ChatGPT의 파라미터 개수 공개 논란으로 뜨거운 논문인데, 논문 내용 자체도 좋은 것 같아서 가져와봅니다.
논문명: CODEFUSION: A Pre-trained Diffusion Model for Code Generation
논문링크: https://arxiv.org/abs/2310.17680v1
CodeFusion: A Pre-trained Diffusion Model for Code Generation
Imagine a developer who can only change their last line of code, how often would they have to start writing a function from scratch before it is correct? Auto-regressive models for code generation from natural language have a similar limitation: they do no
arxiv.org
diffusion 관련 내용이 필연적으로 등장하는데, 자세한 수식보다는 개념을 잘 설명한 블로그가 있어 남긴다. diffusion 잘 모르면, 반드시 이 내용이라도 이해하고 읽기 바란다.
https://ffighting.net/deep-learning-paper-review/diffusion-model/diffusion-model-basic/
Diffusion Model 설명 - 기초부터 응용까지
Diffusion Model의 기초부터 응용까지 살펴봅니다. 기초 부분에서는 Diffusion Model의 동작 방법, Architecture, Loss Function을 살펴봅니다. 응용 부분에서는 다양한 Diffusion Model을 알아봅니다.
ffighting.net
초록
- 문제점: Auto-regressive 방식은 이미 생성된 토큰을 다시 고려하는 게 어렵다. 물론 decoding 방식으로 어느 정도 해결하려고 하나, 근본적으로 해결하진 못한다. (사견: 확률 자체가 생성된 문맥을 반영하기 때문에 고려를 안 한다고 보기엔 애매하다. 하지만, 생성된 토큰을 직접적으로 반영하지 않아서 group beam search 등이 그런 문제를 해결하려고 시도한다고 이야기하는 것 같다. Contrastive Search 도 이런 문제를 BERTSCORE로 풀고 있다. 하지만 토큰을 하나씩 생성하는 방식 자체를 제시하진 못했기에 근본적인 해결책이 아니라고 보는 듯하다.)
- 해결책: diffusion 으로 해결하자. 전체를 고려하면서 한번에 생성하기 때문에 생성된 토큰을 동시에 고려한다.
방법
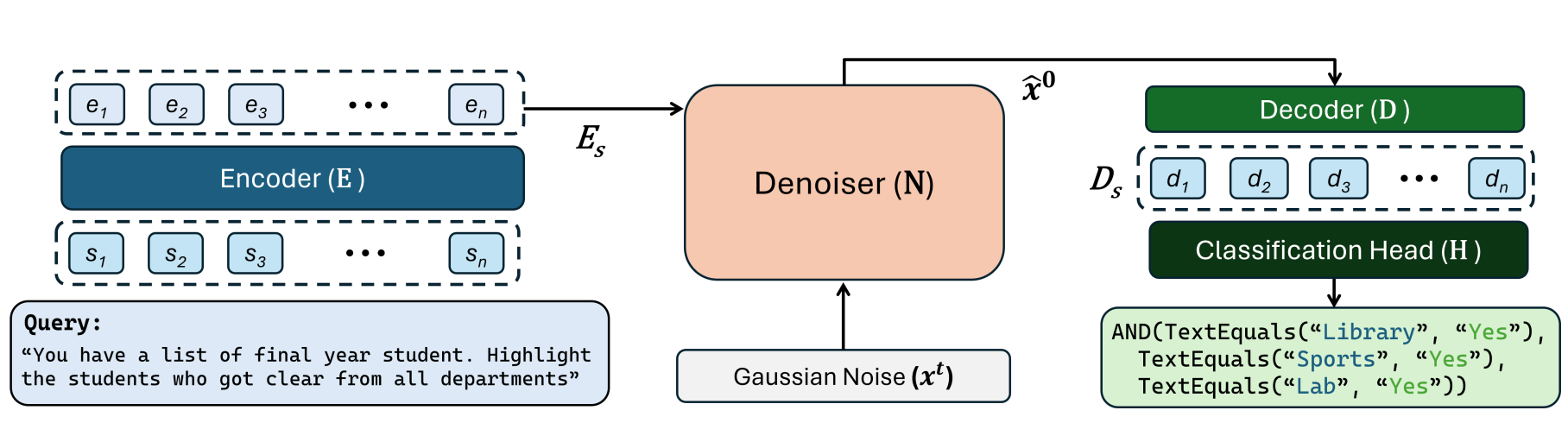
- 이렇게 생겼는데, 단계별로 나눠서 보자.
Encoder

- query: 내용을 읽어보면, 코드 작성 요구사항으로 보인다.
- Encoder: pre-trained CodeT5 encoder
- 차원: 512
- 우리가 아는 자연어처리 모델로 텍스트를 hidden states vector 로 임베딩한 결과가 Es 로 표현된다.
Denoiser

- Xt: 여기선 noise 가 낀 code 라고 보면 된다. Es 라는 요구사항까지 함께 반영해서 noise 를 제거하는 과정이다.
- cross attention: Es 와 Xt 사이에서 발생한다. 원래 Xt 를 만들어야 하는데, 요구사항이 반영되어야 하기 때문이다.
- self attention: Xt 끼리 full attention 이 발생한다.
- 구조: 10 layer transformer block
Decoder

- decoder 구조: 6 transformer decoder layer
- classification head: a single fully connected layer
- cross attention: 여기서 또 Es 인 요구사항과 함께 attention 연산을 취한다.
- self attention: x hat 0 자체끼리 full attention 을 취한다. 기존 생성 방식과 다르게 masked attention 이 없이 full attention 을 통해 생성한다. 그러므로 full information 을 전달할 수 있다고 저자는 강조한다.
Classification Head

- we do not perform a search: single layer 니, (H x V) 로 차원변경해서 한번에 확률을 계산해서 가장 높은 값을 취한다.
학습 방식
: 사전 학습과 fine tuning, 2단계로 이뤄져 있다.
pre-training
- 대상: decoder & denoiser (encoder 제외)

- 냅따 loss 를 보여줘서 미안하다. 하지만 이게 훨씬 쉽다.
- 사전 학습 방식은 이 논문을 따라했다고 하니, 참고할 분은 참고할 것.
L이 무엇인가?

- loss 의 첫번째 항은 diffusion 에서 말하는 noise 를 예측하는 것 같고, 마지막 항은 최종 decoder output 과 정답을 비교해서 loss 를 주는 것 같다. 그런데 가운데 등장한 L(y) 가 뭘까?
- L: 지금 encoder 가 없다. 그래서 텍스트를 벡터로 만들 방법이 없다. 그래서 위에 적혀 있듯이, 저자는 코드와 대응하는 벡터를 주려고 임베딩 레이어를 만들었다. nn.embedding 으로 토큰과 대응하는 벡터를 만들되, 학습가능하게 했다고 생각하면 된다.
- 그러면 loss 에서 두번째 항 의미를 알 수 있다. 처음 임베딩 준 벡터와 디코딩된 벡터의 차이를 최소화하려는 것
Two Task
- unsupervised code generation: 이 논문을 인용했는데, 읽어봐도 자세히 모르겠다. 내 생각엔 AutoEncoder 처럼 입력과 출력이 같도록 학습하는 과정으로 보인다.

- CDP(continuous paragraph denoising): 이 논문을 인용했는데, 자세히 나와있지 않아서 장담할 순 없다.
- 위 그림은 문서를 생성하는데, 한 단락을 MASKING 해서 입력으로 넣었다는 말이다. 출력은 MASK된 단락의 임베딩 벡터와 같도록 학습한다. 이처럼 코드에서도 이렇게 MASKING 하는 방식을 기용하는데, 변수명이나 내장함수처럼 중요한 부분을 가렸다고 한다.
그렇다면 Loss 는 어떻게 했나?

- fine-tuning 과 pre-training 의 손실함수는 동일하다
- 단, 위에 적혀 있듯이 Es 가 사전학습 단계에선 존재할 수 없어서 각각 대체했다고 한다.
실험
데이터셋
- python: CoNaLa dataset
- Bash: Bash dataset - NL2Bash
- Excel Conditional Formula: CORNET
설정
- schedule: 이건 noise 줄 때 쓰이는 베타값을 조절하는 방식을 의미하는데, diffusion 방식이 생소하고 신기해서 적어봤다. 이 논문에선 square root noise schedule with 1200 diffusion steps 를 사용했다고 한다
- tokenizer: CodeT5 를 사용했다는데, 아마 코드 전용 토크나이저인만큼 토큰이 다르게 생겼을 것 같다.
- target code length: 128 tokens
- lr: 5e-4
평가지표
- CODEBERTSCORE: bertscore 의 code 버전이다
- bash: template match 지표를 사용한다고 하는데, 솔직히 무슨 말인지 모르겠다
- Excel: 실행한 결과를 비교한다고 한다
성능 비교

해당 논문이 뜨거워진 이유가 바로 ChatGPT 파라미터 개수는 20B로 표기했기 때문이다. 심지어 BING 을 서비스하는 마이크로소프트의 논문인데가, 저자의 요구사항으로 인해 논문이 내려갔다? 이거 이거 더욱 수상하다. 사실 ChatGPT API 속도가 수많은 사람들에게 제공함에도 불구하고 매우 빠른 걸 보면 저 숫자가 합리적으로 느껴진다. 어쨌든 이게 핵심은 아니니 넘어가자.- 매우 적은 파라미터로 준수한 성능을 보이며, top3/5를 대부분 차지했다.
다양성 비교

- 각 모델의 top-5 code generation 사이에 비교를 진행했다
- N-grams 토큰이 얼마나 다양하게 있는가
- Embedding similarity 를 측정할 때 얼마나 낮은가, 즉 유사한 코드인가 아닌가
- Edit distance: 이 논문에서 나왔다는데, 귀찮다... 대충 보자
유효성 비교

- 문법적으로 옳은지 확인했는데, top1 기준 이렇게 차이가 난다. 압도적으로 유효한 결과물을 내놓고 있다.
Abaltion study

- 사전학습 과정 제거시 성능이 떨어진다는 걸 먼저 1번째, 2번째에서 보여준다
- grounding: decoder 없이 denoiser 에서 나온 벡터를 가지고 정답을 예측한 경우를 의미한다. decoder 와 H(classification head)의 중요성을 보여준다.
- Clamping: pick closest vocabulary token at each denoising step 라고 적혀 있는데, 정확히 이해하진 못했다. 여튼 매 단계마다 가장 유사한 토큰을 골랐다면 성능이 저하되었을 것이라고 한다.

- step 이 지나감에 따라 이렇게 자연어 요구사항에서 코드로 변하는 걸 볼 수 있다

- 위 변환 예시를 정밀하게 측정하여 나타낸 그래프다
- 정답과 비교하여 edit distance 를 측정했는데 점점 0에 가까워진다는 건 정답과 유사해진다는 의미다
- CF Rule 이 다른 언어에 비해 빠르게 변환되는 걸 볼 수 있다
단점
- 영어에 국한되었다
- inference 과정이 denosing step 이 커서 오래 걸린다
- 긴 문장의 코드를 생성하는데 어려움이 있다



