논문명: Pre-Training to Learn in Context
논문링크: https://arxiv.org/abs/2305.09137
Pre-Training to Learn in Context
In-context learning, where pre-trained language models learn to perform tasks from task examples and instructions in their contexts, has attracted much attention in the NLP community. However, the ability of in-context learning is not fully exploited becau
arxiv.org
아이디어만 정리합니다.
아이디어
- 기존 Pretraining 은 corpus 를 그대로 가져와서 Language Modeling 을 시도함.
- Corpus 를 그냥 가져오는 것보다 비슷한 task 에 쓰일 법한 문장들끼리 모으는 것이 좋다.
비슷한 task 에 쓰일 법한 문장이라는 게 무슨 말인가?

- 위 코퍼스는 원래라면 그냥 다음 단어를 맞추는 방식으로 사전학습에 쓰였다.
- 하지만 노란색 부분은 왠지 sentiment analysis 에 사용하기 좋아보인다. 파란색 부분은 인과관계 관련 task 에 쓰기 좋아보인다. 붉은 색은 응답 생성할 때 쓰일 것 같이 생겼다.
- 저자는 이렇게 가정한다: 사전학습에 쓰일 코퍼스는 각 문장마다 intrinsic task 가 있다. 즉, 사실은 내재된 task 가 있다고 본다. 이걸 retriever 를 통해 각 문장마다 어떤 task 가 내재되어 있는지 분류한다. 그래서 같은 task 에 쓰일 것 같은 문장들끼리 묶어서 학습하는 게 그냥 학습하는 것보다 좋다는 게 저자의 주장이다.
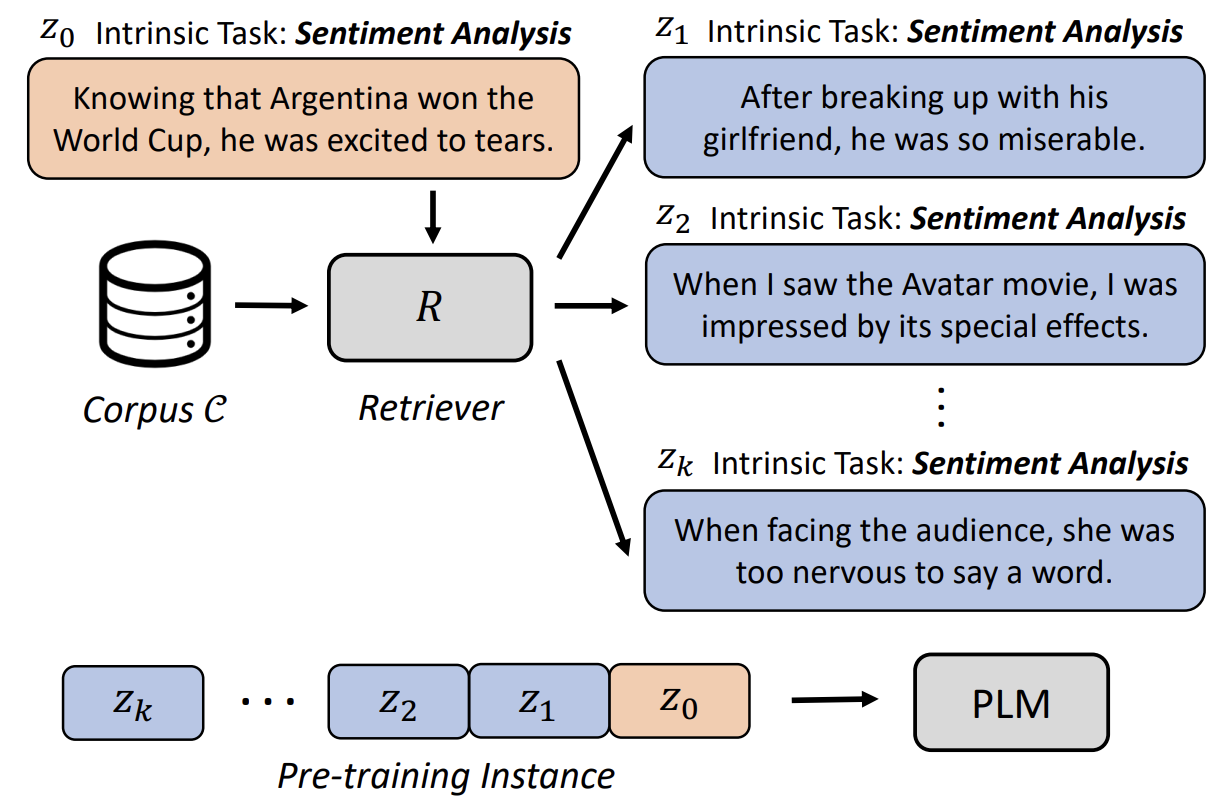
- 위 그림처럼 어떤 문장을 넣었을 때, 그 문장에 내재된 task 와 같은 문장들을 검색해서 붙인다.
- 그 후, Auto-regressive language modeling 을 통해 사전학습을 한다.
이렇게 하면 generality 와 In-Context Learning 성능 모두 좋아진다고 한다.
그렇다면 Retriever 를 어떻게 학습시키는가?
- downstream task 에 쓰이는 데이터셋을 task 별로 가져온다.
- 예컨대, 감정분석에 쓰이는 데이터셋 문장 가져오고, 요약에 쓰이는 데이터셋 문장을 가져온다. 각각 어디서 쓰이는 데이터셋인지 아니까 그걸 contrastive learning 을 통해 구별하는 학습을 retriever 에게 시킨다.

사견
- 사전학습에 쓰이는 코퍼스를 일부 걸러내고 순서를 task 별로 정렬하여 학습하는 방식은 기발하지만, In-Context Learning 성능이 오른 이유와 직접적인 관련이 있는지는 잘 모르겠다.
- 논문 제목이 In-Context Learning 이 아니라 엄연히 따지면 in context 라서, 문맥 속에서 더 잘 배우는 방식을 보여준 것 같다.



