논문명: BERTSCORE: EVALUATING TEXT GENERATION WITH BERT

https://arxiv.org/abs/1904.09675
BERTScore: Evaluating Text Generation with BERT
We propose BERTScore, an automatic evaluation metric for text generation. Analogously to common metrics, BERTScore computes a similarity score for each token in the candidate sentence with each token in the reference sentence. However, instead of exact mat
arxiv.org
초록
- Automatic evaluation metric 'BERTSCORE' 를 제시한다.
- 단순히 'Exact Match'뿐만 아니라 '의미적 유사도(semantic similarity)'도 반영한다.
- 정답(reference)의 token 과 예측값(candidate)의 token 사이의 similarity 를 구한다.
- '363개의 번역과 이미지 설명 체계'에서 검증한 결과, 'BERTSCORE'가 가장 사람의 평가와 관련이 깊었다.
- 'adversarial paraphrase detection' 을 통해서 더 어려운 예제들에서도 기존 metric 보다 'BERTSCORE'가 더 견고하다(robust)는 걸 밝혀냈다.
본론
기존 평가 방식은 생김새(surface-form similarity)에 의존하기 바빴다
다른 분야와 다르게 생성분야(generation)는 'metric'으로도 어려움을 겪는다. 분류(classification)에서는 '개', '고양이' 등 확실한 정답을 갖지만, 'I like you.' 를 가장 잘 번역한 문장은 정답이 하나가 아니다. 어쩔 수 없이 가장 평이한 문장인 '나는 너를 좋아해.'를 정답으로 넣을 뿐, 아래 문장들 역시 정답이다.
- 난 네가 좋아.
- 널 좋아해.
- 좋아한다고, 너를.
- 난 너를 좋아해.
하지만 기존 평가 방식은 'Exact Match' 를 요구한다. 정답이 '나는 너를 좋아해' 라면, '난 너를 좋아해'는 틀렸다고 채점한다는 것이다. '나는'과 '난'은 의미상 동일한데도, 구분할 수 없다. 대부분의 평가 지표(metric)이 이런 방식을 따라왔다. 대표적으로 'BLEU Score'가 있다.
그렇다면 기존 평가 지표(Existing Metric)는 어떤 모습을 보여줬는가?
어떤 논문이든 제대로 이해하고 싶다면,
- 현황은 어땠고
- 그게 어떤 문제가 있었고
- 어떻게 개선했고
- 어떻게 실험적으로 증명했나?
가 일반적인 흐름이다. 그러니 우선 현황이 어땠는지 살펴보자. 논문에선 크게 4가지 관점으로 나눠서 이야기한다. 하지만 중요한 몇 가지만 짚고 가겠다.
- n-gram matching
- edit distance
- embedding matching
- learned functions
n-GRAM MATCHING APPROACHES
여기서 대표적으로 언급하는 평가지표는 'BLEU Score'와 'METEOR Score'다. 이건 논문 설명만으로 이해가 어려울 수 있어서 내가 따로 정리해둔 링크를 남기고 넘어가겠다.
- BLEU Score: https://heygeronimo.tistory.com/20
- METEOR Score: https://heygeronimo.tistory.com/26
이해를 했다는 전제 하에, n-gram matching 의 문제점을 지적한다면 다음과 같다.
"The higher the n is, the more the metric is able to capture word order, but it also becomes more restrictive and constrained to the exact form of the reference."
→ N 이 커지면 커질수록, 단어의 순서를 잘 잡을 수는 있어도, 정답과 완전히 일치해야만 점수를 받을 수 있다. 이는 제한적이고 엄격하다.
하지만 BERTSCORE 는 n-gram 길이에 제한되지 않고, 대신 contextual embedding 에 의존한다. 이는, 잠재적으로 길이에 제한되지 않고, 종속성(dependency)를 포착할 수 있다는 의미다.
물론, 이 문제를 'METEOR Score' 에서 다루고 있다. 'METEOR Score'도 'Relaxed Match'를 경유한다. 문제는 'METEOR Score'는 Matching 을 위해 사전 같이 외부 도구(external source)가 필요하다. 그러다보니, 5개 국어까지 지원하지 않고 있다. 반면, 'BERTSCORE'는 막대한 양의 데이터(raw text)를 통해 학습했기 때문에 104개 국어를 지원한다.
그 이외에도 관련 있는 여러 metric 을 언급하는데, 'BERTSCORE'와 비교하지 않아서 넘어가도 좋을 것 같다. 어떤 종류가 있는지는 남겨두겠다.
- METEOR Score 1.5, METEOR ++ 2.0
- CHRF, CHRF++
- NIST
- ROUGE
- CIDER
EMBEDDING-BASED METRICS
기존에도 임베딩을 통해 유사도를 계산하는 metric 이 있었다고 한다. 예시로, 'MEANT 2.0' 과 'YISI-1'을 드는데 문제점이 있었다.
- 'BERTSCORE'는 BERT 를 통해 임베딩이 이루어진다. 즉, 그 문장에서의 'context'가 토큰에 반영된다. 그리고 그 문장에서의 순서 역시 반영된다고 말한다. 그래서 'contextual embedding'임을 강조한다.
- 외부 도구(external tools)를 사용하지 않으니, 새로운 언어에도 간단하고(simple) 휴대성이 좋다(portable).
이어서, similarity 를 구할 때, token matching 방식에 대해서도 언급한다. 'greedy matching 과 optimal matching 사이의 trade-off' 가 있어서 이에 대해 연구한 논문도 있고, 'optimal matching' 을 제안하는 평가지표로 'WMD', 'WMDo', 'SMS' 와 같은 게 있다고 말한다. 하지만 'BERTSCORE' 는 이와 무관하다며 선을 긋는다.
"our token-level computation allows us to weigh tokens differently according to their importance."
3. 우리의 계산 방식은 토큰의 중요성에 따라 각각 적절히 무게를 조절할 수 있다.
LEARNED METRICS
말 그대로 무언갈 '배운' 평가지표다. 다음과 같은 지표를 소개한다.
- BEER: 'character n-grams' 과 'word bigrams' 에 기반한 regression model
- BLEND: 현존하는 29가지 metric 을 통합하고자 만든 regression model
- RUSE: 3개의 pre-trained sentence model 을 통합함.
이런 방법은 비효율적이다. 사람이 일일이 dataset 마다 들여다봐야하고, 새로운 영역에선 성능이 형편없을 것이다. 즉, 잘 아는 영역에서만 잘 알게 된다라고 말한다. 그러고는, 'BERTSCORE' 는 특정 영역에 치우치지 않았다고 말하며 끝을 낸다.
어떻게 'BERTSCORE' 를 계산하는가?
요약
- 정답(reference)과 예측(candidate)가 문장으로 주어질 때
- BERT 를 사용하여 문맥을 반영한 임베딩(contextual embedding)을 한 후
- cosine similarity 를 계산한다.
- 이때, 선택적으로 IDF(inverse document frequency) score 로 가중치를 줄 수 있다.
ㄱ. Token Representation

위 그림을 통해 Reference 와 Candidate 의 예시를 이해하면서 따라가면 좋다. 'BERT' 나 'ELMo' 같은 모델을 통해 임베딩을 한다. 이 때, 같은 단어라도 주변 단어에 따라 임베딩이 달라진다. 즉, 문맥을 반영한 결과물이라는 점을 인지해야 한다.
예컨대, 두 문장엔 'is' 와 'today' 가 함께 쓰이지만 서로 다른 임베딩을 갖는다. (만약 이게 왜 다른지 모르겠다면, 'BERT' 와 같은 모델부터 다시 공부해야 하는 단계다.)
ㄴ. Similarity Measure

구한 벡터들간의 유사도를 구한다. 이 때, 코사인 유사도(cosine similarity)를 구한다. 저자들은 이 방식이 'soft measure' 이라고 부른다. 그 이유로 완벽하게 일치(exact matching)하거나 'heuristic matching' 을 사용하지 않기 때문이라고 답한다.
ㄷ. BERTSCORE
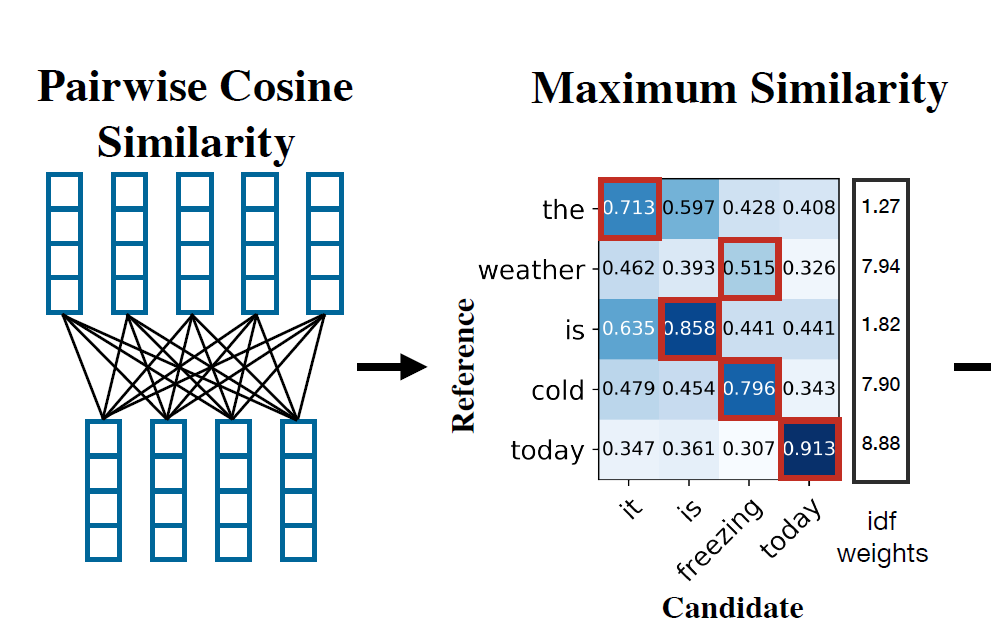
우선 위 그림처럼 코사인 유사도를 통해 모든 값을 구하면, 위 행렬처럼 유사도를 정리해볼 수 있다. 이를 통해, Recall, Precision, 그리고 F1 Score 를 구해볼 수 있다.

위와 같은 공식이 있는데, 공식 자체로 이해가 어려울 수 있으니 Recall 공식을 예시로 설명해보고자 한다.
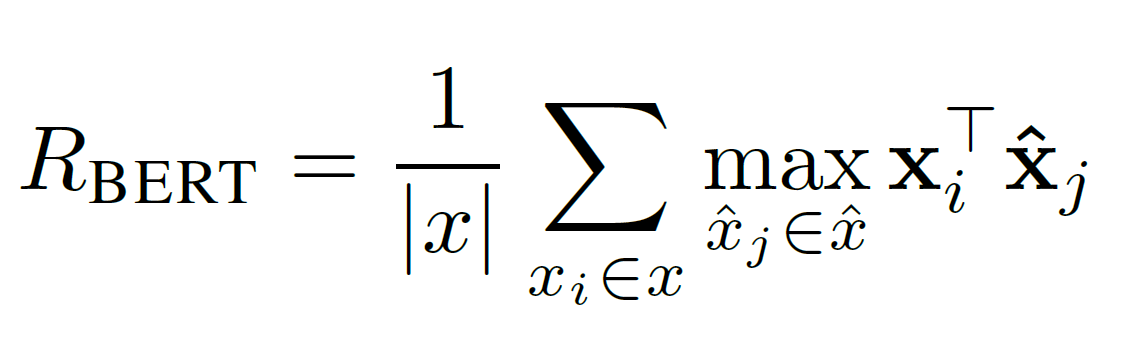
우선 Recall 의 정의에 따라 정답(reference)을 기준으로 예측(candidate)이 얼마나 잘 되었는가를 판단할 것이다.
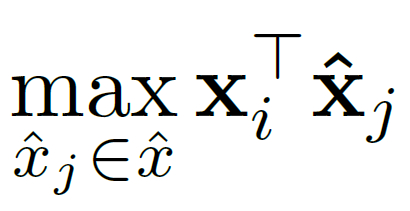

이 공식의 의미는 뭘까. 하나의 정답 토큰에 대해 여러 개의 예측 토큰을 대조해보면서 가장 높은 유사도 값을 가져가겠다는 의미다. 예컨대, 정답으로 'cold' 토큰을 선택했다면 가장 높은 유사도(0.796)를 가진 'freezing' 이 선택된다.
이 이해를 바탕으로 원래 공식을 보면, '정답 토큰을 기준으로 하나씩 제일 높은 유사도 값을 구해서 평균을 내는 게 Recall 이구나.' 라고 받아들이면 된다. 또한, 이 공식을 이해했다면 Precision 과 F1 Score 를 이해하는 것도 전혀 어려울 게 없다.
ㄹ. Important Weighting

저자들은 이런 주장을 받아들인다,
"Previous work on similarity measures demonstrated that rare words can be more indicative for sentence similarity than common words." (희귀하게 등장하는 단어들은 더 많은 문장 유사성을 담고 있을 수 있다.)
→ 즉, 빈도수가 낮은 단어들이 중요하다는 점에 착안하여 공식에 반영하겠다는 의미다.

그래서 공식에도 idf 값이 곱해져서 weighting 이 일어나는 걸 볼 수 있다. IDF Score 를 굳이 다루지 않겠다. 만약 모른다면, 이것 역시 자연어처리의 기초가 되는 내용이라 공부하면 좋다.
ㅁ. Baseline Rescaling
pre-normalized vector 를 쓰기 때문에, 코사인 유사도는 -1 ~ 1 사이의 범위 값이 나와야 정상이다. 하지만 실제로 계산해본 결과, 그 범위가 더 좁았다. 그 이유로는 저자들은 'the learned geometry of contextual embeddings' 라고 하는데 솔직히 무슨 말인지 정확하게는 이해하지 못했다.
어째됐건 이런 특성이 값을 더 가독성을 떨어뜨린다고 한다(less readable). 이런 문제를 해결하고자, 경험적 하한선 'b' 를 baseline 으로 삼는다. 이 'b' 는 Common Crawl monolingual datasets 를 통해 얻어낸 값이라고 한다. 'b' 를 구할 때, 무작위로 두 문장을 엮어서 유사도를 100만번 구했다고 한다. 무작위로 해야 최대한 다양하고 관련 없이 유사도의 최소값을 구할 수 있다고 판단했다고 한다.

구한 'b' 를 바탕으로 위 공식처럼 rescaling 을 해준다. 이 과정을 거치면 0 ~ 1 사이 값으로 나오며, Precision 과 F1 Score 를 구할 때도 마찬가지다. 그리고 이 과정이 미치는 영향에 대해 다음과 같이 언급한다.
"This method does not affect the ranking ability and human correlation of BERTSCORE, and is intended solely to increase the score readability."
→ 이 방법은 ranking ability 나 human correlation 에 영향을 끼치지 않고, 오로지 score 의 가독성만 높여줄 뿐이다.
어떤 방식으로 실험했고, 그 결과는 어떠한가?
ㄱ. WMT2018: Translation Dataset
우선 실험에 쓰인 데이터를 봐야 하는데, 'WMT2018' 이었다. 그런데, 이 데이터 심상치 않다. 엄청난 규모와 정성으로 전세계 사람들이 모여서 만든 모양이다. 데이터를 보지 않고서는 도저히 논문을 읽을 수 없어서 찾아봤다.
대충 논문을 겉핧기로 본 결과, 다음과 같은 결론을 내렸다.
- 팀을 신청을 받는다. 사례로, 마이크로소프트에서 참여했었다.
- 팀마다 직접 번역하는 게 아니라 '번역 모델(machine translation system)'을 갖고 있다.
- 그래서 각 'system' 들이 주어진 데이터들을 번역한다.
그런데, 잘 번역했는지를 알려면 결국 사람이 직접 평가(human evaluation)하는 수 밖에 없다.
- Crowd-Sourcing 을 통해, 직접 사람들이 평가할 수 있도록 했다.
- 어떤 system 인지 알 수 없고, 단지 번역한 문장만 보고 점수를 매겼다. → fragment
- 그 후에, 그 점수들을 정규화 및 평균 등의 처리를 통해 'system' 별 성능을 구했다. → system
→ 결론적으로 이 데이터는 사람이 직접 평가를 내린 점수가 있다. 그 점수와 'BERTSCORE'가 다른 METRIC 보다 유사하다는 걸 보여줌으로서, 타당함을 제시하고자 한다.

당연히 성능이 높다. Precision, Recall, F1, F1 with idf 가 대부분 높다. 피어슨 상관계수 값이 1에 가까울수록, 두 변수(사람이 매긴 점수와 metric)이 유사하다고 보면 된다.
결론
사실, 뒤에 결과도 더 있고 다양한 모델로 해본 것도 많다. 하지만, 이 정도까지만 봐도 충분하다고 생각한다. 더 궁금하신 분들은 내 글을 토대로 이해를 했으니, 이어서 보시면 좋겠다.
의견
1. BERT 를 활용한 METRIC (+)
BERT 를 활용하여 METRIC 을 개선하려는 시도는 신선했다고 생각했다. '생성'은 특히 METRIC 이 까다로운 만큼, 덕분에 많은 공부를 할 수 있었다.
2. 최고값을 선택하는 것이 옳은가? (-)
'왜 최고값만을 고집하는가'에 대한 의문이 들었다. 아래 예시를 다시 보자.
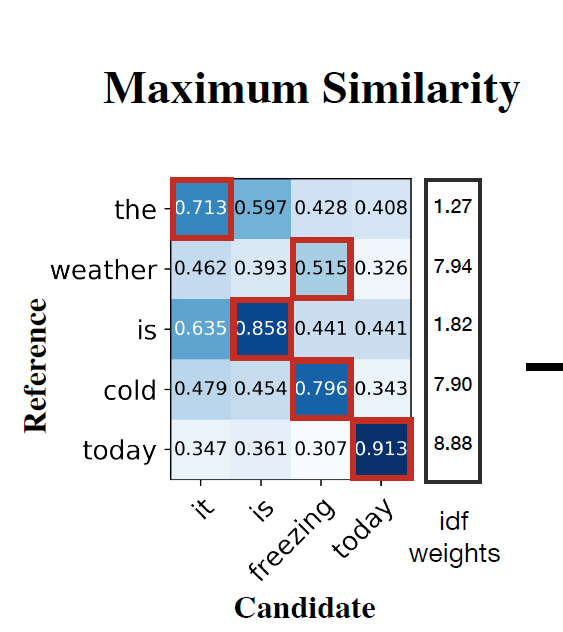
지금이야 최고값이 적절히 다 다른 토큰과 연결되었지만, 매번 그럴 리가 없다. 만약 Reference 의 모든 토큰이 'today' 와 계산한 유사도가 최고라면, 모두 today 를 택할 것이다. 설사 그게 결과론적으로 가장 인간의 척도와 가깝더라도, 이 방식이 '과정'에서 정당한지 의문이 든다.
참고 자료
WMT2018: https://paperswithcode.com/paper/findings-of-the-2018-conference-on-machine
Papers with Code - Findings of the 2018 Conference on Machine Translation (WMT18)
No code available yet.
paperswithcode.com
피어슨 상관계수: https://umbum.dev/1006
피어슨 상관 계수 (Pearson Correlation Coefficient)
상관계수(correlation coefficient)란 두 변수가 어떤 상관 관계를 가지는가?를 의미하는 수치다. +1은 완벽한 양의 선형 상관 관계, 0은 선형 상관 관계 없음, -1은 완벽한 음의 선형 상관 관계를 의미한
umbum.dev



