
논문명: Learning to Reason Deductively: Math Word Problem Solving as Complex Relation Extraction
논문링크: https://aclanthology.org/2022.acl-long.410.pdf
용어 정리
Math Word Problem (이하 'MWP')
- 수학 문제가 문장화된 형태. 예를 들자면, '철수는 사탕 11개, 영희는 사탕 23개가 있다. 철수가 영희에게 사탕을 모두 양보했다면, 영희는 사탕은 총 몇 개일까?' 와 같은 문제를 의미한다.
quantity
- 숫자. 위 사탕 예시에선, '11', '23' 이 quantity 라고 볼 수 있다.
요약
3줄 요약
- 기존 seq2seq 이나 seq2tree 는 성능은 좋아도 명시적으로 문제를 풀어가는 과정이 드러나지 않음.
- 'MWP = 복잡한 식'이므로, 간단한(=2개의 피연산자와 1개의 연산자) 단계로 나누고자 함.
- 설명가능한 구조로 설계했을 뿐만 아니라 성능 향상까지 해냈음.
상세본
- Math Word Problem 을 푸는 것은 다르게 말하면, 문제에서 숫자(quantity)들을 골라서 연산을 하겠다와 같다.
(예컨대, '영희 사과 1개, 철수 사과 2개. 총 사과의 개수는?' 와 같은 문제가 있다면, 1 과 2 사이의 관계는 더하기다. 즉, 인간은 이런 과정을 통해 문제를 풀어가는 게 자연스럽다.)
- 그런데, 기존 방식은 quantity 사이의 관계 (e.g. 더하기, 빼기)를 명시적으로 추론하지 않는 방식이다.
(기존 방식은 'sequence to sequence', 'sequence to tree' 을 의미한다. 이런 방법들은 input 과 output 만 알지, 그 안에서 어떻게 이 모델이 문제를 풀었는지가 드러나진 않는다. 성능은 좋아도, 왜 그렇게 풀었는지에 대해 답하지 못한다. 예컨대, 구글 번역기로 번역해보면 잘 되기는 하는데 그게 어떤 방식으로 이뤄지는지 우리는 모른 채 사용하고 있는 것처럼 말이다.)
- 그래서 우린 풀이과정이 드러나는 방식으로 문제를 풀겠다.
- 그러기 위해, MWP 를 'complex relation extraction' 라고 정의하겠다.
- 그리고 복잡한 식을 간단하게(=2개의 피연산자와 1개의 연산자) 나눠가며, 단계적으로 풀어나가겠다.
(1 + 2 + 3 이면, 1 + 2 부터 먼저 하고 + 3 을 하겠다는 말이다. 즉, quantity 들을 2개씩 골라서 차례로 계속 계산해가겠다는 말.)
소개
Math Word Problem solving 은 자연어로 구성된 수학 질문에 답하는 task 이다. 이걸 푼다는 건 맥락 속의 quantity 를 통해 논리적인 추론을 하여 답을 내는 것이다. 최근 연구들에선 이걸 생성 문제로 바라본다. 즉, 그런 연구/모델들에선 수학적 식/포현을 완성하는 걸 목표 삼고 있다. 주로, 'sequence to sequence' 나 'sequence to tree' 형태다.
→ 현재 MWP 를 생성문제로 간주하고, 풀어가는 경향이 돋보인다. 그 대표적인 예시 중 하나로 'sequence to tree' 가 있다.
그림에 대한 부가 설명
: 그림 속 예시가 생각보다 어려워서 번역 및 설명을 첨부합니다.
용어 정리
- 피제수(divident, dividend): 나눗셈의 대상이 되는 수
- 제수(divisor): 나누는 수
- 피제수 = 제수 * 몫 + 나머지 → divident = divisor * quotient + remainder
문제 번역
: 나눗셈에서, 나머지가 8이고 제수가 몫의 6배이고, 동시에 나머지의 3배에 3을 더해 얻어진다. 이때, 피제수를 구하시오.
문제 해석
- 나머지는 8이다.
- 제수는 몫의 6배다.
- 제수는 나머지의 3배에 3을 더한 값과 같다.
- 이때, 피제수는 얼마일까?

위 그림을 보면, 'tree generation' 과 'our deductive procedure' 이 상하로 나뉘어 표기되어 있다. 'tree generation' 은 tree 구조를 형성하는데, 이 구조를 바탕으로 최종적인 결과물을 산출한다. 그러나 이 방식엔 몇 가지 한계가 존재한다.
- 1. 이런 과정은 보통 특정 순서를 가지고 있다. 예컨대, 위 예시에 주어진 문제를 보면 제일 처음 나머지가 8이라는 걸 알 수 있다. 그런데 처음부터 더하기 생성자를 만들어 나머지가 8이라는 걸 반영하기엔 이르다. 즉, 직관적이지 못하다. 그리고 사람(학습자)에게 이 순서로 과정을 설명하기에 충분하지 못하다.
- 2. 불필요하게 중복된 연산을 하게 된다. 예컨대, 위 문제에서 제수를 구하기 위해 8 * 3 + 3 = 27 을 계산한다. 낭비가 없으려면, 몫을 구하는 과정에서 바로 이 값을 사용하면 되는데 'tree generation' 은 그렇지 못하다. 위 그림에서도 tree 구조에 2번이나 동일한 연산을 담고 있는 걸 확인할 수 있다.
→ 기존 방식 중 'tree generation' 방식에는 2가지 한계가 있다. 우리는 이를 개선하겠다.
MWP 를 해결하는 것은 연역적 추론이 필요하다, 마치 아이들의 인지 발달 과정에서 중요한 능력처럼. 그래서 본 논문에선 명시적으로 이 단계를 통해 연역적 추론을 제시하는, 참신한 접근을 제안한다. 저자는 MWP 를 'complex relation extraction' 문제로 바라보는 것이 핵심이라고 한다. 즉, MWP 를 문제 안에 존재하는 quantity 사이의 복잡한 관계를 식별하는 과정으로 보는 것이다. 그래서 덧셈, 뺄셈과 같은 방식을 'primitive operation'으로 규정한다. 문학 분야의 최신 연구에서도 이를 통한 성공을 도출해냈기 때문에, 우리도 2개의 quantity 와 1개의 primitive operation 의 관계 추출 과정을 반복한다.
→ 본 논문에선 MWP 를 복잡한 수식으로 간주하고, 가장 간단한 단계(2개의 피연산자 + 1개의 연산자)로 나눠서 정복하고자 한다.

논문 방식: deductive procedure
이 과정을 따르면, 2가지 장점이 있다.
1. 맥락에서 직접적으로 관계를 끌어낸다.
- 예시: 8과 3의 관계('multiplication', 'X')를 맥락('remainder is 8', 'thrice of the remainder') 에서 끌어냈다.
2. 이미 연산을 통해 얻은 값을 재활용 가능하다.
하지만, 이렇게 설계하는 것(deductive procedure)은 여러 개의 challenge가 존재한다.
- 어떤 quantity 는 사실 문제와 무관할 수 있다.
- 어떤 quantity 는 여러 번 사용될 수 있다.
- 모델은 중간 과정에서 계산된 결과로부터 나온 quantity 역시 함께 다룰 수 있어야 한다.
- 최적의 결과를 효율적으로 도출할 수 있어야 한다.
- 언제 deductive procedure 를 멈출지 학습해야 한다.
그래서 저자들은 위 challenge 들을 해결하고자 다음과 같은 기여를 하였다.
- MWP 를 complex relation extraction task 로 간주함.
- 복잡한 식들을 간단한 식으로 나눠서 식별하고자 함.
- 간단한 식이란, 2개의 피연산자와 1개의 연산자(사칙연산 및 제곱)으로 이뤄진 식을 의미함.
- 모델이 자동적으로 최종 답을 도출하기 전까지 설명가능한 단계를 밟아나감. 이는 deductive reasoning process 임.
- 2개 언어(영어, 중국어)로 이뤄진 4개의 dataset 으로 진행된 실험 결과는 본 논문의 모델이 현존하는 baseline 보다 상당한 성능 향상을 보여줌.
- 이전과 다른 새로운 접근을 통해 복잡한 문항들을 풀어나감.

관련 연구
이에 대해선 따로 정리해두겠습니다.
방식
가정
MWP 는 주어진 문제를 단어의 집합으로 볼 수 있다. 즉, n개의 단어로 이뤄진 집합으로 표현가능하다.

그리고 그 안에서 quantity 들이 존재할테니, 그것들만 따로 모아둔 집합으로 표현가능하다. 이때, 개수는 m 이다.

문제를 풀고 수치적인 답을 얻는 것. 이상적으로는 수학적인 추론 과정을 거치는데, 이때 간단한 식의 형태들의 연속적으로 해결해나간다. 이때, 간단한 식은 피연산자 2개, 그리고 초기연산자 1개(+, -, *, /, ^) 로 구성된 식을 의미한다.
(연산자 종류: 더하기, 빼기, 곱하기, 나누기, 제곱)
위에서 언급했듯이, 논문에선 결국 초창기의 수학적 표현/식에선 quantity 사이의 관계는 저 중 하나다. 근본적으로 본다면, 결국 MWP 는 complex relation extraction 이니, 반복적으로 2개의 quantity 사이의 연산을 식별해나가는 과정이 필요하다. 전체적으로 본다면, 각 단계별로 어떤 연산인지 식별하는 모듈이 필요하다.
그런데 실제로 문제를 풀다보면, π(파이) 와 같이 미리 정의된 상수들이 문제에 주어지지 않기 때문에 풀 수 없는 문제들이 있다. 그래서 저자들은 이를 위해 또 상수들의 집합을 준비했다.

이들은 quantity 로 간주될 수 있어서, 최종 답을 도출하기 전까지 유용하게 쓰일 것이다.

1. Deductive System
초기화 단계에선 위 가정을 그대로 따른다. 문제에서 추출한 quantity 의 집합, 그리고 미리 선언된 상수들의 집합. 이 둘의 합집합을 초기 단계로 설정한다.

여기서부터 하나씩 단계(t)가 진행되는데, 매우 간단하다.
- 2개의 피연산자를 뽑는다.
- 1개의 연산자 종류를 구별한다.
- 이를 통해 완성된 표현/식을 intermediate expression 'e' 라고 부른다.
- 이 값을 계산하여 새롭게 추가한다. 그러면 다음 단계로 넘어간다.
- 이 과정을 반복한다.

첫번째 식
- t - 1 단계에서, 두 피연산자(quantity)와 연산자가 결정되었을 때, 계산한 값을 의미함.
- t - 1 단계에서 계산되었으니, 다음 단계인 t 단계에 해당하는 값을 의미함.
두번째 식
- 첫번째 식에서 얻은 새로운 값을 quantity 집합에 추가하는 것을 의미함.
- 매 단계마다 계산된 값을 추가하는 이유는 그 값을 활용할 수 있기 때문임.
세번째 식
- quantity 의 마지막 항이 가장 최근에 계산했던 값이라는 의미다.
2. Model Components
Reasoner: 추론 과정을 맡는 요소

- 1. 먼저 문제에 있는 quantity 를 '<quant>'라는 일반 quantity token 으로 변경한다.
- 2. 그 후, 사전학습 언어 모델(BERT, RoBerta)를 사용하여 각 quantity 별로 quantity representation 을 얻는다. 위 그림의 가장 진한 적색 영역에 해당한다.
- 3. 이제 quantity 간의 가능한 모든 쌍(pair)를 고려해볼 수 있다. 이때, pair 를 representation 으로 정의하는데, 2개의 quantity representation 과 element-wise product 를 concatenation 한 것으로 본다. 위 그림의 보라색 영역에 해당한다.
- 4. pair representation 에 non-linear FFN 을 적용한다. 여기서, 'e' 는 intermediate expression 의 representation 이고, 'op' 는 quantity 쌍에 적용된 연산을 의미한다. 즉, FFN op 는 expression representation 을 위한 특수한 네트워크다.

- 5. 위 그림에서 나누기가 결과적으로 선정되었고, 다음 단계에서 4번째 quantity 가 중간값으로서 추가되었음을 확인할 수 있다. 이런 식으로, 선정된 식/표현을 계산하여 다음 단계에 추가해주는 것이다.
- 6-1. 한편, scoring 을 진행한다. 먼저 첫번째 식부터 살펴보자면, 이와 같이 해석할 수 있다. '다음 단계를 위해 계산된 값이 갖는 점수 = 선택된 2개의 quantity(피연산자) 가 가진 점수의 합 + 선택된 연산자가 가진 점수'.
- 6-2. 연산자나 피연산자가 갖는 점수를 구하는 방법은 w 를 곱하는 것인데, 이때 w는 학습가능한 파라미터다.

- 7. 최종 목표는 결국 각 단계마다 2개의 피연산자와 1개의 연산자를 갖는 표현/식(expression)을 최적으로 찾는 것이다. 이를 다르게 표현하자면, 아래와 같은 optimal expression sequence 를 찾아내는 것이다.

Terminator: 종료 시점을 파악하는 요소
- 계속 진행할 수 없으니, 종료시점을 판단해야 한다.
- binary label τ (타우)에 의해 결정된다. → 1은 종료, 0 은 계속 진행하라는 의미
- 그래서 t 단계에서 표현/식 'e' 의 최종 점수는 아래와 같이 계산된다.
- 우항의 1번째 항은 Reasoner 에서 구한 점수이고, 2번째 항은 Terminator 에서 구한 값이다.
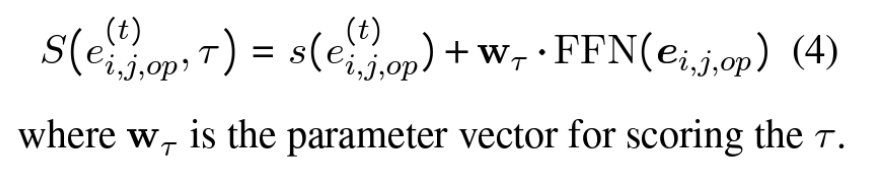
Rationalizer: update 하는 요소
- 이 논문에서의 'rationalization': 단계별로 새롭게 얻어진 식이 있으니, 그에 맞게 현존하는 quantity representation 도 update 하는 과정을 말한다.
- update 를 하는 이유: 하지 않을 경우, 처음에 초기화 단계 때부터 highly ranked 된 quantity 들만 계속 선호될 것이다. 반대로, lowly ranked 된 quantity 들은 쓰이기 힘들어진다. 그래서 매 단계마다, 전체적으로 quantity representation 을 update 하려고 한다.

- updating mechanism: 위 그림과 같이, 기존 quantity 와 그 단계에 탄생한 표현/식 'e' 를 함께 rationalizer 에 넣어서 만든다. 이렇게 하면, 모든 quantity 가 이 단계에서 새로 생성된 표현/식을 인지할 수 있다.

- Rationalizer - GRU: quantity 를 input 으로 두고, e 를 이전의 hidden state 로 간주함.
- Rationalizer - multi-head self-attention: 2개의 token(quantity, e) 를 하나의 문장으로 두고 진행함.

- 수학적으로 표현하자면, 위와 같다. quantity 집합에 속하는 모든 quantity 에 대하여, rationalizer 를 통과시켜 새로운 representation 을 만든다.
3. Training and Inference

- loss function: seq2seq 에서 쓰인 방식인 teacher - forcing strategy 를 사용함.
- Θ: reasoner 에 쓰인 모든 파라미터를 의미함.
- 우항의 2번째 항: L2 정규화(regularization)
- 우항의 1번째 항: 우선 t = 1 부터 t = T 까지라는 건 각 단계별의 합을 의미함.
- 우항의 1번째 항 속 1번째 항: max 라면, 당연히 여러 경우들이 존재해야 하는데, 집합 H 의 원소들로부터 나온다. 집합 H 는 모든 quantity pair 로부터 만들어지는 경우의 수를 일컫는다. 즉, 각 단계마다 모든 quantity pair 를 계산하여 얻은 점수 중 최댓값을 의미한다.
- 우항의 1번째 항 속 2번째 항: inference 한 결과
- 여기서 단계의 개수는 T(타우)가 1이 되면, 멈춘다.
4. Declaritive Constraints
- 위 모델은 현존하는 quantity 에 새로운 quantity 를 추가하는 방식으로 이뤄진다.
- 위 방식의 장점 중 하나는 certain declarative knowledge 를 편리하게 병합할 수 있다는 것이다.
- 즉, 편향되지 않고 늘 모든 quantity 를 고려하면서 계산할 수 있다.
- 실제로 SVAMP dataset 은 동일한 quantity 를 대상으로 하는 연산이 존재하지 않았다. 또, 중간값이 음수인 적은 없었다. → 즉, 편향된 방향으로 학습될 위험이 있다.
- 그래서 저자들은 이러한 경우들을 배제하고 학습 및 추론을 진행하였다.
- 저자들은 이런 제한을 두는 것이 얼마나 성능 향상에 도움이 되는지 보일 것이라고 한다.
→ 위 모델은 모든 경우를 고려하며 학습한다. 그런데, 일부 dataset 에선 편향성을 띄고 있다. 그래서 이를 배척하였고, 얼마나 성능에 도움이 되는지 보여주고자 한다.
실험
Dataset
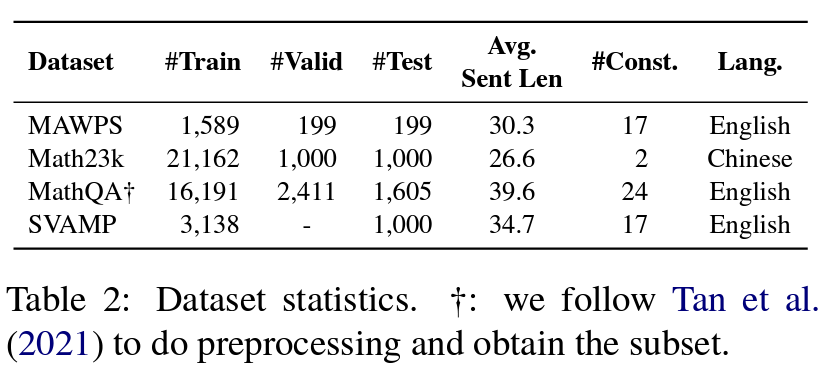
- MathQA: 일부 풀 수 없는 문항은 제외하였음. 숫자로 답이 나오지 않는 경우가 존재함.
- MAWPS and SVAMP: 사칙연산만 고려하였음.
- MathQA and Math23k: 사칙연산 및 제곱 연산만 고려하였음.
→ 이렇게 dataset 에 제한을 많이 두었기 때문에 SOTA 라는 표현을 사용하지 않은 것 같음.

- 문제의 난이도를 측정하는 수단 중 하나로 연산자의 개수를 활용함.
- MathQA: 난이도가 가장 높은 dataset. 60% 이상이 3개 이상의 연산자를 포함함. 또, 물리나 기하학, 확률 등 다양한 분야의 문제가 존재함.
- MAWPS: 97%가 1,2개의 연산자로 이뤄져서 쉬움.
- Math23k: 초등학교 수준
- SVAMP: model's robustness 를 평가하기 위해 만든 challenge set. MAWPS 를 sampling 하여 많은 변형(새로운 quantity 추가, 명사 위치 변경 등)을 주었음.
Baselines
→ 크게 보라색 영역으로 나눠진다는 정도만 알고 봐도 무방하다.
S2S (sequence-to-sequence)
- GroupAttn: question, quantity 관련 여러 형태의 attention mechanisms 을 고안함.
- mBERT-LSTM: multilingual BERT with LSTM decoder
- BERT-BERT: BERT encoder with BERT decoder
- Roberta-Roberta: Roberta encoder with Roberta decoder
S2T/G2T (sequence-to-tree, graph-to-tree)
- GTS: GRU encoder with tree-based decoder
- KA-S2T: BERT encoder with tree-based decoder
- MultiE&D:
- Graph2Tree: models the quantity relations using vGCN
- NeuralSymbolic: S2T architectures + incorporate external knowledge
- NUMS2T: S2T architectures + incorporate external knowledge
- HMS:
- BERT-Tree
Ours
- BERT-DEDUCTREASONER
- ROBERTA-DEDUCTREASONER
- mBERT-DEDUCTREASONER
- XLM-R-DEDUCTREASONER
Training Details
- 영어 데이터: BERT, Roberta
- 중국어 데이터(Math23k): Chinese BERT, Chinese Roberta
- Rationalizer: GRU cell
- 그 이외에도 multilingual BERT, XLM-Roberta 도 실험하였음.
- 사전학습 모델은 HuggingFace 에서 제공하는 Transformers 로 초기화를 진행하였음.
- optimizer: Adam, learning rate: 2e-5, batch size: 30
- 정규화 coefficient λ: 0.01
- radom seed 5개를 돌려 평균을 내어 결과값으로 사용함.
결과
MAWPS

- 기존 모델 성능은 이전에 발행된 논문에서 적힌 값을 발췌함.
- Roberta enoder 가 가장 성능이 우수하였음.
- encoder 에 관계없이 DEDUCTREASONER 가 기존 baselines 보다 성능이 상당히 개선되었음.
- best S2S model (Roberta-Roberta) 와 best S2T model (Roberta-Graph2Tree) 의 성능은 88.4 %, 88.7% 로 거의 같음. 그런데 best our model (Roberta-DEDUCTREASONER)가 3% 더 높음.
Math23k

- 기존 모델 성능은 이전에 발행된 논문에서 적힌 값을 발췌함.
- Roberta enoder 가 가장 성능이 우수하였음.
- encoder 에 관계없이 DEDUCTREASONER 가 기존 baselines 보다 성능이 상당히 개선되었음.
- 기존 방식보다 2% 성능이 더 높음.
MathQA

- 앞에서 언급했듯, challenging 함. complex question 이 많음.
- 기존 최고 성능보다 1.5% 더 높음.
SVAMP

- 앞에서 언급했듯, challenging 함. 고의적으로 challenging 하게 만들어진 question 이 많음.
- 다른 3개의 dataset 과 다르게 매우 까다로움.
- encoder 의 선정이 성능에 많은 영향을 줬음. 많게는 12% 까지 차이가 났음.
- baseline 의 최고 성능보다 3.5 % 높았음.
- constraints 를 결합하였을 때, 상당한 성능 개선이 있었음.
Fine-grained Analysis
- 세부적인 분석을 위해 operation 개수에 따라 accuracy 를 측정했다.
- equation 정답률도 측정했다.
- 여기서 쓰인 baseline은 각각 dataset 에서 최고의 성능을 보였던 모델과 비교를 진행하였다.
- MAWPS, Math23k 에선 모두 개선된 성능을 보인다.
- MathQA 에선 operation 개수가 2,3,4 일 때 성능이 더 좋았다.
- SVAMP 에선, 1개일 때 차이는 미미하나 2개일 때 상당한 성능 차이를 보인다.
- MathQA, SVAMP 에선 보인 성능으로 미루어보아 robust reasoing ability 를 갖고 있다.

왜 SVAMP 에서만 유독 모두 성능이 좋지 못할까?
- 모델 입장에서 혼동될 만한 불필요한 quantity 들이 추가되었다.
- 그래서 이를 측정하고자 쓰이지 않는 unused quantity 가 전체에서 얼마나 차지하는지에 따라 미치는 영향을 측정하고자 하였다.
- 아래 그림을 보면, SVAMP 에선 44.5%가 쓰이지 않는 quantity 가 속하고 있고, 그에 따른 accuracy 는 현저히 떨어진다.
- 이를 통해, 모델은 불필요한 정보로부터 성능 저하가 유발된다고 볼 수 있다.

Effect of Rationalizer
- 사용할 때와 사용하지 않을 때 전반적인 성능 향상이 두드러짐.
- 매 단계마다, 후속적인 추론 과정이 모든 quantity 에게 반영되는 것이 도움이 된다는 것을 보여줌.
- 특히, Math23k 처럼 complex relation problem 에서 상당한 성능 향상이 이뤄지는 걸 볼 때, 복잡한 관계를 풀어나가는 과정에 상당히 기여함을 알 수 있음.
- GRU unit 에 self-Attention 보다 성능이 좋은 이유: 첫번째로, GRU 는 정교한 내부 gating mechanism 을 통해 quantites 의 풍부한 표현이 가능케 한다. 두번째로, attention 은 similarity 를 측정하는 mechanism 이라서, updating 과정에서 본질적으로 변항될 수 있다. 이렇게 되는 이유는 2개의 quantity 와 1개의 expression 간의 similarity 를 측정할 때, expression 생성에 관여했던 quantity 들은 더 높은 similarity 를 갖는다고 인지할 수 있기 때문이다.

사례 연구
결과의 설명가능성
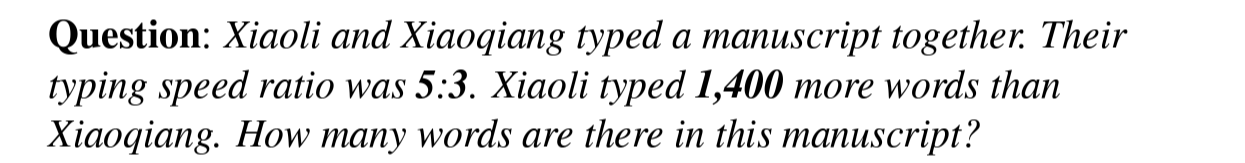
- 문제 해석: 두 남자가 원고를 작성한다. 두 남자가 작성하는 속도는 5:3 의 비를 갖는다. 두 남자가 작성한 양의 차이가 1400개 단어만큼 차이가 날 때, 현재 원고에는 몇 개의 단어가 작성되었을까?

- 위와 같은 풀이 과정을 예상했다.

- 하지만 다른 방식으로 풀었다. 연산과정의 개수 역시 속도 측면에서 반영된 것으로 보이며, 이를 통해 deductive reasoner 가 설명가능한 단계로 나눠서 문제를 이해하며 풀고 있음을 알 수 있다.
질문 섭동
섭동은 사전적으로 걱정, 동요, 불안, 걱정을 의미함. 하지만 이 논문에선 perturbation(섭동) 은 문제를 직관적으로 바꾸는 과정을 의미하는 것 같다. 자세한 내용은 아래 예시를 통해 이해하면 된다.

- 문제 해석: 사과나무가 255 그루 있다. 배나무는 35 그루를 더 심으면, 사과나무 개수와 같아진다고 한다. 이때, 한줄마다 20개의 배나무를 심는다고 하면 총 몇 줄로 다 심을 수 있을까?

- 2번째 문장이 어렵다.
- 실제로 모델 역시 2개의 quantity 를 올바르게 선정했으나, operator 로 빼기보다 더하기를 택했다.
- 실제로 예측한 확률 역시 더하기가 빼기보다 높다.

- 2번째 문장을 직관적으로 변형하였을 때, 모델 역시 정답률이 올라갔다.
- 이로 미루어 볼 때, MWP solving 과 reading comprehension 이 상당히 관련 있음을 알 수 있다. 이는 실제로 교육 심리학에서도 다루는 주제 중 하나다.
Practical Issues
- 1. 상수목록: 우리는 실제로 1이나 π 같은 상수 목록을 추가적인 후보 quantity 로서 추가해야 한다. 이는 search space 의 거대화를 야기한다. 실제로는 상수 목록 중 top-scorng quantities 를 선택하여 사용해야 한다.
- 2. 이항 연산자: 2개의 qunatity 를 대상으로 하는 연산자만 사용하고 있다. 1개, 3개 등을 사용하는 연산자에 대한 도입에 대해 고려할 필요가 있다.
- 3. greedy search: 이를 개선하기 위해 beam search 를 사용하고 있다. 본 논문에선 경험적으로 모델이 reasoning step 에 참여하지 않은 quantity 를 선호하는 경향이 있다는 걸 발견했다. 문제는 beam search 알고리즘을 쓰기 위해서 고려해야 할 search space 가 매 단계마다 커진다는 점이다. 실제로, seq2seq model 안에서 beam search 의 행동 및 영향은 여전히 활발한 연구 주제로 남아있다. 어떻게 이런 환경에서 beam search 가 효과적인 성능을 보였는지에 대해선 흥미로운 연구거리가 될 것 같다.
결론 및 미래의 일(future work)
- 본 논문에선 MWP solving 에 새로운 관점을 제시했다. → MWP 를 complex relation extraction problem 으로 봤다.
- 이를 근거로, deductive reasoning process 를 제시했는데, end-to-end deductive reasoner 를 제시하여 단계별로 answer expression 에 도달하였다.
- 매 단계마다, quantity 간의 수학적 관계를 추출하는 과정을 수행하였다.
- 4개의 dataset 을 기반으로한 실험을 통해 deductive reasoner 의 견고함을 증명하였고, SOTA 를 달성하였다.
- 특히 모델은 연산자의 개수가 많은 복잡한 문항들에서 강세를 보였다.
- 이를 통해, 우리 모델의 연역적 특성이 결과를 해석할 수 있는 유연성도 제공하였다.
- 앞으로, 새롭게 개척한 방향에서 어떻게 deductive reasoning process 에 common sense knowledge 를 결합할 것인지에 대해 연구할 것이다. 그리고 어떻게 역설적인 추론을 가능케 할 것인지에 대해서도 노력할 것이다.



