논문명: The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning
논문링크: https://arxiv.org/abs/2305.14045
The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning
Language models (LMs) with less than 100B parameters are known to perform poorly on chain-of-thought (CoT) reasoning in contrast to large LMs when solving unseen tasks. In this work, we aim to equip smaller LMs with the step-by-step reasoning capability by
arxiv.org
한국인이 쓰셨고, 비교적 작은 거대모델 만들 때 CoT fine-tuning 이 효과적이라고 들어서 읽어보게 되었다.
요약
- 100B 이하 모델들? 솔직히 CoT 로 추론시키면 unseen task 에선 형편 없어.
- 하지만 우리의 목적은 비록 작은 언어 모델이라도 잘 하게 만드는 것.
- 그래서 Flan Collection 을 일부 증강한 CoT collection 이란 데이터셋을 제안해서 성능을 올렸다.
배경
- 거대 언어 모델이 등장하면서 성능을 올리는 방법 중 하나로 CoT(Chain of Thought) 가 있음.
- 그런데 100B은 넘어야 효과가 있고, 작은 모델에겐 항상 효과적인 건 아니었음
- 그래서 요즘 CoT 연구는 Chain of Thought 형태 데이터셋을 학습하는 건데, CoT fine-tuning 이라고 부름
- 하지만 CoT fine-tuning 을 적용했던 한 연구는 소수의 task(9개)에 대해서만 데이터셋을 제작하였기 때문에, 나머지 태스크 1827개에 대해선 일반화 성능이 저조했음
- 그래서 본 논문에선 1060개의 태스크를 포함한 184만개의 근거(rationale)를 FLAN collection 으로부터 증강하여 fine-tuning 을 통해 성능을 개선함
제작과정
1. 기초 데이터 선정
ㄱ. Flan Collection: 1,836 NLP tasks 로 구성됨. P3, SuperNaturalInstructions, Flan 이 포함됨.
ㄴ. 대화 데이터셋 (뭔지 안 적혀 있음)
ㄷ. 코드 데이터셋 (뭔지 안 적혀 있음)
이 중 1060개 task를 선정했는데 기준은 다음과 같다.
기준
- 길이가 긴 건 제외: 학습할 때 근거까지 추가하면 더 길어지는데 모델은 토큰 길이 기준 512까지 못 읽음
- 공적으로 사용하기 어려운 데이터셋은 제외 - 예시: DeepMind Coding Contents and Dr Repair
- huggingface 에서 다운로드받았을 때, input 과 output 이 쌍을 이루지 않으면 제외
- 데이터셋 소스가 겹칠 경우, P3, SNI, Flan 순으로 우선순위를 매겨서 사용 (우선순위 근거 안 적혀 있음)
- 거대 모델이 근거 생성할 때 유독 짧게 만드는 task 인 경우 제외 - 예시: sentiment analysis, sentence completion, coreference resolution, and word disambiguation
For sampling training instances, we sample instances from Flan Collection (Longpre et al., 2023) by using the proportion of 23.94%(FLAN), 30.85%(P3), 7.89%(Existing 9 CoT datasets), 25.47%(SNI) and 11.85%(other dialogue & code datasets). This is done by sampling 400 instances (FLAN), 300 instances (P3), 150 instances (SNI), 4000 instances (Existing 9 CoT datasets), and 300 instances (other dialogue & code datasets), respectively
- 논문 부록에 정확한 비율과 개수가 작성되어 있다.
2. 근거(Rationale) 생성

- 아무리 ChatGPT 같은 API 쓰려고 해도 그냥 만들라고 할 수 없었음
- 그래서 예시를 제공하는 프롬프트 방식인 ICL(In Context Learning) 사용
- ICL를 위해 사람이 직접 예시를 만들어야 함. 예시를 만들려니, task 별로 개당 8개만 만들어도 총 task 가 1060개니까 8480개나 만들어야 함. 이건 아님....
- 그래서 비슷한 task 끼리 묶었음. 가령 multiple choice QA, closed book QA, and dialogue generation 은 비슷하다고 보고 묶어서 같은 프롬프트를 쓰기로 함.
- 그렇게 묶고 보니 26개의 그룹이 만들어짐. (1060개를 어떻게 26개로 묶었는지 보고 싶었는데 github 가서 대충 끄적이는 수준으로는 확인이 어려움. 그래서 포기함.)
- task 당 6 ~8개의 예제를 직접 작성함. 저자 3명이서 했는데, 2명은 예제 각자 만들고 나머지 1명이 A/B blind test 로 더 나은 걸 골랐다고 함.
- 위 그림이 8개의 예시를 주고, 마지막 9번째는 직접 근거를 생성하도록 비워둔 프롬프트임.
증강은 OpenAI 의 Codex 모델을 사용했다고 함. 솔직히 논문 제출 시기도 23.10 인데 왜 이걸 쓴 거지? 모델 선정 기준은 나와있지 않다. 내 지식의 부족이겠지만 Codex 로 증강하는 최신 논문은 처음 봤다.
top-p sampling
- p =0.8
- no_repeat_n_gram =3
- 이렇게 할 때 실험적으로 좋은 근거를 생성했다고 말한다
부록: 필터링
: 논문 페이지 수 제한 때문에 뒤로 밀린 것 같다. 이렇게 생성한 근거들이 정말 좋은 근거들인지 걸러내고 분석한다.
데이터 1개당 5개의 증강 데이터를 생성했다고 한다.
- 근거를 공백 기준으로 나눠서 볼 때, 정답을 포함하지 않으면 제외: 포함하지 않는다고 해서 반드시 나쁜 근거는 아니었으나, 일관성을 유지하는 측면에서 효과적이었다고 함
- 길이가 길면 제외: 근거와 정답 길이가 512가 넘지 않도록 함
- 완전히 똑같은 근거가 있으면 제외: 5개 중 2개가 서로 완전 동일하면 제외했다는 의미
- 문단 내 문장을 반복하면 제외: 생성 모델의 고질적인 문제라서 이렇게 답하면 만약을 위해 제거한 것으로 보인다
- 위 그림은 실제로 필터링된 문항이라고 한다.
- 1번째는 정답 '7'이 포함된 근거도 아니고 길이가 매우 길어서 걸러진 것 같다.
- 2번째는 길이는 괜찮은데 정답 '-28'이 없어서 제거된 것 같다.
Also, we found that in many cases, Codex degenerates and starts writing code after the rationale. To prevent inclusion of code snippets, we apply additional filtering based on trigger tokens that abundantly appear in the start of the code. The list of trigger tokens are as follows:
- 내가 영어를 못해서 그런가 번역기를 돌려도 무슨 말인지 첫 문장을 이해하지 못했다.
- 내 생각엔 근거 다음에 나오는 코드는 좋지 못해서 코드 부분은 싹 걸렀다는 말 같은데, 영어 고수분들 도와주세요!
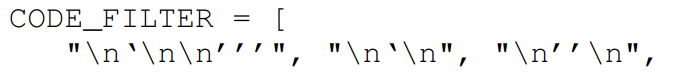

- 위는 코드가 등장하기 직전에 나오는 토큰들이라고 한다.
- 이 토큰들이 나오면 제거했다고 한다.
(왜 Codex 로 했을까 궁금하다)
부록: 분석
다양성
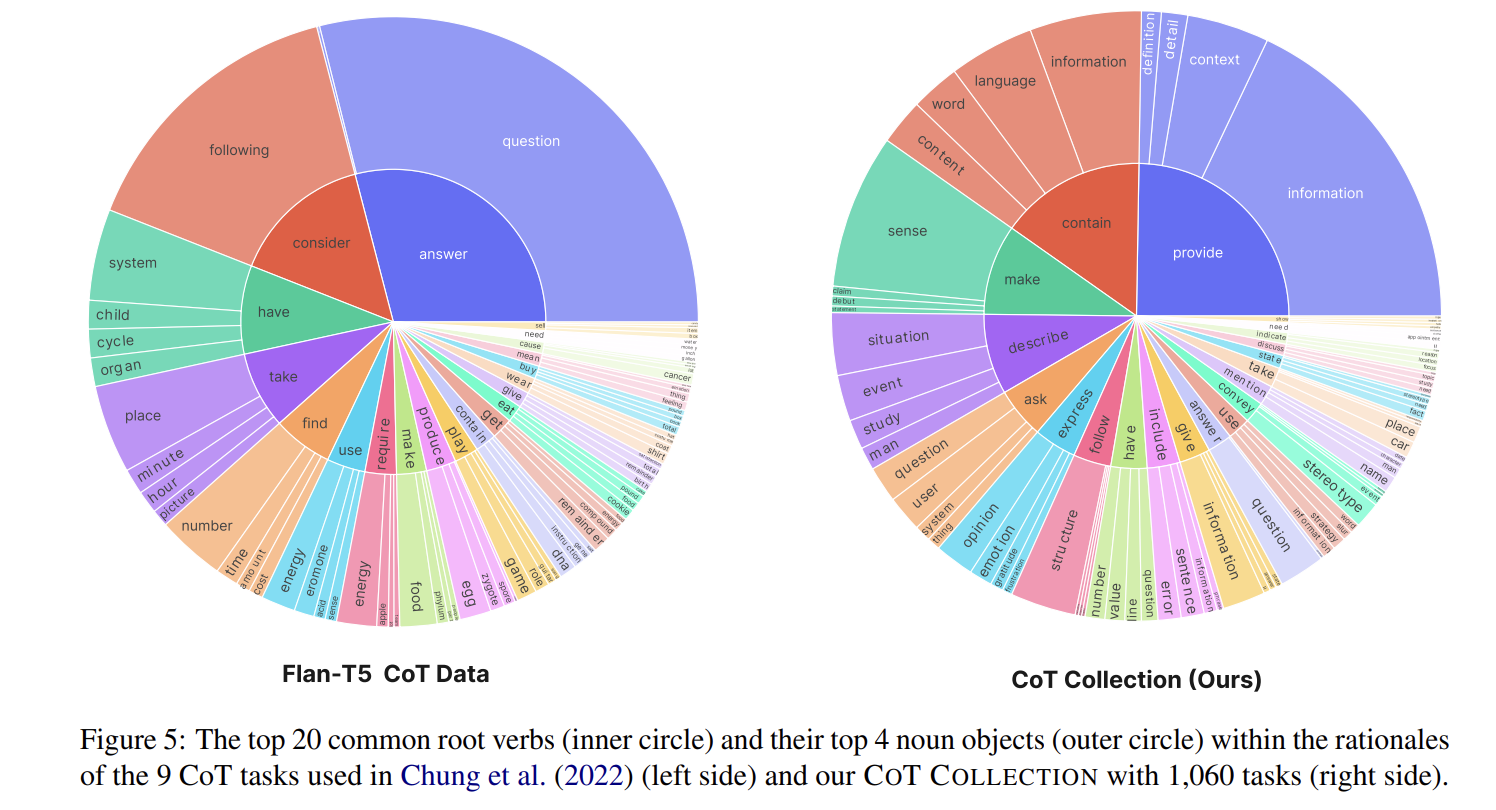
- Berkeley Neural Parser 를 사용해서 동사 위주로 TOP20을 뽑아서 시각화 했다고 한다.
- 그리고 동사 안에선 TOP4 명사를 뽑았다고 한다.
- 왼쪽은 "배경에서 언급했던 9개 task에 대해서만 증강한 데이터"인데 그것보다 더 다양성을 확보했다고 주장한다
퀄리티
(질이라고 쓰기엔 퀄리티라는 단어만큼 잘 표현되지 않는다...좋은 우리말 없을까)
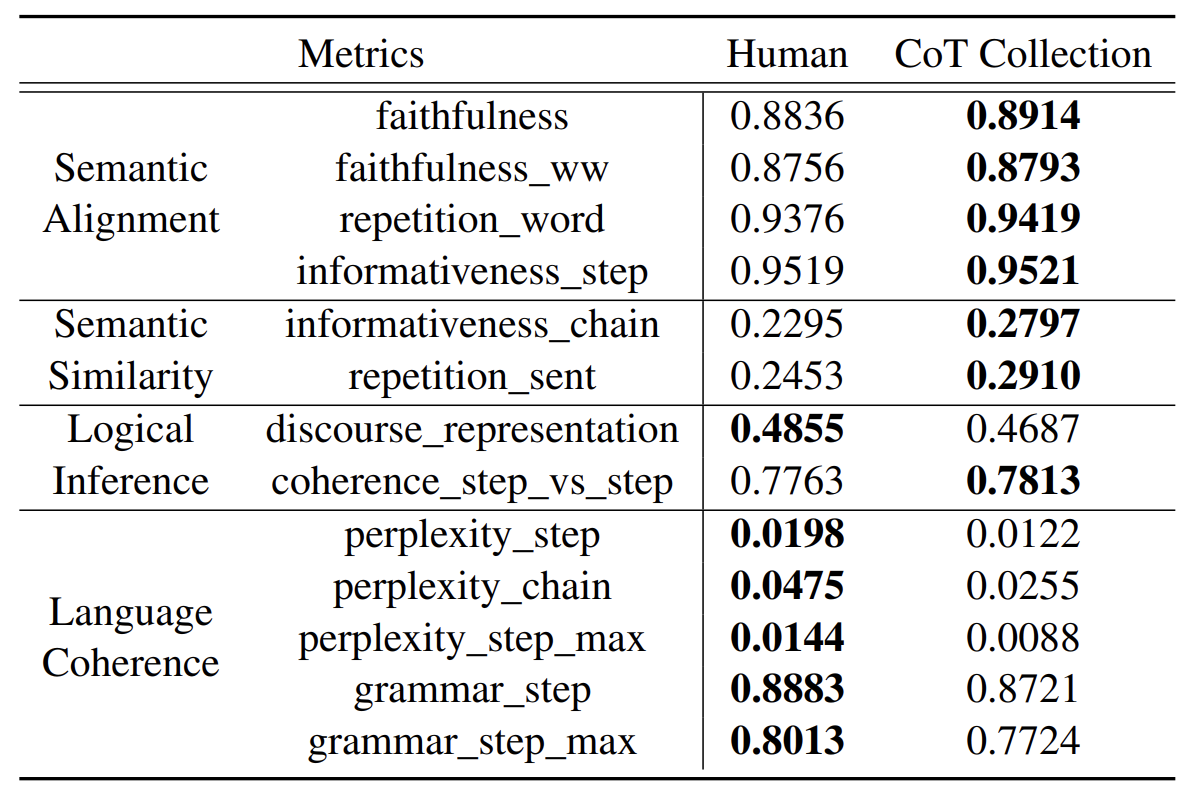
- ROSCOE: 처음 보는 지표인데 논문 제목이 "Suite of Metrics for Scoring Step-by-Step Reasoning" 인 걸 보니까 이런 데이터셋을 평가하는데 도움이 되는 것 같다. 여기 적힌 모든 지표가 ROSCOE에서 평가한 수치라고 한다.
- CoT Collection 은 본 논문에서 거대모델로 만든 것이고, Human 은 아까 예제를 위해 저자 3명이서 만들었던 예제라고 한다.
- Language Coherence 빼고 다 좋다. Language Coherence 에서 성능이 떨어지는 이유를 다양한 프롬프트를 넣어서 제작했기 때문이 아닌가라고 저자는 추측한다.
- 참고로 Perplexity 는 언어모델을 평가하는 지표가 아니라 topic modeling 에서 coherence 를 측정할 때 쓰는 지표다. 그러니까 숫자가 높을수록 좋다.
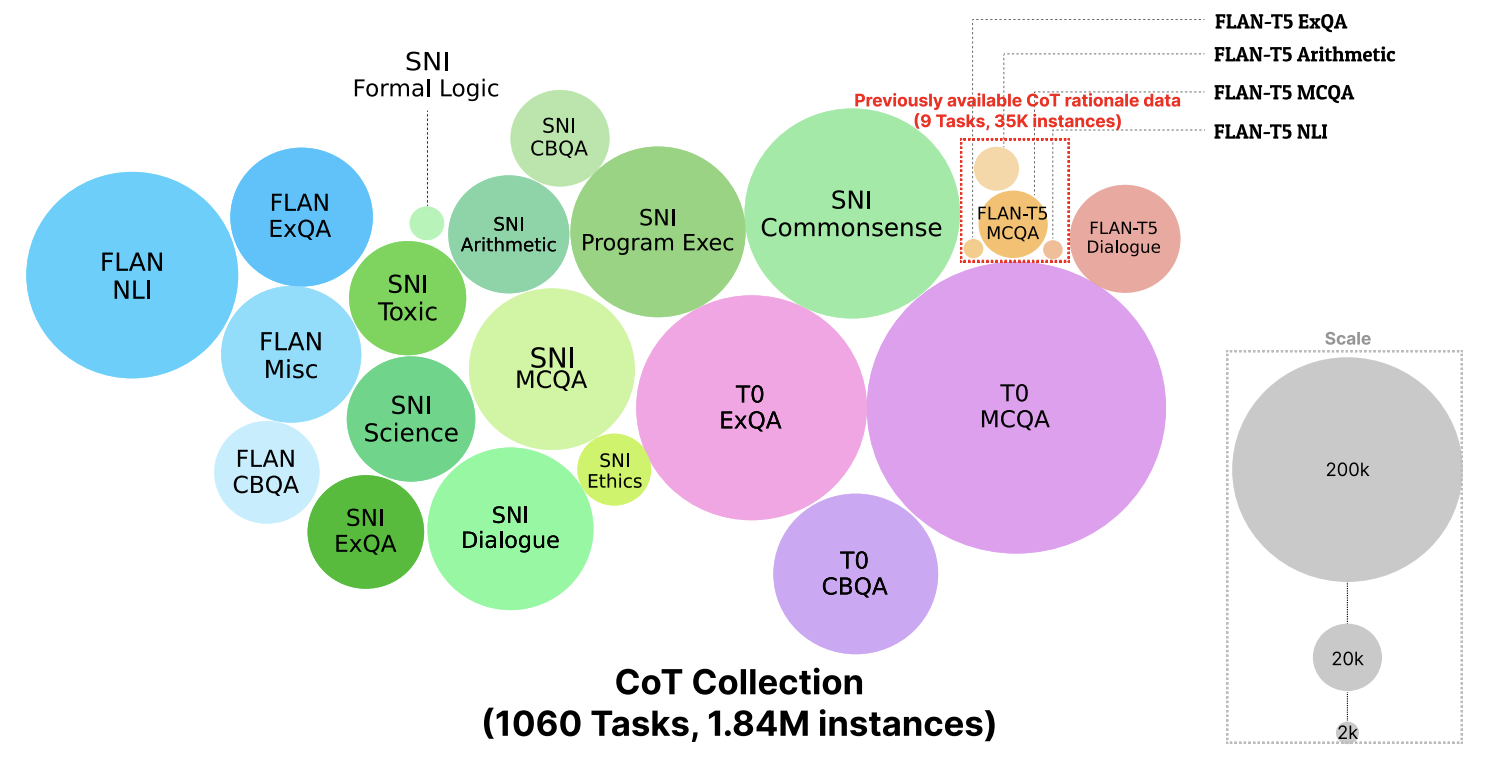
- 이렇게 만들면 엄청난 규모의 데이터셋을 구성하게 된다
- 이전에 CoT rationale data 규모에 비하면 압도적이다
재현가능성

- Codex 에 한정해서 잘 한 거 아니냐고 반문을 제기할까봐 Bard 와 Claude 로도 해봤다고 한다.
- 평가 결과, 거대모델이면 다 비슷한 수준의 데이터를 생성하니 걱정하지 말라고 한다.
실험
실험 설정
- 베이스라인 모델: Flan T5 (Instruction Tuning 을 최초로 제안한 논문에서 T5 를 학습한 모델)
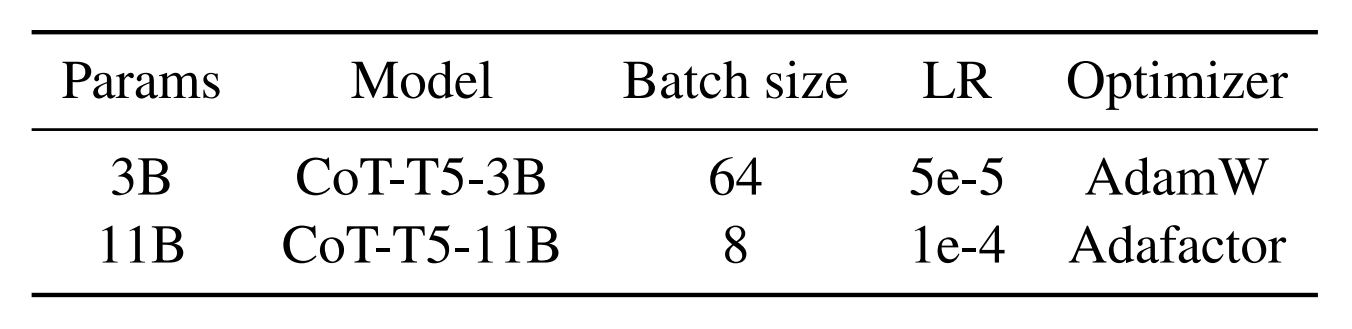
- accumulation step: 8
- 1 epoch 만 학습
- A100 8개 기준 각각 3일, 7일 걸렸다고 함
프롬프트
[지시사항] ‘Let’s think step by step’ [근거] [정답]
- lets 어쩌고 저쩌고는 학습 및 추론 모두 쓰인다
평가 방식
Classification Task
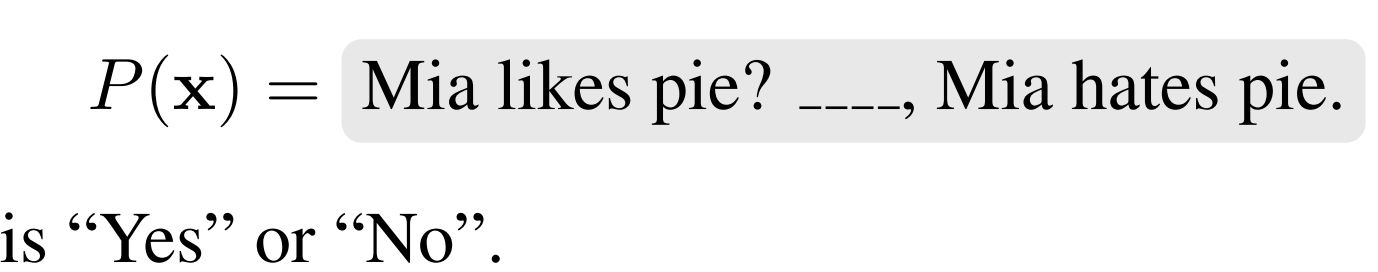
- logit 값을 통해서 가장 높은 라벨을 모델 예측으로 가정한다
- 참조한 논문에서 가져온 그림인데, 원래는 Yes 가 0, No 가 1이었다면 저 빈칸을 가리고 yes 가 나올 확률과 no 가 나올 확률을 구해서 높은 쪽을 모델이 예측했다고 보는 것이다
Generation Task
- 생성한 답을 그냥 직접 대조해서 맞췄는지 틀렸는지 본다. Exact Match 라고 한다.
세부사항
- 가끔 프롬프트를 줘도 근거를 생성하지 않는 경우가 있다. 이걸 강제하기 위해 최소 생성 길이를 8로 두었다고 한다.
- 정답과 근거를 구분하기 위해서 근거 생성 후에 "[ANSWER]" 토큰을 넣어서 그 뒤에 있는 logit 값 혹은 생성 토큰을 정답으로 간주하여 사용했다고 한다. 당연히 학습할 때도 이런 패턴으로 했을 것이다.
ZERO-SHOT Generalization
: 보통 unseen task 에 대해 성능을 측정한다. 학습하지 않은 task 에 대한 성능이 이전 대비 얼마나 올랐는가를 확인하기 위함이다.
Setup #1: CoT Fine-tuning with 1060 CoT Tasks
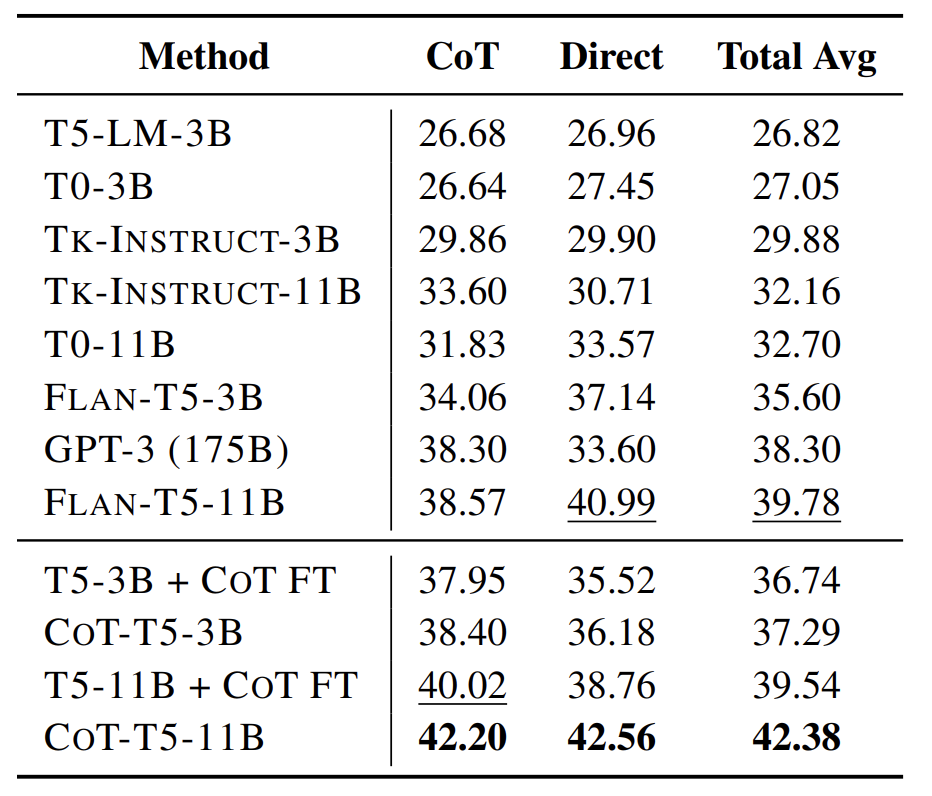
- 27 unseen datasets from BBH benchmark 로 평가했다
- T5-LM: 우리가 아는 기본 T5다
- T0: P3 라는 IT dataset 으로 학습된 모델
- Tk-INSTRUCT: SNI instruction dataset 로 학습된 모델
- T5-3B + CoT FT: 우리 모델과 다른 점은 우리는 FLAN-T5 를 베이스라인 모델로 삼은 거고, 이건 진짜 기초 T5에 본 논문에서 제작한 CoT dataset 을 fine-tuning 한 것이다
- CoT, Direct: 아까 위해서 말했듯이 하나는 생성 태스크, 하나는 분류 태스크 평가를 의미한다. 각각 점수 내보고, 평균도 낸 듯하다.
FLAN vs CoT
- 참고로 FLAN dataset 은 1500만개로, CoT dataset 보다 약 8배 많다는 점을 강조한다.
- 3B나 11B 모두 CoT 가 FLAN 보다 성능이 높다.
- 즉, Instruction Tuning without Rationale(FLAN) 보다 Instruction Tuning with Rationale(CoT)이 뛰어나다.
- 다시 말해 Instruction Tuning 에서 근거를 함께 생성하도록 학습하는 것이 모델 성능을 높인다는 걸 확인할 수 있다.
FLAN vs + CoT FT
- 사실 CoT는 FLAN 모델 위에 한번 더 학습했던 것이다.
- 그래서 진짜 기초 T5 위에서 FLAN 과 CoT 의 대결이 펼쳐졌다.
- 이 역시 CoT 가 FLAN 보다 성능이 높은 것을 확인할 수 있다.
- 하지만 FLAN 으로 한번 학습한 모델을 CoT로 추가 학습한 게 가장 좋긴 하다.
(1) CoT fine-tuning on a diverse number of tasks enables smaller LMs to outperform larger LMs
(2) training with FLAN Collection and CoT Collection provides complementary improvements to LMs under different evaluation methods
- 작은 모델도 CoT fine-tuning 과 함께라면 두렵지 않아. 거대 모델도 무찔러!
- FLAN collection 과 CoT collection 은 상호보완적이다. 어쩌면, Instruction Tuning 한번 하고 그 위에 CoT fine-tuning 까지 해주는 게 성능 향상에 큰 도움이 되지 않을까?
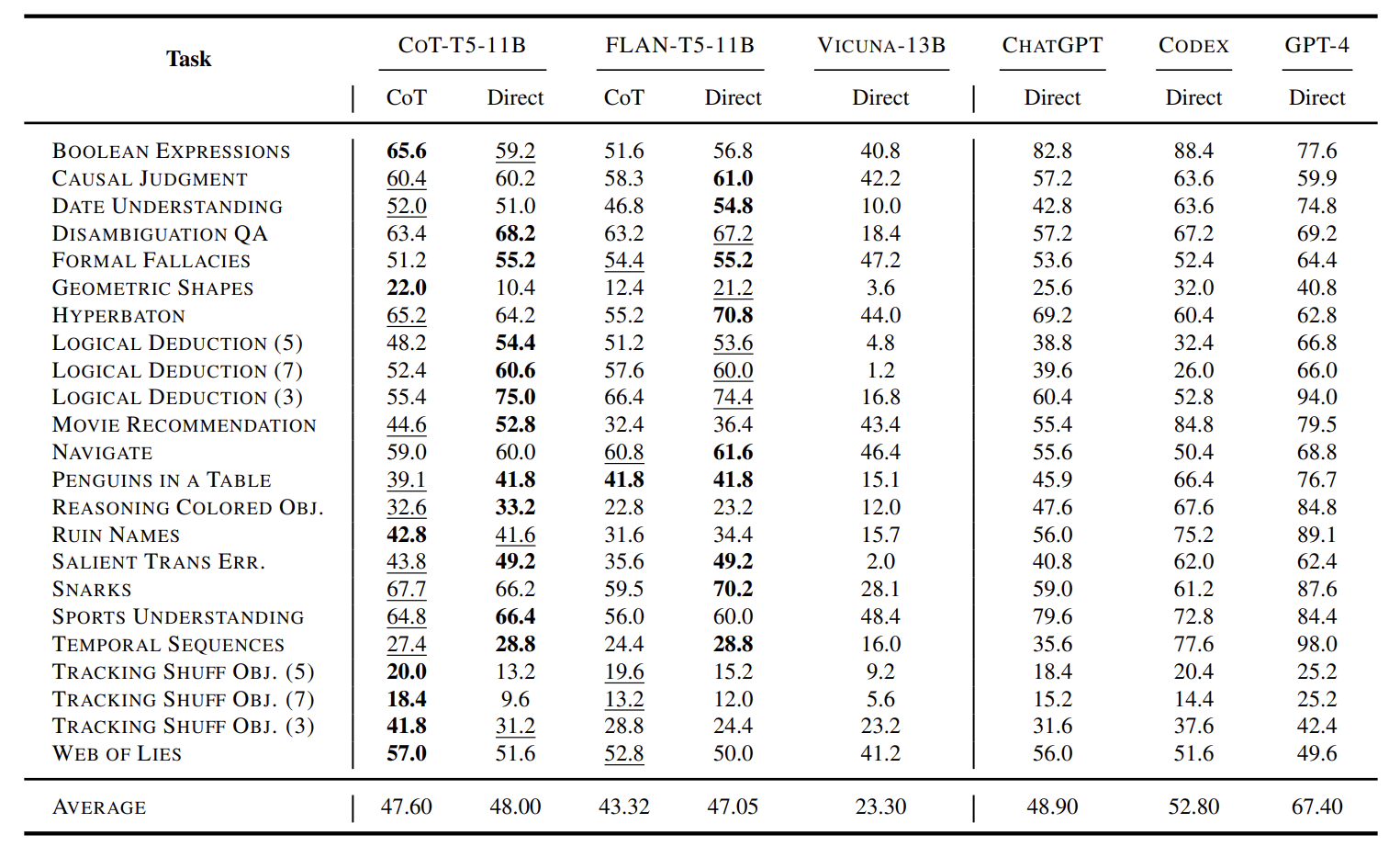
- 자신감이 붙었는지 ChatGPT, CODEX, GPT-4 랑 붙는다
- 23 unseen classification datasets from BBH benchmark 로 평가한다
- 볼드체는 1등, 밑줄은 2등이라고 한다.
- 딱 봐도 CoT 쪽에서 1, 2등이 많이 몰려있다. 단 ChatGPT, CODEX, GPT4 는 등수경쟁에선 빠진다.
- 가장 아래쪽 평균 성능을 보면 CoT가 거대모델과 어깨를 나란히 하려고 한다.
(그 와중에 GPT4 는 어깨 안 내어준다) - FLAN 기준 CoT 가 23개 task 중 17개를 이겼다
- 재밌는 건 Vicuna 는 긴 대화를 위해 만들어진 모델인데 관련 태스크에서 성능이 가장 낮았다.
Setup #2: CoT Fine-tuning with 163 CoT Tasks (T0 Setup)
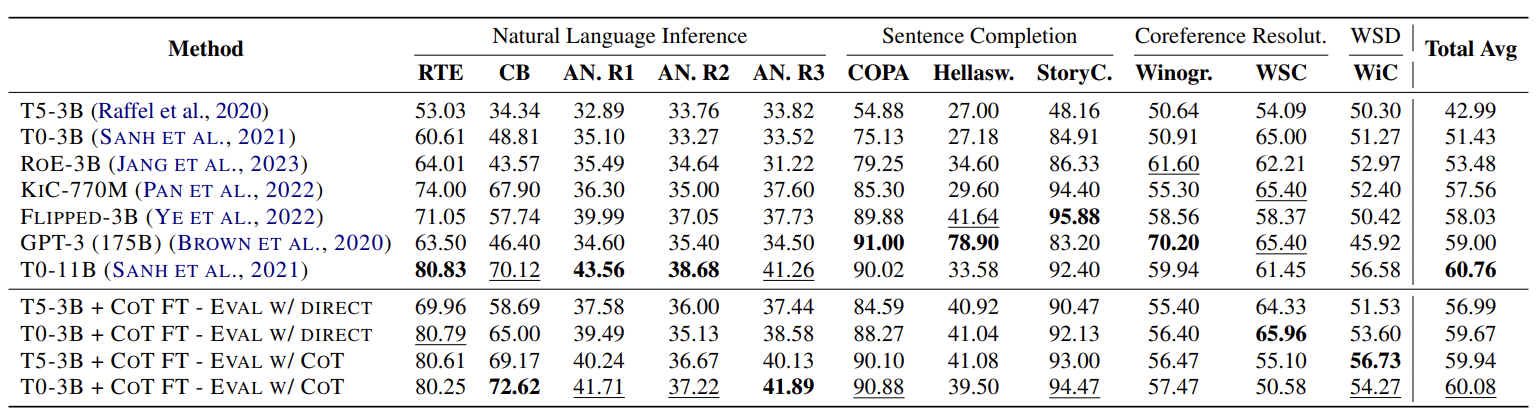
- RoE-3B: a modular expert LM that retrieves different expert models depending on the unseen task 이라고 적혀 있는데, unseen task 를 잘 풀 수 있는 모델을 찾아서 그 모델로 문제를 푸는 모델이라는 말 같다. 근데 장담 못함...
- KIC - 770M: KB(Knowledge Base 같은데 지식 DB가 아닐까?) memory 에서 정답을 찾도록 instruction tuning 된 모델
- Flipped: output label 에 과적합되지 않도록 반대로 output label 을 넣었을 때, instruction 을 생성하는 모델. (취지는 이해하는데 채점은 어떻게 한거지? 이건 논문을 읽어봐야 할 것 같은데, 일단 저는 안 해요 호호)
T5-3B + COT FT outperforms T0-3B by a +8.24% margin
- T0 는 p3라는 12M 개의 데이터셋으로 학습한 모델이다.
- T5 는 p3의 일부로 만든 CoT dataset 644K 개를 학습했다.
- 즉, 18배나 많은 데이터셋으로 학습해놓고 T5가 이겼다는 것은 Instruciton Tuning Dataset 암만 써봐야, CoT dataset 이 훨씬 훌륭하다는 것.
Setup #3: Multilingual Adaptation with CoT Fine-tuning
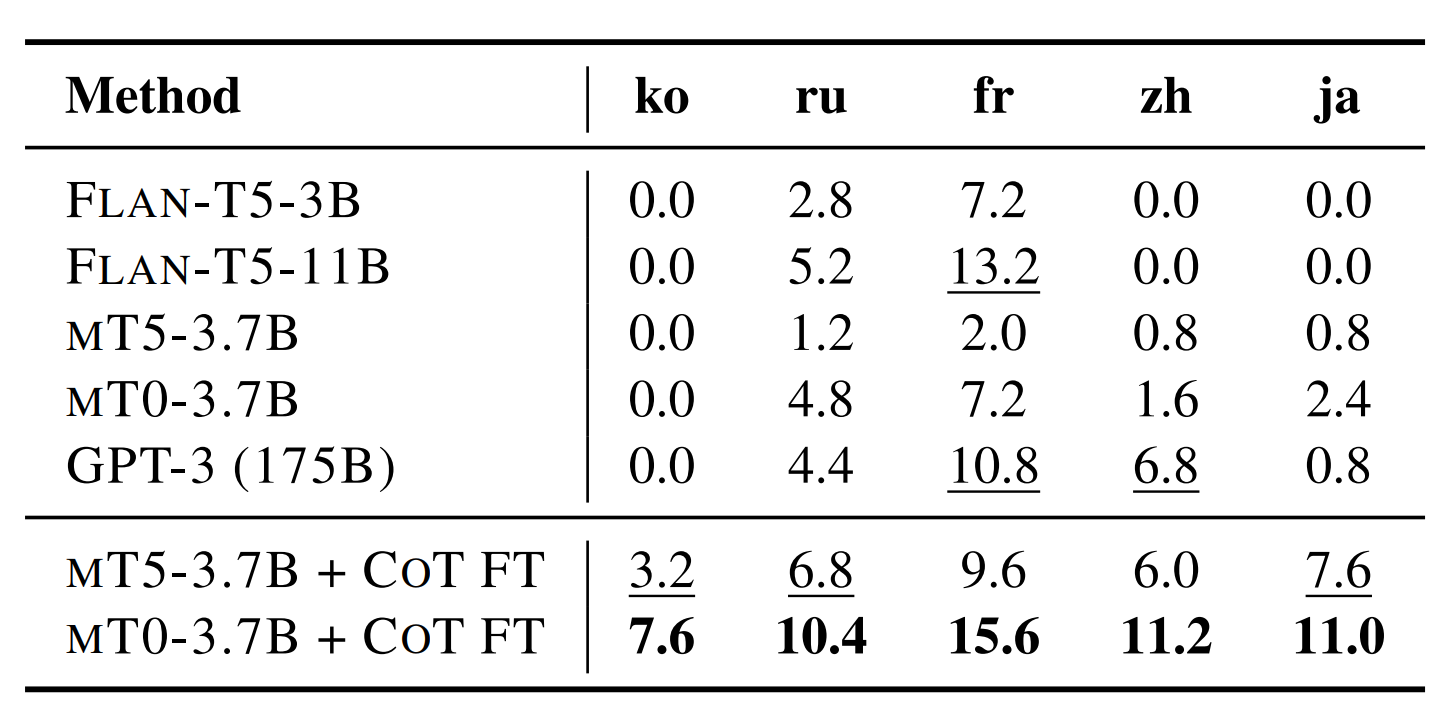
- MGSM 은 원래 10개 언어에 평가하는 데이터셋인데 그 중 5개만 재미로 실험해봤다고 한다 (toy experiment)
- FLAN T5: 거의 대부분 영어로 학습한 instruction tuning 모델
- mT5: 다양한 언어로 학습했지만, instruction tuning 은 없는 모델
- mT5 + CoT FT: CoT collection 을 ChatGPT 로 언어별로 60K ~ 80K개 번역해서 학습한 모델
- 성능표만 봐도 확실히 많이 올랐다는 걸 알 수 있다
- 단, 이 실험은 다양한 언어를 한번에 학습한 모델이 성능을 측정한 게 아니라 언어별로 학습해서 측정한 거라서 한계가 있다.
- 이 실험은 언어에 관계 없이 CoT 형태 학습이 추론 능력을 많이 향상시켜준다는 걸 보여준다고 한다.
- 즉, 언어를 넘나드는 추론 능력이 생겼다는 가설과는 무관하다고 명백히 짚고 넘어간다.
FEW-SHOT Generalization
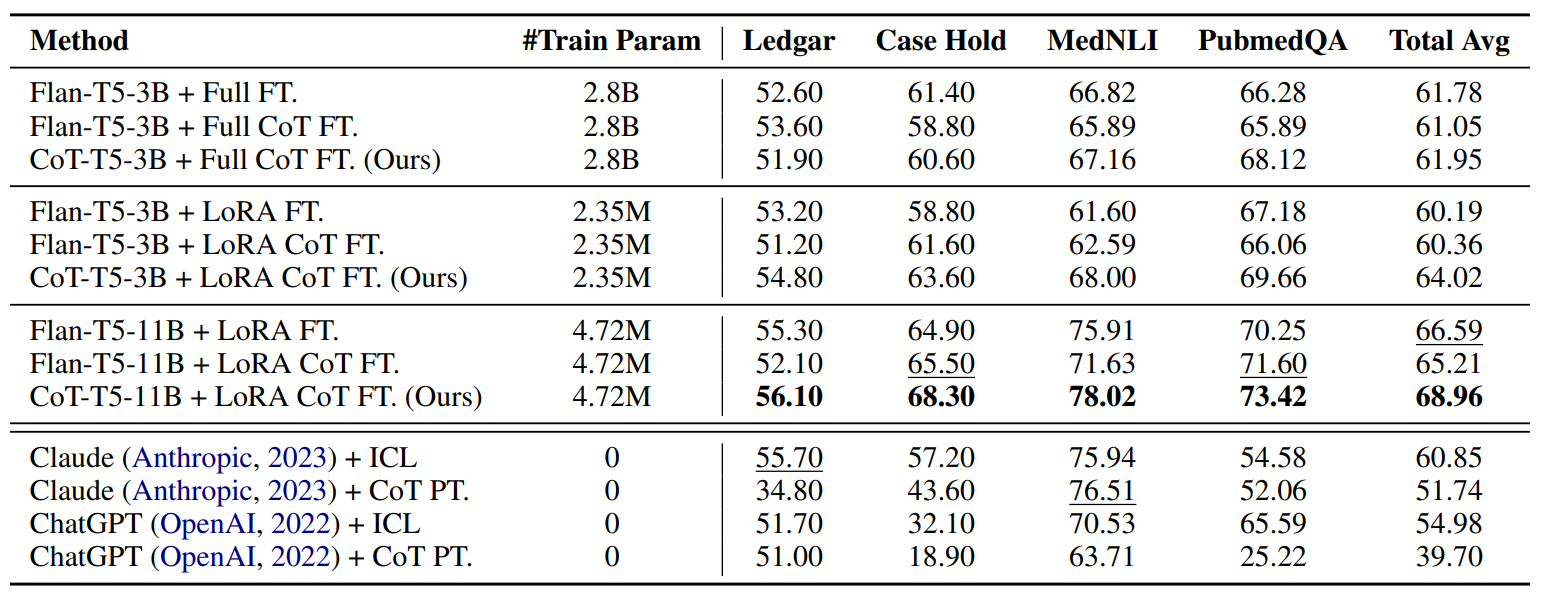
- 64개의 예제를 무작위로 뽑아서 학습했다고 한다.
- 3개의 seed 성능 평균을 냈다고 한다.
- In Context Learning 처럼 예제를 프롬프트에 제공한 게 아니라, 실제로 학습한 거다. 그리고 학습 방식이 CoT Fine Tuning 이다.
- Claude 나 ChatGPT 는 거대 언어 모델이니까 fine tuning 은 없다. 대신 In Context Learning 을 통해 예제를 제공했다고 한다. 최대 길이가 허락하는 대로 예제 개수를 꽉 채웠다고 한다. "+ ICL" 은 그냥 근거 안 물어보는 프롬프트 형태, "+ CoT PT" 는 근거를 함께 생성하라고 요구하는 프롬프트 형태로 물어봤다고 한다.
Effect of LoRA
- FLAN 같은 경우엔 full fine tuning 이 좋았는데, CoT T5는 오히려 LoRA 가 더 좋았다.
- 저자의 추측으로는 CoT T5는 추론 능력이 생겼기 때문에 오히려 적은 파라미터로 학습하니까 추론 능력을 지킬 수 있었기 때문이라고 본다.
Regular FT vs CoT FT
- FLAN 은 Regular FT 가 더 성능이 좋았다.
- 하지만 CoT T5 는 CoT FT가 더 좋았다. 즉 한번 CoT는 영원한 CoT다. CoT 모델은 그 능력을 계속 활용하기 때문이 아닐까라고 저자는 추측해본다.
Fine-tuning vs. ICL
- 마지막으로 거대 언어 모델에 아무리 ICL 잘 해봐야 Fine Tuning 이 더 좋다는 걸 보여준다
- 이 결과를 저자가 말하길, 데이터셋이 법이나 의료처럼 전문적이라서 예제 자체가 기본적으로 매우 길기 때문에 거대 언어 모델 입장에서는 예제를 몇 개 못 봐서 그런 게 아닌가라고 추측하고 있다.
CoT 분석
- 크게 2가지 질문에 답하고자 실험을 진행했다고 한다.
1. For practitioners, is it more effective to augment CoT rationales across diverse tasks or more instances with a fixed number of tasks?
- 실제로 사용할 때, 다양한 태스크의 CoT 예제를 만드는 게 좋아? 아니면 기존 태스크의 예제를 증강하는 게 더 좋아?
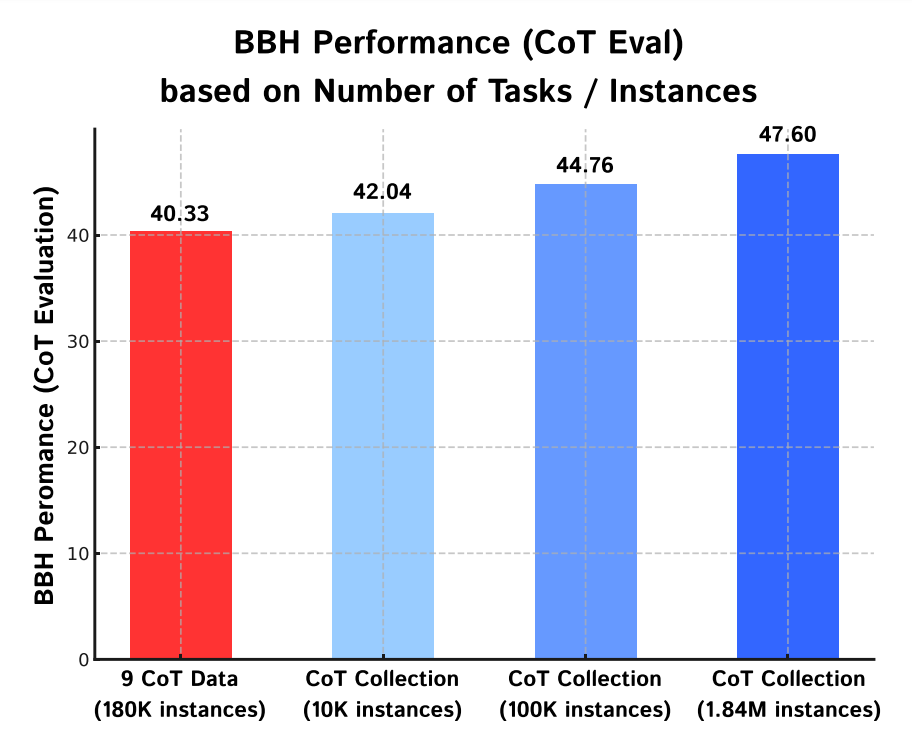
- 첫번째 빨간 막대는 태스크 개수를 9개로 제한하되, 최대한 많은 예제로 학습시켰다. 18만개 말 다 했다. 근데 다른 모델보다 낮다.
- 다른 모델은 1060개 태스크 중 무작위로 뽑아서 개수를 점차 늘려봤다.
- 이 실험을 통해 CoT 데이터 증강이 비록 다른 태스크라도 성능 향상에 도움이 된다고 볼 수 있다.
2. During CoT fine-tuning, does the LM maintain its performance on in-domain tasks without any catastrophic forgetting?
- CoT 학습이 그렇게 좋다는데, 과연 학습하는 동안 기존의 지식을 까먹지는 않을까?
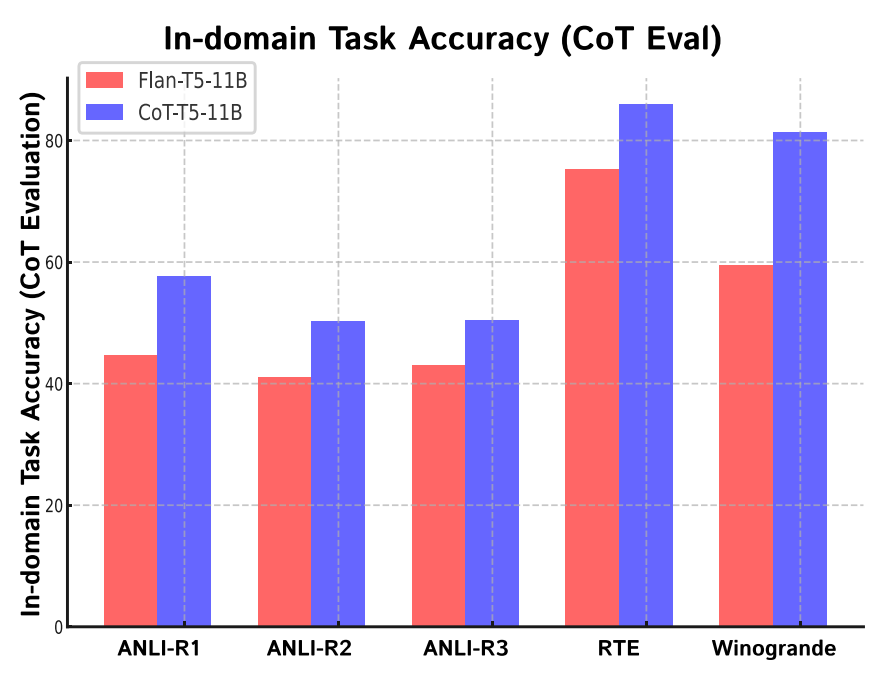
- (이 실험에 대한 해석은 정확하지 않을 수 있으니 주의해서 읽어주세요)
- FLAN-T5가 학습했던 task 5개로 평가했다.
- CoT-T5는 FLAN-T5에서 CoT Fine Tuning 을 했기 때문에, 그새 잊었다면 성능이 낮아져야 한다.
- 하지만 성능이 오히려 올랐음을 보여준다. 즉, CoT FT는 기억력 쇠퇴를 일으키지 않는다.
- 라고 하기엔 문제가 있다고 저자는 지적한다. 사실 저 태스크들은 CoT dataset 을 만들 때 포함된 거라서 정말 엄밀하게 해보고 싶다면, "FLAN-T5가 만들어질 때 쓰였으면서도" 동시에 "CoT Collection dataset 제작 시에 연관되지 않은 태스크"로 진행을 해야 한다고 말한다.
- 근데 그건 future work 에 두기로 했다나 뭐라나. 그래서 이 실험은 사실 몰라도 그만이다.



