논문명: VLIS: Unimodal Language Models Guide Multimodal Language Generation
논문 링크: https://arxiv.org/abs/2310.09767
VLIS: Unimodal Language Models Guide Multimodal Language Generation
Multimodal language generation, which leverages the synergy of language and vision, is a rapidly expanding field. However, existing vision-language models face challenges in tasks that require complex linguistic understanding. To address this issue, we int
arxiv.org
핵심 위주로 정리합니다.
3줄 요약
- 요즘 멀티모달 모델? 언어 모델 하나, 비전 모델 하나 이렇게 붙이는 정도다
- 그러다보니, 언어 능력이 솔직히 혼자일 때보다 떨어졌다....
- 그래서 언어 모델(text only model)과 멀티모달 모델의 능력을 합치겠다
결과 미리 맛보기: VLM(Vision Language Model) vs VLIS(ours)

- Named Entities: VLIS 는 사진 속 인물이 축구 선수라고 말하는 정도에 멈추지 않고 마라도나라고 말한다
- Distractors: 관련 없는 그림이나 헷갈리는 그림을 제공해도 정확하게 답변한다
- 확실히 기존 멀티 모달 모델보다 언어 능력이 뛰어나다
어떻게 한거임?
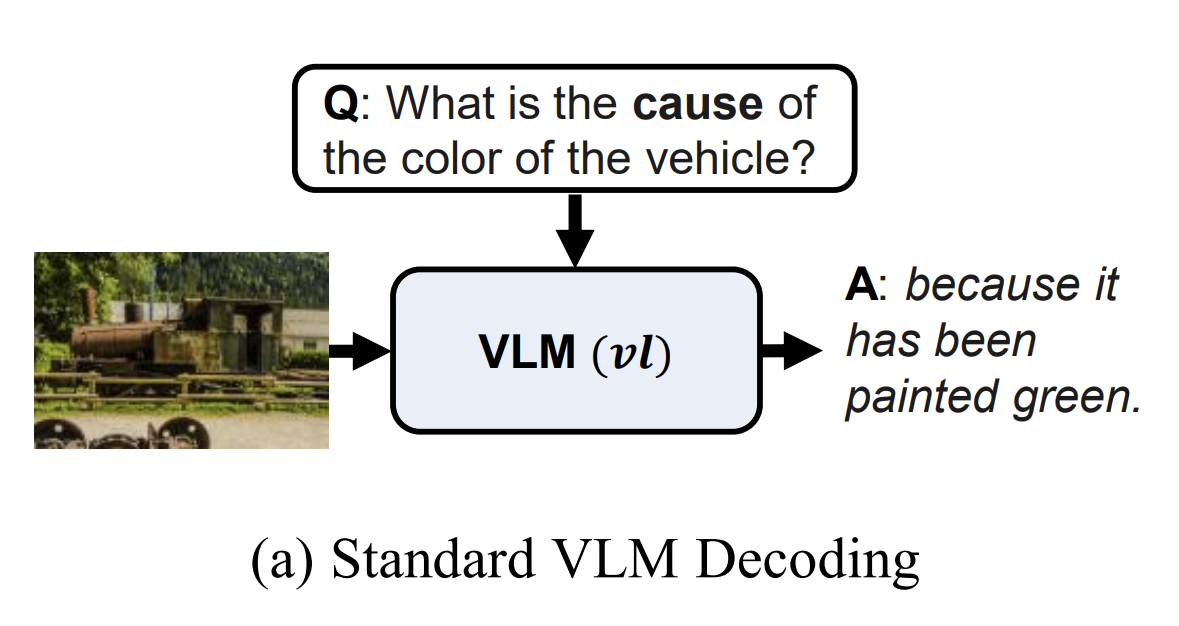
- 위 그림은 멀티 모달 모델 VLM 이 흔히 추론하는 방식이다
- 그냥 텍스트, 이미지 넣어서 추론하는 느낌이다
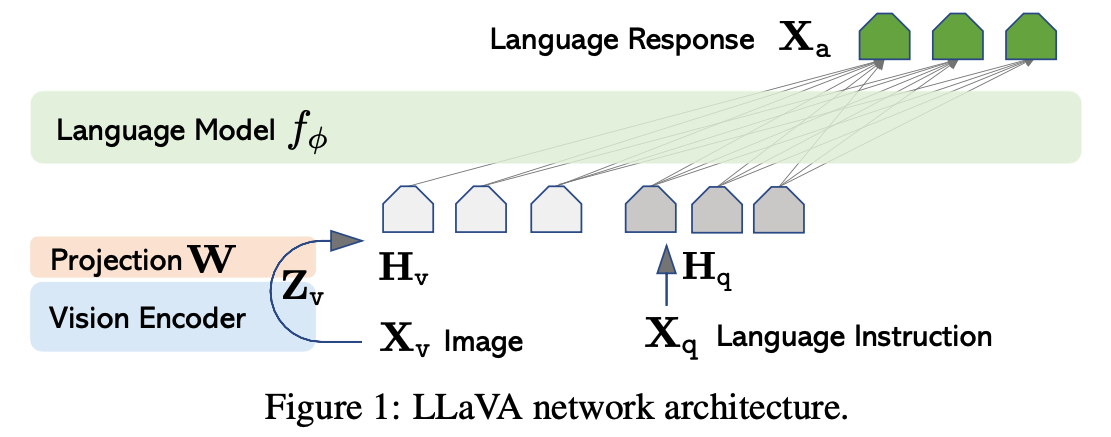
- 대표적인 VLM 으로 LLaVA가 있어서 가져왔다
- 제일 위에 언어 모델이 있다.
- 텍스트: 그냥 평소 넣듯이 넣는다
- 이미지: 이미지는 이미지 인코더 거치고, projection layer W를 통해 차원만 맞춰서 언어모델에 넣어준다

- 본 논문은 Text-Only LM 을 가져온다
- 논문의 제목을 잘 봐라. ' Unimodal Language Models' 이 'Multimodal Language Generation' 을 안내한다고 했다
- 즉, VLM이 생성할 건데 Text-Only LM이 도와준단 뜻이다
- 위 그림에서 녹색 부분이 Text-Only LM의 분포고, PMI는 VLM에서 구한 것이다
- 수식은 뒤에서 볼 거니까, 여기선 이렇게 생각하면 된다
아, Text-Only LM 형님이 잘하시니까 분포를 활용해서 VLM이 답변 생성할 때 도움을 받는 느낌이구나
수식으로 설명 좀
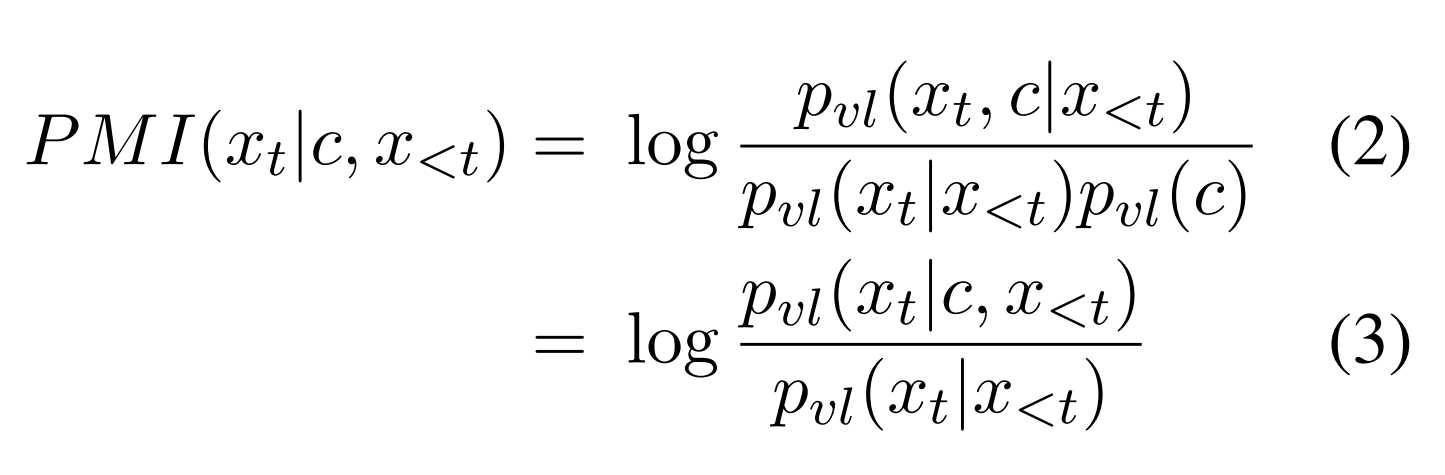
정의
- Pvl: Vision Language Model 의 분포 P라는 뜻
- x: 텍스트
- c: 이미지. 텍스트가 주인공이니까 이미지를 문맥, 맥락 정도로 보는 것 같다
- t: 현재 t번째 토큰이 생성될 차례라는 뜻
해석
- 일단 (2)에서 (3)으로 넘어간 건 모든 토큰에 곱해질 거니까 상수라서 지운 것 같음 (아님 말고)
- 분모: 이미지 안 주고 텍스트만 줬을 때 생성할 확률
- 분자: 이미지와 텍스트를 함께 줬을 때 생성할 확률
- 그렇다면 PMI 값이 크다는 건, 이미지에 의해 생성 확률이 증가한 토큰이다
- 즉, PMI가 높다면 멀티모달 모델이 보기에 해당 토큰이 이미지 정보에만 담겨 있어 중요하다고 알려준 셈이다
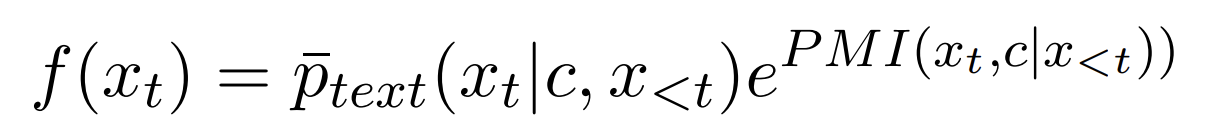
정의
- Ptext: text only model 의 확률 분포
해석
- 원래 텍스트 모델의 분포에 멀티 모달 모델이 속삭이는 셈이다
- 예를 들어, "내 장래희망은" 까지 생성했다고 치자
- 그냥 text only model 은 "화가" 로 답하려고 했다.
- 근데 멀티모달 모델이 이미지를 보니까 축구공, 운동 등이 보인다.
- 그래서 멀티모달 모델의 PMI score 상, "축구선수" 이 높다.
- 그래서 최종적으로 곱해보니, 가장 높은 확률은 "축구 선수"가 되어 이미지를 반영한 답변을 하게 되는 셈이다.
정성 평가

- 신기하긴 한데, 아인슈타인 나도 긴가민가한데...?
실험도 굉장히 많이 했는데, 한번 찾아보시길 :)



