논문명: Cap4Video: What Can Auxiliary Captions Do for Text-Video Retrieval?
논문 링크: https://arxiv.org/abs/2301.00184
Cap4Video: What Can Auxiliary Captions Do for Text-Video Retrieval?
Most existing text-video retrieval methods focus on cross-modal matching between the visual content of videos and textual query sentences. However, in real-world scenarios, online videos are often accompanied by relevant text information such as titles, ta
arxiv.org
3줄 요약
- 현실에선 비디오에 제목도 있고 태그도 있으니
- 캡션 생성 모델을 통해 비디오 관련 텍스트 정보를 만들어서
- 함께 retrieval 할 때 활용하자
논문 설명은 아래로 내리시면 있습니다.
잠시 사적인 이야기를 기록하고자 합니다.
해당 논문은 CVPR2023 에 등재되었을 뿐만 아니라, 2.5% 안에 들어서 HIGHLIGHT 로 지정되었다. 이 이야기를 하는 이유는 반성과 자신감 때문이다. Video Retrieval 을 연구하는 도중, 함께 회의에 들어선 적이 있었다. 그때 이 논문의 존재를 모르고 caption 활용에 대한 아이디어가 나왔었는데, 나를 포함한 사람들은 반응은 회의적이었다.
"그건 Caption Model 의 성능이지, Novelty 도 없는 것 같은데?"
하지만 이 논문을 읽으며 생각이 바뀌었다. 시작 단계에서 아이디어를 날카롭게 판단하기보다는 구체화하고 믿어주는 게 훨씬 중요하다는 것을. ChatGPT도 그랬을 것이다. 그 결과가 처참하다면 엄청난 양의 돈과 시간을 허비하게 되는데도 믿어주었다. 정답을 선택한 것이 아니라 선택한 것을 정답으로 만들기 위해 노력했다.
비록 석사를 하며 2년밖에 연구를 하지 않지만 내가 진정 배워야 할 태도는 냉소적이고 비판적인 자세가 아니라 열린 마음으로 서로를 믿고 그 믿음이 실현될 수 있도록 열렬히 노력하는 것일 테다.
등장 배경
- 현실에선 비디오에 영상뿐만 아니라 제목이나 해시태그 등 다양한 정보가 있는데
- 연구에선 그걸 활용하지 않고 오로지 비디오 임베딩으로만 승부해.
- 그래서 비디오이외에도 부가적인 텍스트 정보를 추출해서 함께 사용하겠어.
어떻게 부가적인 텍스트를 얻을 것인가
- 링크(URL)을 통해서 크롤링하여 다 긁어온다. 하지만 데이터셋에 작성된 링크가 만료된 경우가 있어 활용할 수 없었다.
- ZERO SHOT Caption Generation Model 을 통해 자막을 만들어서 사용하자. 이 방법을 사용하기 때문에 코드에서 'title' 이라고 표기된 변수들이 실제론 caption 을 의미하는 경우가 많다.
이 논문에선 3가지를 기여한다

1. 데이터 증강
- 원래는 query 와 video 이렇게 한쌍이었다. 그런데 caption 이 추가되면서 (video, query, caption) 이 하나로 묶였다.
- '현실 세계에선 대체 텍스트, 제목 등 다양한 정보들이 있을텐데 활용하는 게 좋지 않을까?' 발상에서 출발했다고 한다.
2. Video Embedding 정보 강화
: 이건 video 와 text 사이의 상호작용(interaction)이라고 적혀 있어서 직관적으로 이해하기 어려운데, 그림을 보면 쉽다.

- 주황색: 프레임 임베딩 초록색: 자막 임베딩
- 자막 임베딩과 프레임 임베딩을 다양한 방식으로 합쳐서 강화한다
- 예컨대, SUM 같은 경우 각각 임베딩에 더해서 강화시킨다
- 나머지 방법들은 MLP나 TRANSFORMER 를 통해 강화시킨다
- (video, caption) 쌍이 갑자기 생겼으니 활용하는 방식인데, 이때 뻔하게 손실함수를 사용한 게 아니라 임베딩을 합친 것이 인상적이다
3. Query - Caption Matching

- query 와 caption 을 임베딩하여 유사도를 구하고 이를 보조하는데 사용한다
- 여기서 핵심은 비디오의 개입 없이 자연어 데이터만 사용했다는 점
- 그리고 [CLS] token embedding 을 통해 cosine similarity 를 구한다
Loss 는 어떻게 생겼는가
- Contrastive Learning Loss 는 적어도 Video Retrieval 에선 다 똑같다
- Q2C는 query 가 주어졌을 때, B개의 caption 중 유사도를 구하는 것
- C2Q는 caption 이 주어졌을 때, B개의 query 중 유사도를 구하는 것
- 신기하게도 딱 반반 영향을 주면 성능이 좋다.

- 아래 비디오와 쿼리는 위와 동일해서 생략
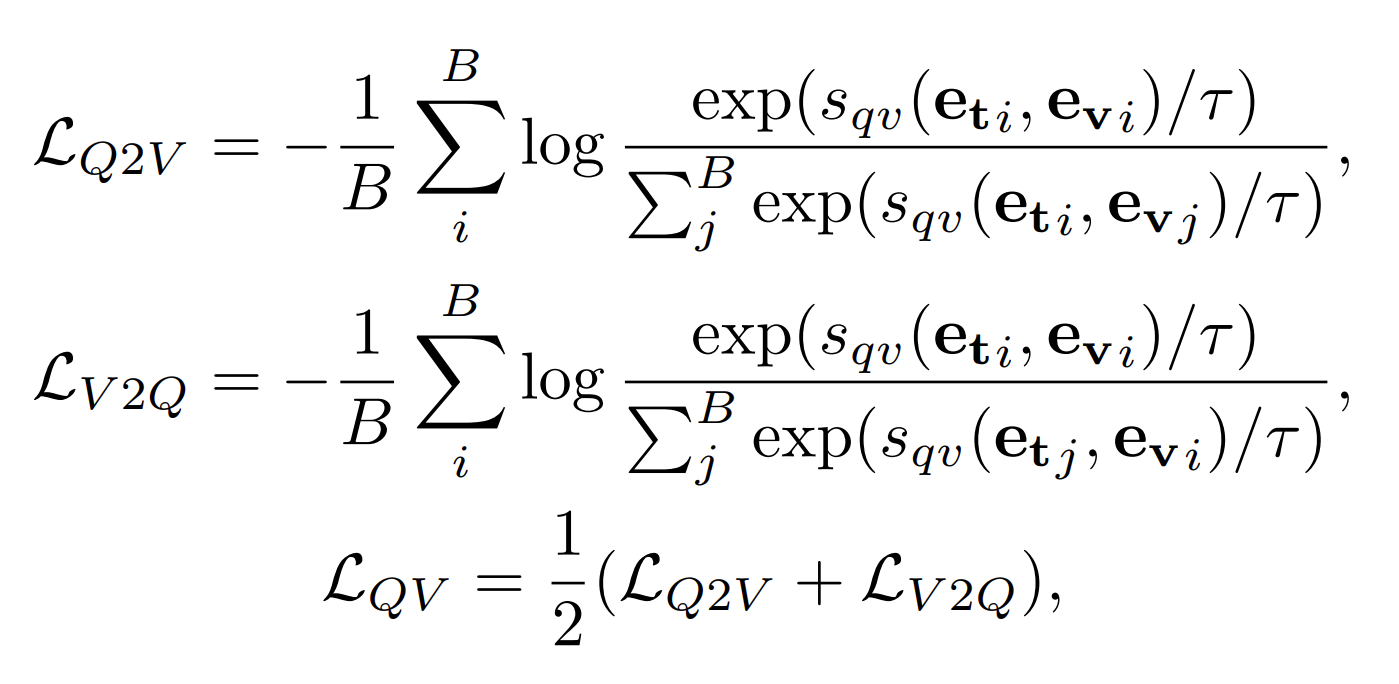
- 이렇게 (query, caption) 과 (video, query) 로 loss 구해서 마지막에 합친다
- 흥미로운 점은 (caption, video) 는 없다는 점
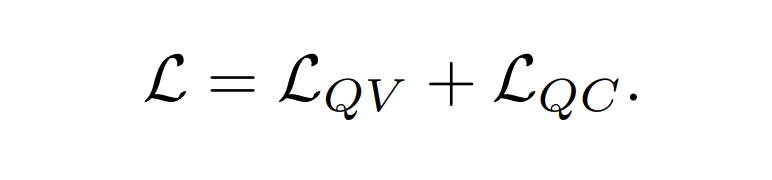
모델 구조
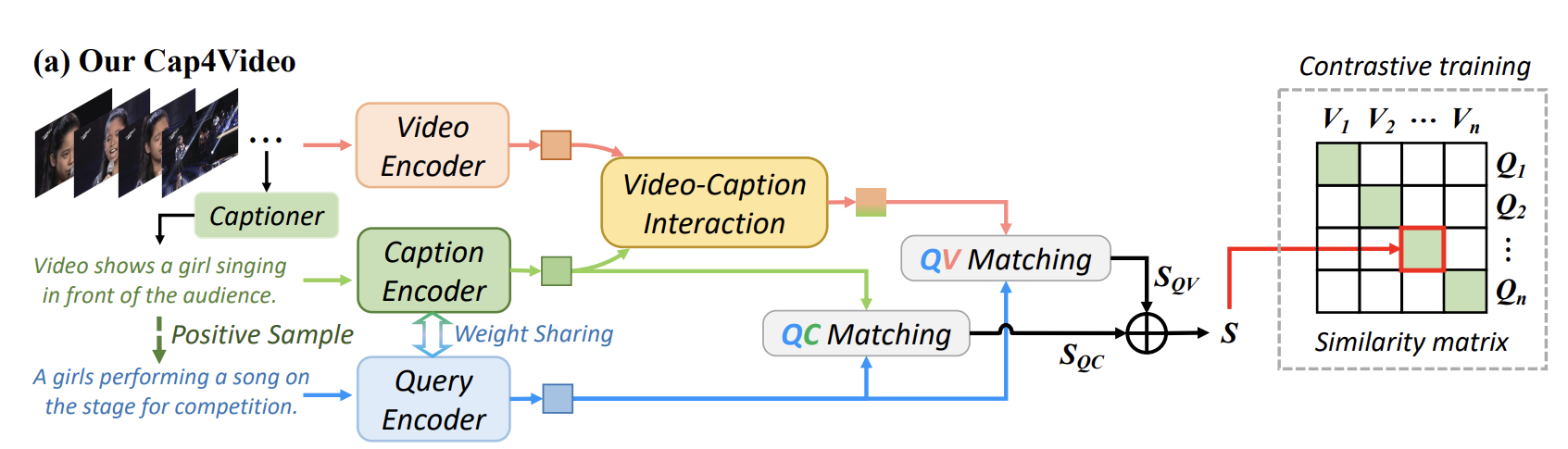
- captioner 를 통해서 caption 생성
- video, query, caption 모두 encoder 를 통해서 각각 임베딩
- video-caption interaction: 기존 비디오 임베딩에 caption 임베딩을 적절히 반영함
- QV matching: query, video 유사도를 통해 loss 구하기
- QC matching: query, caption 유사도를 통해 loss 구하기
실험
: 데이터셋마다 실험했는데 당연히 성능이 좋단 이야기뿐이라서 그냥 그림만 넣었다. 개인적으로 Ablation Study 가 더 중요한 것 같아서 궁금한 사람들은 글을 내리시면 됩니다 :)

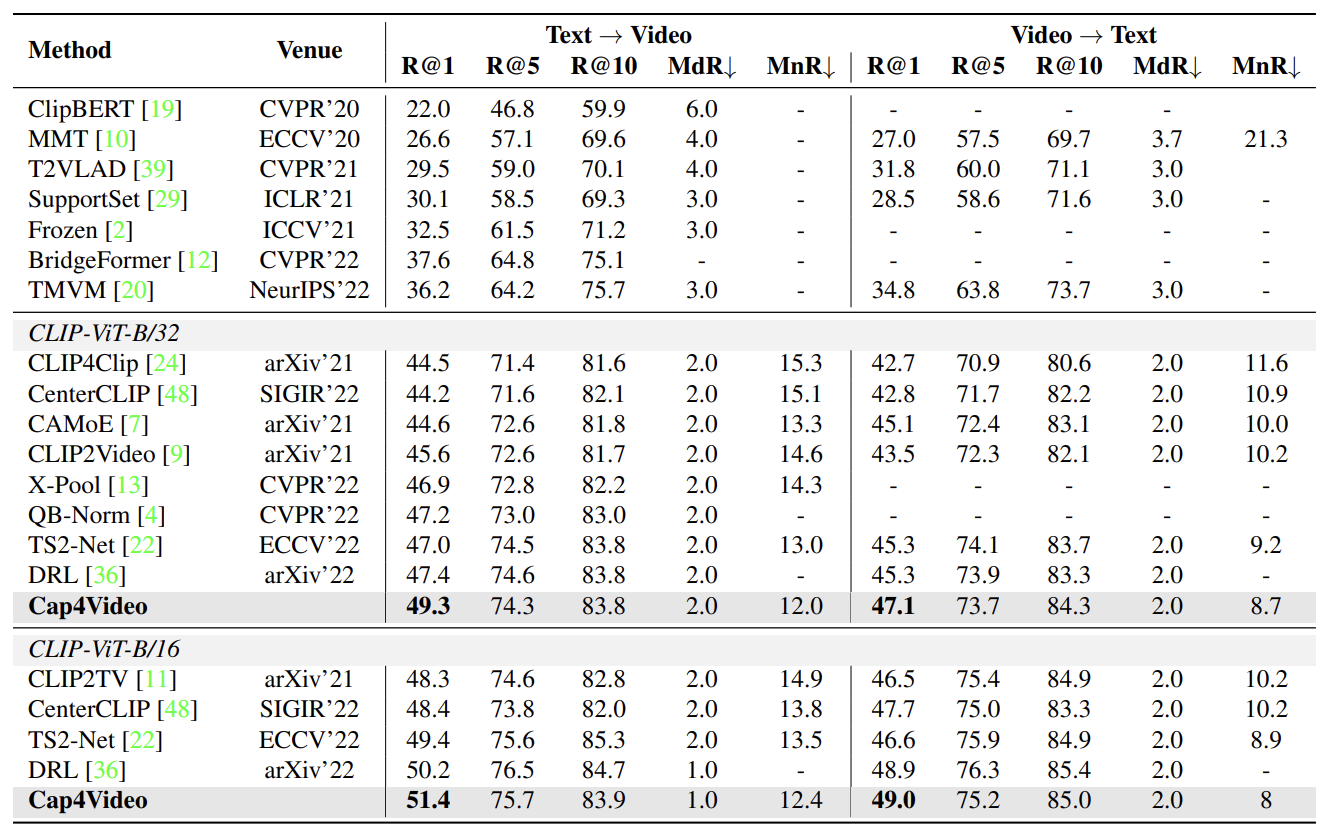
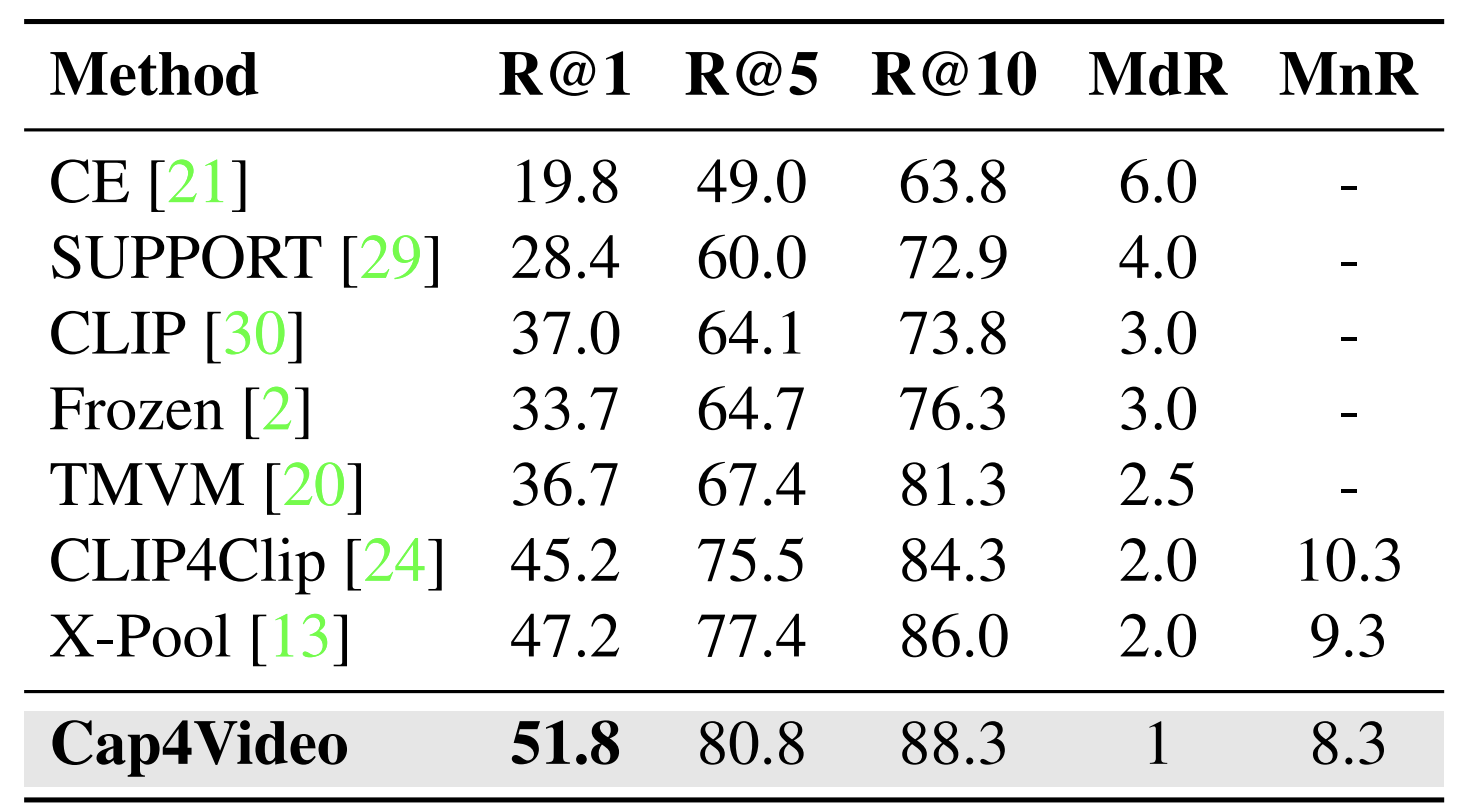
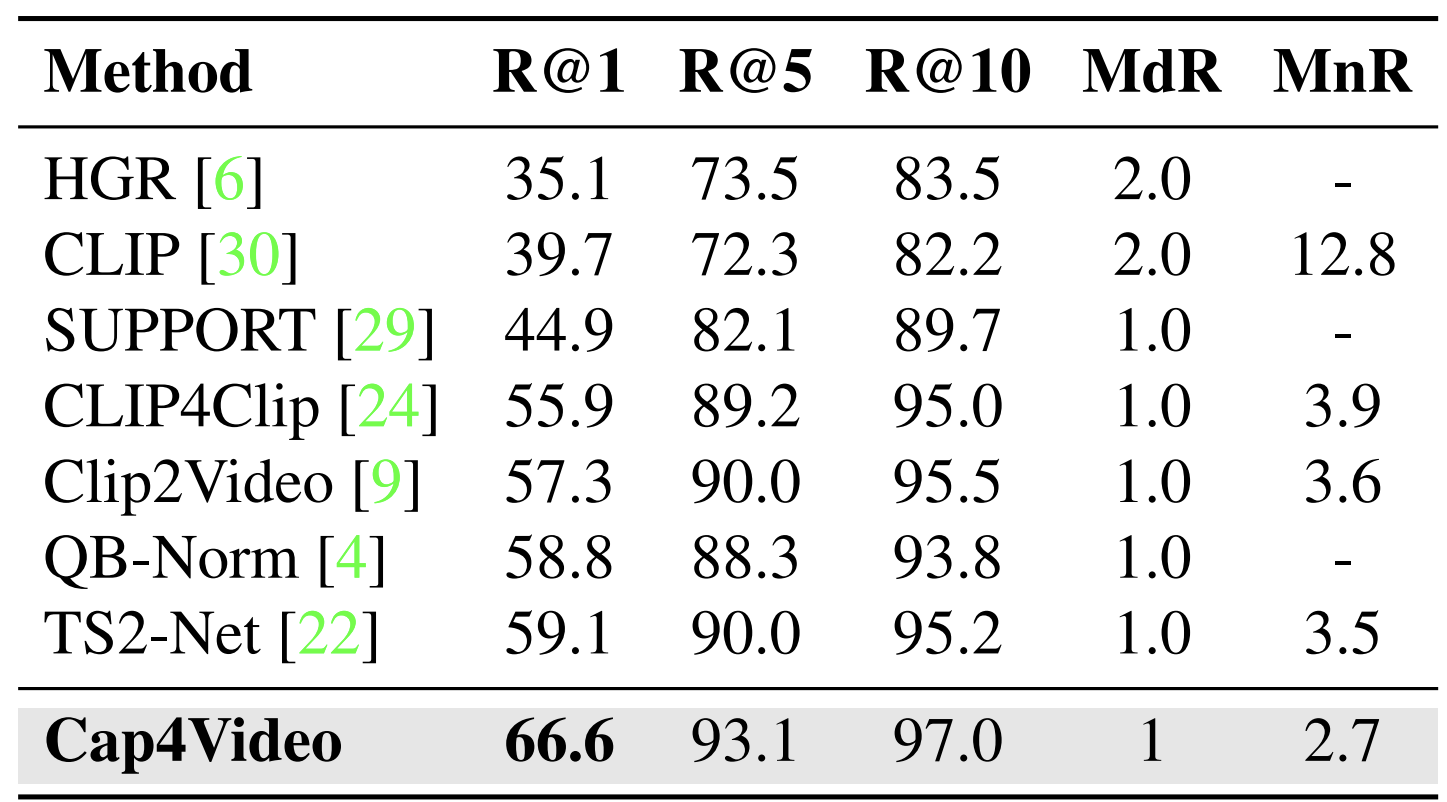

- 최근 Video Retrieval 에서 inference 할 때 DSL 처럼 성능을 높이는 방법을 사용하는데, 본인들은 그런 거 안 썼다. 순수 실력이다 이런 이야기를 하고 있다.
- DSL은 dual softmax loss 인데, 이거 써서 성능이 5%나 오른 논문들을 몇 번 봤었다.
Ablation Study

- 실험 보기 전에, global matching 과 Fine-grained matching 을 알아두면 좋다
- Global embedding matching: 비디오는 프레임 평균 임베딩을 사용하고, 쿼리는 [CLS] embedding 을 사용한다
- Fine-grained embedding matching: 비디오는 프레임별로, 쿼리는 단어별로. FC 는 nn.linear, Max 는 max pooling 이다. 각각 similarity 를 세부적으로 구한다고 보면 된다.
Auxiliary Caption as Data Augmentation
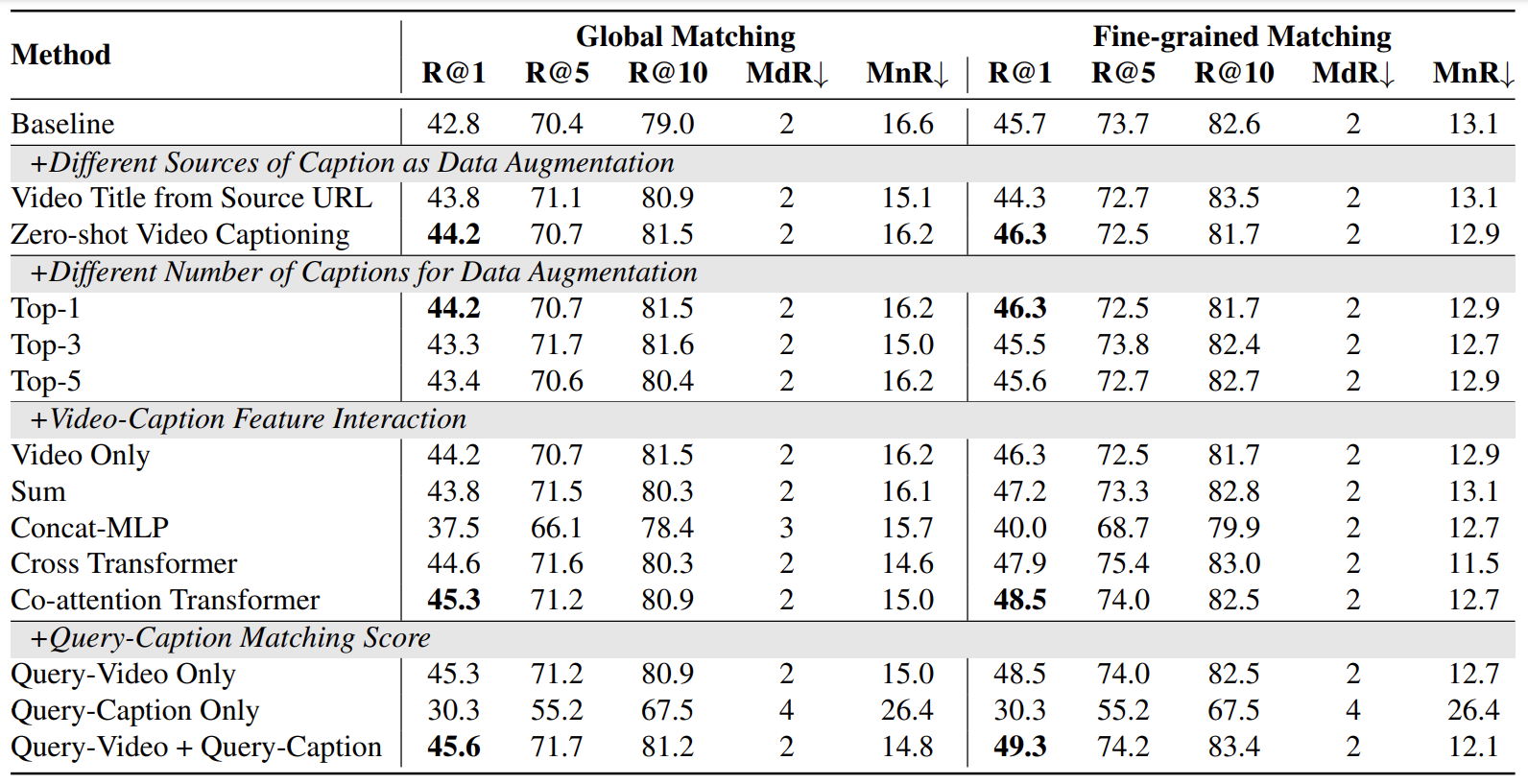
Different Sources of Caption as Data Augmentation
- 먼저 Video Title 을 URL 에서 추출한 것과 captioner 를 사용한 것과 비교했다. 둘 다 성능이 올랐는데, caption이 더 높다.
Different Number of Captions for Data Augmentation
- captioner 가 30개 정도 만들었는데, text encoder 를 통해서 정답과 가장 가까운 1개만 썼었다
- 하지만 그 개수를 늘려본다면 어떨까 하는 마음에서 실험해본 것 같다
- 개수를 늘릴수록 성능이 내리는 것으로 볼 때 1개면 충분하다고 저자는 말한다
Video-Caption Feature Interaction
- caption embedding 을 video embedding 보완을 위해 사용했다
- 방법은 위처럼 4가지가 있다
- 성능이 Co-Attention Transformer 가 가장 좋았다고 한다
- 논문에 4가지 방법의 성능에 대한 저자의 해석이 있는데, 사실 결과주의적 해석이라 끼워맞춘 느낌을 지울 수 없어서 옮기진 않았다. 궁금하신 분들은 직접 보시길 :)
Query - Caption Matching Score
- 확실히 보완했을 때 성능이 가장 높다는 걸 확인할 수 있다
Benefit on Both Online and Offline Videos Scenarios

- Online: 제목(video title)이 있는 웹사이트에 올라간 비디오 데이터
- Offline: 휴대전화에 저장된 것처럼 제목은 딱히 없이 저장된 비디오 데이터
- 위 두 가지 경우 모두 Cap4Video 는 효과를 발휘한다고 말한다. 온라인이면 제목을 함께 넣어서 사용하면 되고, 오프라인이면 caption 을 생성해서 사용하면 되기 때문이다.
- 위 성능표는 활용하는 게 성능이 더 오른다는 걸 보여준다

- caption 을 추가하면 성능이 오르는 예시를 넣으면 저자는 논문을 마친다
- 해당 논문에서 나온 zero shot captioner 써봤는데, 잘 만든 자막도 있는데 매우 못 만들기도 한다. 괜히 30개 만들고 제일 좋은 걸 text encoder 필터링한 게 아니다.
논문은 여기까지다. 다들 좋은 하루 되시길 :)



