논문명: Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval
논문링크: https://arxiv.org/abs/2202.03384
Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval
With the recent boom of video-based social platforms (e.g., YouTube and TikTok), video retrieval using sentence queries has become an important demand and attracts increasing research attention. Despite the decent performance, existing text-video retrieval
arxiv.org
계기: 모든 논문이 다양한 과정을 거치고, 서로 도움을 주고 받으며 성장하기 때문에 의미가 있다. 하지만 최근에는 AI가 실용화가 되는 것을 보면서 어느 정도 실용성을 고려한 논문들이 더 흥미롭게 느껴진다. Video Retrieval, 즉 Video 역시 언젠가는 정복해야 하는데 무겁다는 단점이 있어서 실용적인 논문을 읽어보게 되었다.
Dual Encoder 은 문제가 있다
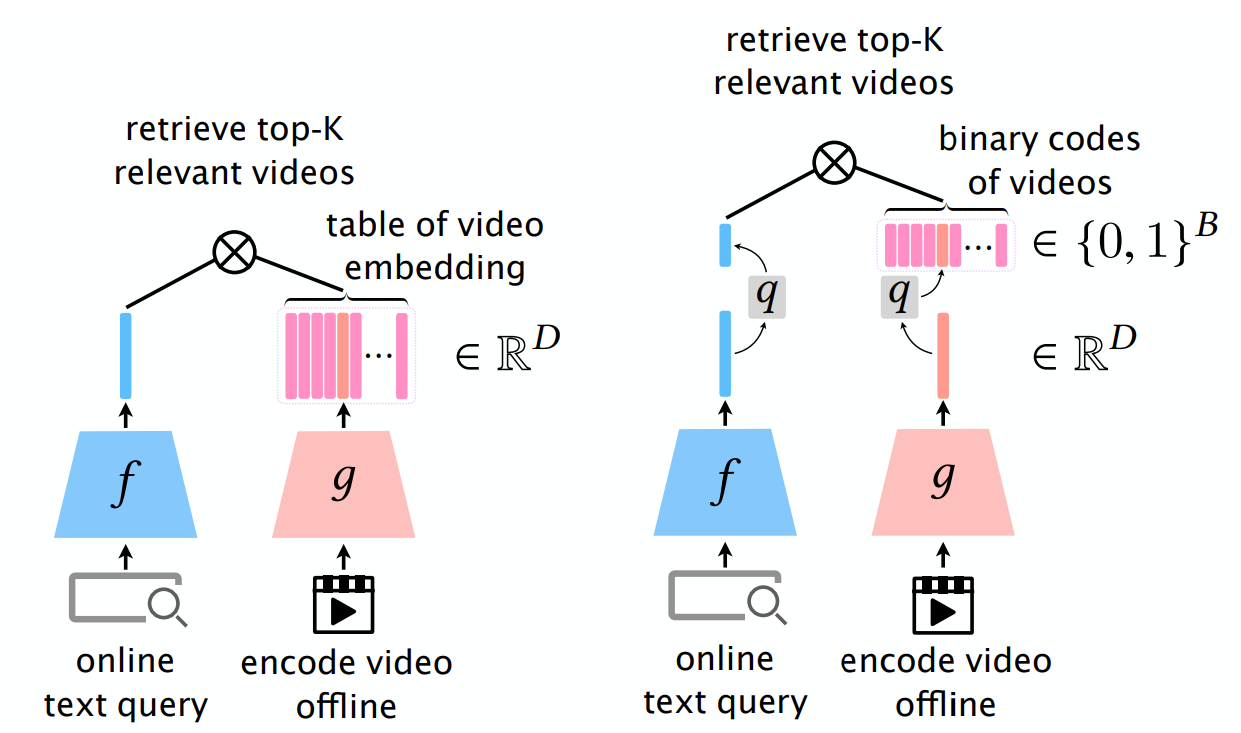
- 왼쪽이 그림이 일반적인 dual encoder 의 형태다.
- dual encoder: 텍스트는 텍스트 인코더를 거쳐 임베딩되고, 비디오는 비디오 인코더를 거쳐 임베딩된다. 그 후 cosine similarity 를 통해 유사도가 가장 높은 텍스트와 비디오를 연결한다. 보통 검색어(텍스트)를 넣고 관련된 비디오를 찾는 게 일반적이며 이런 task 를 Video Retrieval 이라고 한다.
- 왼쪽의 문제는 실제 세상에서 사용할 때, 모든 비디오를 임베딩하는 과정이 비싸고 저장하는 비용도 만만치 않다는 것이다. 그 이유는 실수 형태의 큰 차원 벡터로 저장되기 때문이다.
- 오른쪽 그림이 본 논문에서 제시한 방법인데, 양자화를 통해서 텍스트 임베딩과 비디오 임베딩의 효율성을 개선한다고 한다. 단, 당연히 벡터의 경량화는 정보 손실로 이어져 성능 저하가 발생하는데 이를 최소화하는 노력을 했을 것이다.
구조
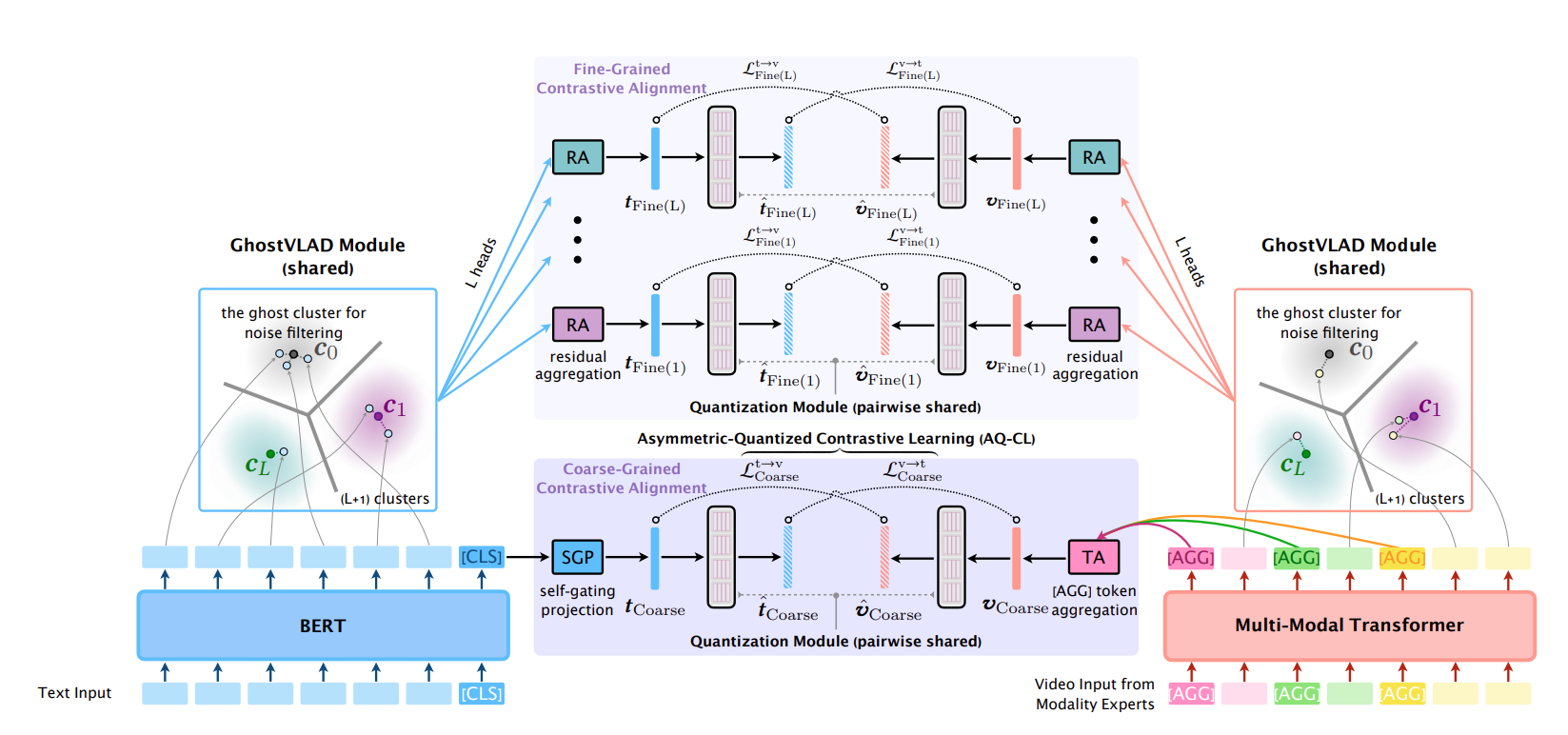
- 한숨이 나오지만, 특히 논문도 한숨이 나오지만 하나씩 읽어보겠다.
- 먼저 왼쪽과 오른쪽에 BERT와 Multi-Modal Transformer 가 있다.
BERT & Multi-Modal Transformer(MMT)
- BERT: 텍스트를 임베딩한다. 이때 결과물로 토큰별 임베딩과 문장 전체를 대표하는 임베딩 [CLS] token 이 생긴다.
- MMT: 음성, 영상 등 다 입력으로 넣는다고 한다. 사실 자연어 처리이외에는 잘 모르지만, 어떻게든 넣어서 임베딩을 만들었을 것이다. BERT와 마찬가지로 전체를 대표하는 임베딩 [AGC] token 과 부분을 대표하는 임베딩이 생겼다.
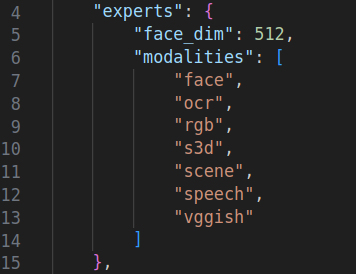
- 각 특성의 전문가들로 임베딩을 한다고 했었는데, 코드의 config 를 보면 얼굴 정보 등 다양하게 임베딩하나보다.
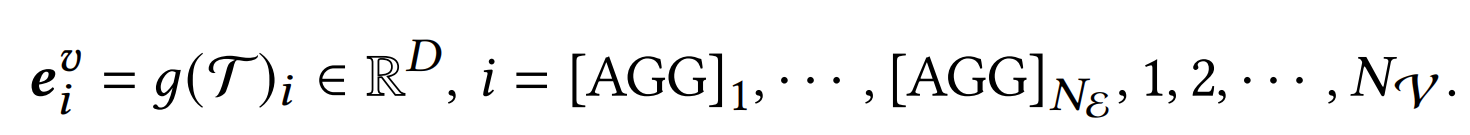
- AGG: "help of a bunch of modality experts" 로서 전문가 개수만큼 AGG 토큰이 만들어진다고 한다. 옆에 보면 Ne 만큼 만들어졌다고 표기되어 있다. 그 뒤에 1 ~ Nv 는 부분 토큰이다.
- g: MMT를 대표해서 저렇게 표기했다. 그와중에 T가 아니라 V인데, 오타가 있다.
이 논문 어려워죽겠는데 비디오를 입력으로 넣어야 하니 g(V) 라고 해야 하는데 g(T)라고 표기했다 세상에.
Coarse-grained Representation
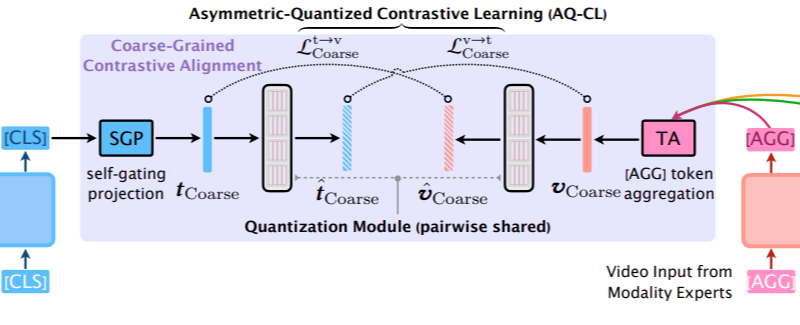
- Coarse-grained: fine-grained 와 반댓말이다. 즉 여기선 대충 전체 대표 임베딩 뽑아서 학습하겠다는 말이다.
- 텍스트 대표: CLS 를 self-gating projection 을 통해 전체적인 정보를 더 응축했다. 그걸 tCoarse 라고 표기한다.
- 비디오 대표: 비디오는 이미 AGG가 전문가개수만큼 뽑혀서 그냥 합쳤다. average pooling 이다.
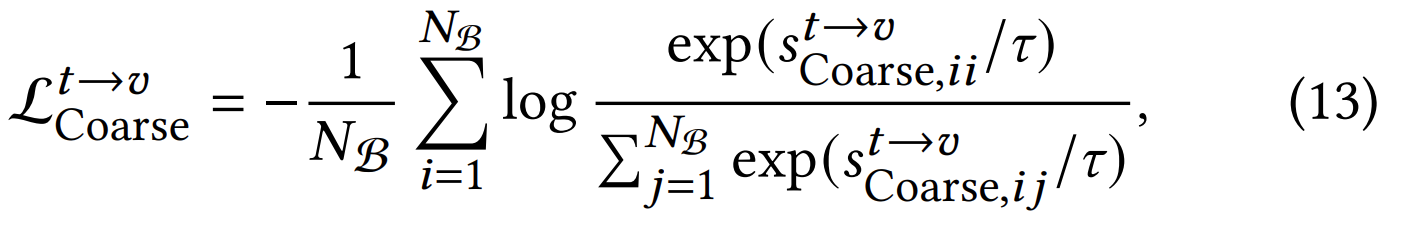
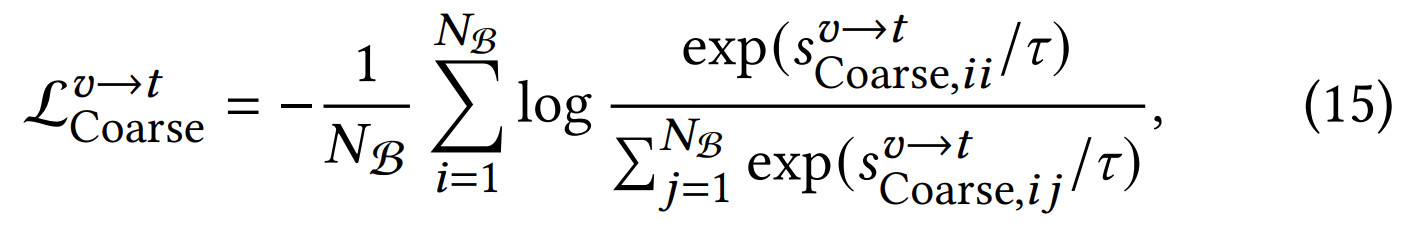
- 그림이 헷갈리게 생겨서 서로 임베딩을 같게 하나? 이 생각들었는데 loss 보면 그냥 화가 난다.
- loss 는 그냥 유사도 구해서 정답이 높고 나머지는 낮추는 방식으로 학습한다.
- 이 분야에선 text 를 넣었을 때 여러 비디오 중 정답을 찾는 방식(13)과 비디오를 넣었을 때 여러 텍스트 중 정답을 찾는 방식 (15) 둘 다 학습하기 때문에 loss 가 2개다.
GhostVLAD

- Ghost 의미: 이게 참조 논문이 있는 걸 보니, 다른 논문에서 제시한 모델인 것 같다. Clustering 을 L + 1 개만큼 만드는데, 여기서 C0가 중요하다. C0는 불필요한 임베딩을 모아두는 역할을 한다. 마치 이미지로 치자면 아무 의미 없는 배경을 의미한다. 그런 배경 임베딩과 같이 쓸모 없다고 판단된 임베딩들은 C0에 모이도록 학습한다. 그래서 uninformational 혹은 ghost 라고 부른다.
- 우선 비디오도 GhostVLAD를 하지만 각각 진행하는 것을 보인다. 그러면서도 shared 라고 적혀있으니, 파라미터를 공유한다는 점을 알 수 있다.

- 1단계: 텍스트 임베딩을 D차원으로 옮기기 위해 linear projection 을 통과시킨다.
- 2단계: W에 곱해서 각각 어느 클러스터에 속하는지 점수를 구한다.

- 3단계: layer 별로 텍스트임베딩을 통해 layer 를 대표하는 임베딩 r 을 구한다.
- 참고로 t는 숫자가 아니고 text 를 의미하는 영단어다.
- 여기서 핵심은 l 이 0 을 구하지 않는다는 것. 즉, ghost centroid 에 대한 임베딩을 뽑지 않는다.
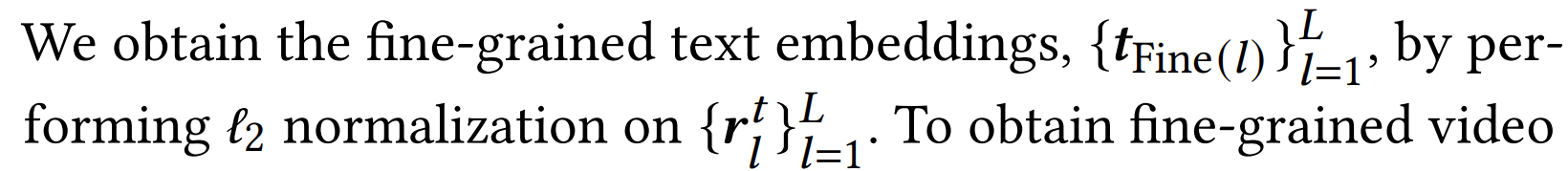
- 여기에 batchNorm 만 적용해주면 tFine 완성이다. 비디오도 동일한 과정을 거친다고 저자는 이야기한다.
Fine-grained Representation

- 아니, 이 그림이라면 이제 이해가 된다. 아까 Coarse-grained 랑 똑같다. 그걸 클러스터 개수인 L번 더 하는구나.
- "아 클러스터별로 뽑은 대표 벡터를 비디오와 텍스트끼리 또 뽑아서 Contrastive Learning 하는 거구나."
Trainable Quantization Modules
- 잠깐, loss 를 구하기 전에 사실 coarse 와 L개의 fine-grained 임베딩을 구한 후 양자화 모듈을 통과시켰다면?
- 그 양자화 모듈에 대해서 알아야 이 논문의 원리를 비로소 알게 된다고 한다.
- 하긴 학습 과정에서 워낙 많은 벡터를 생성하고 loss 도 여러 번 계산해야 하는데, 그 부분을 개선했겠지?!
- 비디오와 텍스트 모두 동일한 모듈을 통과시켰다고 한다.

- D = Md 라고 가정하자. 예컨대, 512차원 = D 이었다면 M = 8, d = 64 다.
- 그러면, d 만큼 잘라서 벡터를 행렬형태로 표현할 수 있다. 그게 위에 써있는 내용이다.
Codebook

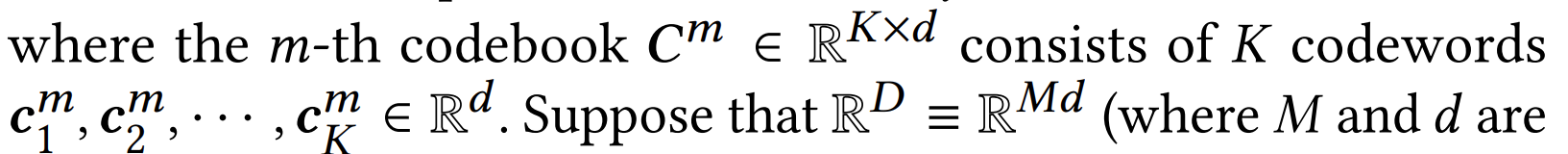
- codebook 은 내가 처음 들었던 거지, 양자화 등 이런 분야에선 자주 쓰이는 말이라고 한다.
- M개만큼 코드북이 있고, 각각은 K개의 토큰으로 구성되어 있으며, 1개 토큰의 차원수는 d 라고 한다.
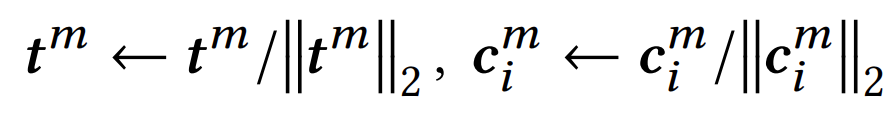
- 1단계: 일단 각각 L2 normalization 을 취한다

- 2단계: 우리가 아는 q, k, v attention 을 취한다.
- query 는 텍스트나 비디오 등 양자화하고 싶은 대상이고, key 와 value 는 코드북의 역할인 것 같다.
일단 여기까지 해야겠다. 이 논문은 왜 이렇게 읽기 싫을까. 오타도 많고 아쉽다. 하지만 사실 내가 귀찮음에 빠졌기도 하고, 주말에 읽어서 그런 것 같다. 다시 정진해야지. 물론 내일부터.



