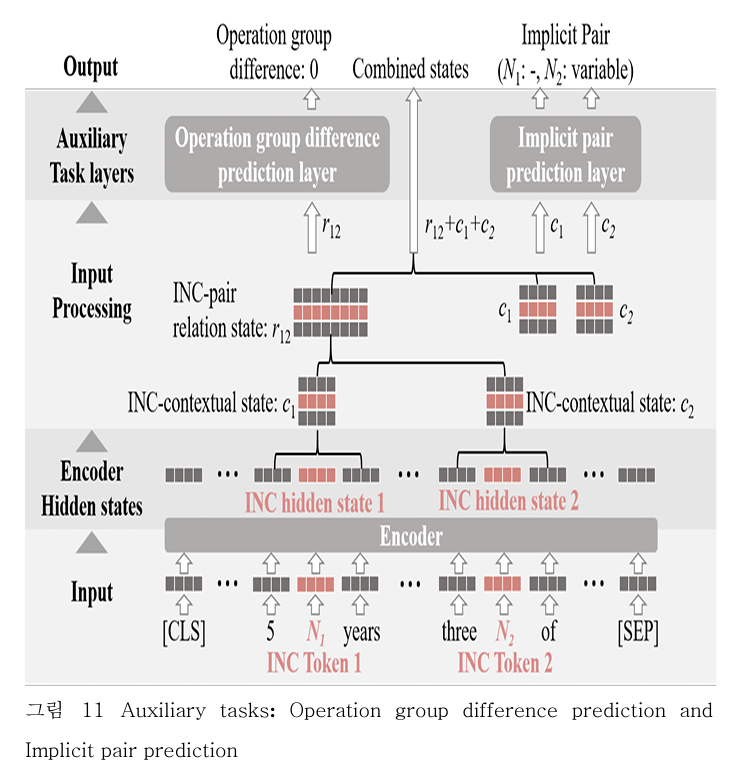
본 연구는 숫자와 변수 간의 관계를 더 잘 이해할 수 있도록 두 가지 보조 태스크를 기본모델에 추가한다.
- operation group difference prediction
- Implicit pair prediction
입력
- INC contextual state: INC Token 이 encoder 를 통과한 뒤 나오는 hidden states 에 windowing 을 적용한 것. windowing 이란, 앞뒤 문맥을 함께 가져가겠다는 의미다. 위 그림에서 보면, INC token 앞뒤 hidden state 를 함께 가지고 있다. 이름 그대로 문맥(contextual) 상태를 갖고 있다.
- INC pair relation state: INC contextual state 의 결합. 위 그림에서 그냥 pair 사이의 벡터를 합치는 걸 볼 수 있다.
Operation group difference prediction
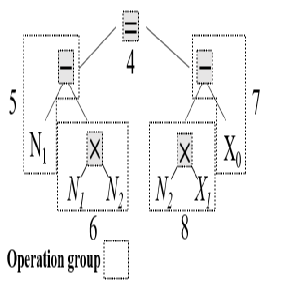
- 설계 목적: INC pair 사이의 상대적인 차이를 구분하여 템플릿 형성시, INC가 적합한 위치에 생성될 수 있도록 함.
- 기능: INC 간의 operation group indices 차이를 구한다.
- 만약 개수가 INC 개수가 n개라면, nC2(조합기호)개의 OG difference 가 계산된다.
- 복수일 때: 복수의 INC pair가 추출될 경우, 가장 작은 차이를 구하도록 한다. 위 그림에서 N1, N2 의 차이는 여러 개다. N1 은 5,6 이 있고 N2 는 6,8 이 있다. 그러므로 5&6, 5&8, 6&6, 6&8 이다. 이 중 가장 작은 차이는 0이다.
구하는 공식은 다음과 같다.
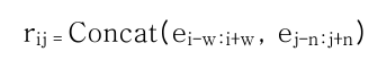

- e i-w: i+w: i-w번째부터 i+w번째 토큰의 encoder hidden states 를 의미함.
- W: windowing size 를 의미한다. 즉, 앞뒤로 몇 칸까지 보겠는가를 의미한다. windowing 이라는 표현은 자주 쓰인다.
- Ci: INC 토큰 i 의 contexual state 를 의미함. (근데 아무리 주변 공식을 봐도, 이 기호는 나오지 않던데..?)
- rij: INC 토큰 i, j 사이의 relation state 를 의미함.
- Concate → Concatenation, FF → linear-feed-forward, Softmax → softmax operation
Implicit pair prediction
- Implicit pair: 변수나 연산자처럼 문제에 명시적으로 나타나지 않지만, 정답식 도출과정에서 필요한 변수 또는 연산자를 의미한다.
- 모든 INC 들은 특정한 implicit pair 1개와 결합된다.
- 만약 복수의 INC 가 존재한다면, implicit pair 는 다음과 같은 우선순위에 따라서 1개가 결정된다.
- 1. Variable: 연산자보다 expression tree 에서 INC와 같은 위계에 놓일 가능성이 높기 때문에 토큰을 생성하는 과정에서 INC와 구별할 수 있도록 가장 높은 우선순위를 갖는다.
- 2. 순서를 고려하는 연산자: 이후 연산자는 순서를 고려하는 연산자(빼기, 나눗셈)를 고려하지 않는 연산자(더하기, 곱하기)보다 높은 우선순위에 배정한다.
- 3. 순서를 고려하지 않는 연산자

Operation Feature Feed Forward(OP3F) Layer
- 설계 목적: encoder 에서 습득한 숫자와 변수 사이의 관계정보를 손실 없이 decoder 에 추가하기 위해 제안된 요소
- 입력: encoder 의 combined states 와 decoder 의 hidden states 를 결합한 형태
- encoder 의 combined states = pair mean of relation states + mean of contextual states 이며, 결합한 뒤 decoder 와 합치기 전에 feed forward layer 를 통과하여 decoder 의 hidden states 와 같은 크기로 변형된다고 한다.

첫번째 식
- E[rij : j > i]: pair mean of relation states
- E[ci]: mean of contextual states
- FF dim: decoder 와 크기를 맞추기 위해 통과하는 feed-forward layer
- h combined: encoder 의 combined states
두번째 식은 생략해도 될 것 같아서 넘긴다.
실험 계획
(구현 방식은 논문에 41, 42쪽에 상세히 나와 있어서 생략한다)
실험 결과
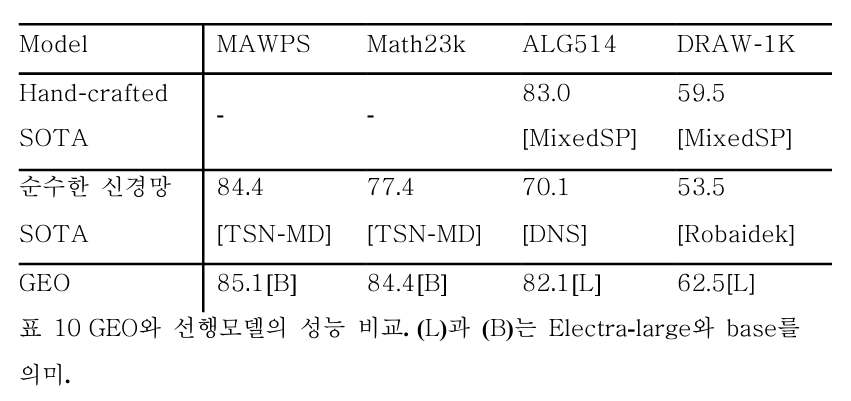
- 성능이 SOTA 와 견주거나 뛰어넘었다.
- 이러한 결과는 GEO모델이 복잡도가 높은정답식을 생성할 때 효과적임을 입증하는 결과이다.
Ablation Study
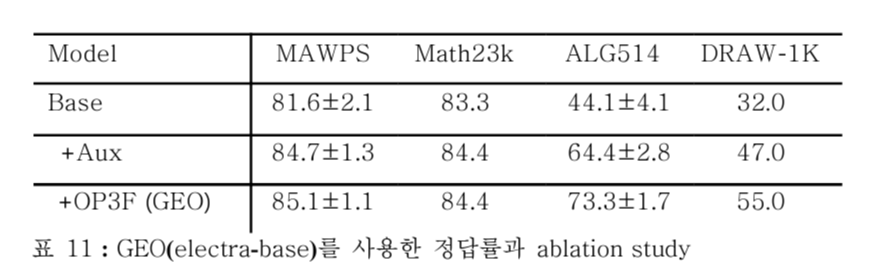
설계목적
→ GEO에서 내포된 숫자와 변수 간의 관계를 이해하기 위해 추가된 요소들이 성능향상에 미치는 영향 파악
baseline: 점점 요소를 추가해보는 방식으로 모델을 구성함.
- base model (Electra +transformer decoder)
- Aux model (base model +auxiliary tasks)
- GEO (base model +auxiliary tasks +OP3F layer)
Aux: base model → Aux model
- 모든 데이터셋에서 성능 향상이 일어남.
OP3F layer: Aux model → GEO
- 복잡도가 낮은 데이터셋에 비해, 높은 데이터셋에서 성능 향상을 보임.
- 즉, 복잡도가 높은 데이터셋에서 효과적임.
분석
- 이러한 결과가 Hand-crafted feature와 aux tasks가 학습하고자 하는 데이터가 다르기 때문인 것으로 파악한다.
- HCF: 문제에 초점을 맞춰 특정 단어의 조합이나 순서를 중심으로 만들어지기 때문에 문제를 구성하는 단어와 어순의 변경에 영향을 크게 받게 됨.
- auxiliary task: 정답 식에 나타난 숫자와 변수 간의 관계에 기반하여 진행되기 때문에 상대적으로 문제를 구성하는 단어와 어순의 영향을 덜 받아모든 데이터셋에서 고른 성능향상을 보인 것으로 확인됨.
Error Analysis

- N1,N2 그리고 N3 와 같은 INC 토큰들 사이의 관계를 포착하지 못한 경우를 보여준다. (무슨 말인지 모르겠다면, Answer equation 과 Base 사이에 틀린 게 3개나 있는데 못 본건 아닌지 다시 확인해보자.)
- 그 결과로 base model은 토큰들을 INC의 위치와 관계없이 생성한 것을 볼 수 있다.
- 이러한 결과를 토대로 유추했을때 base모델이 DRAW 데이터셋에서 32%의 성능밖에 기록하지 못하고 순수한 신경망 SoTA에 비해서도 약 21%나 낮은 수치를 보인 것은 내포된 숫자와 변수 간의 관계를 추출하지 못 했기 때문으로 추정해 볼 수 있다.
- 비슷한 사례: Robaidek의 연구 결과에 따르면 기존 모델에 사전 학습된 언어모델인 ELMO을 추가해서 사용했을 때 53%에서 45.5%까지 DRAW-1K의 정답률이 하락한 것을 보고하였다. 다시 말해서, base model의 결과는 경험적으로
세계지식을 학습한 사전 학습된 언어모델만으로 수학문제풀이 모델의 성능향상에 한계가 있음을 뒷받침하는 결과이다.

- 사례 2는 GEO 모델의 OP3F layer가 encoder 학습과정에서 학습한 숫자와 변수 간의 관계 정보를 직접적으로
decoder 생성과정에 반영할 수 있다는 경험적인 증거를 보여준다. - Base model과 Aux model 는 문제에 없는 숫자 토큰인 N5를 생성하였다.
- 하지만 이와 달리 GEO는 문제에 없는 숫자 토큰을 생성하지 않았다.
- 이러한 결과는 GEO에서 사용한 OP3F layer의 적용 방법이 유사한 문제를 다루는 다른 생성기반의 방법에도 적용될 수 있음을 암시한다.
- 따라서 GEO의 방법론은 의미론적 분석(Semantic parsing)이나 순차적 코딩(sequential coding)등과 같이 소규모 데이터셋이 존재하는 태스크 중 수학문제와 유사한 순차적 생성(sequential generation)문제에 적용해 볼 수 있을 것이다.
결론
본 연구에서 필자는 세 가지 모델을 제안했다.
- Template based Multitasks Classification (TM-classification)
- Generation (TM-generation)
- 연산자 활용 기반의 생성(Generating equations by utilizing operators:GEO)
제안한 모델들은 문장형 수학 문제를 풀기 위한 세 가지 문제를 해결하기 위해 고안되었다.
- (1)모델이 올바른 정답식을 도출할 수있어야 하며
- (2)모델이 내포된 숫자와 변수의 관계를 이해할 수 있어야 하고 (중점적으로 해결한 부분)
- (3) 모델이 문제를 이해하는데 필요한 세계지식을 이용하여 문제내에 생략된 정보를 파악해야 한다.
최종적으로 본 논문은 모든 데이터셋에서 최고성능과 대등한 성능을 기록한 GEO 모델을 선택하였다.
GEO모델을 선택하는 과정
- 필자는 먼저 TMclassification과 TM-generation의 성능비교를 통해 문장형 수학 문제 풀이에 적합한 정답 식 도출방법과 세계지식을 이용할 수 있는 방법을 선택하였다.
- 이 후 내포된 숫자와 변수 간의 관계를 심층적으로 이해할 수 있는 auxiliary tasks와 OP3F layer를 추가하였고 ablation study를 통해 성능향상을 확인하였다.
이러한 결과를 바탕으로 필자는 본 연구를 통해 4개의 기여점을 확인할 수 있었다.
- 첫째, 수학문제 데이터셋의 규모, 복잡도에 관계없이 최고성능과 대등한 성능을 기록한 모델을 제안하였다.
- 둘째, 정답 식 생성기반의 방법은 정답 식 분류기반의 방법보다 적합한 방법임을 성능을 통해 확인하였다.
- 셋째, auxiliary tasks와 OP3F layer의 ablation study를 통해 경험적으로 숫자와 변수 간의 관계를 추출하는데 도움을 주었음을 확인하였다.
- 마지막으로, 언어모델을 사용하는 것이 세계지식을 활용하여 생략된 세계지식을 파악하는 방법임을 확인하였다.
향 후, 필자는 GEO모델을 개선하여 의미론적 분석(semanticparsing)과 같은 생성 난이도가 높은 자연어이해 분야에 적용해볼 것이다.



