논문명: Unmasked Teacher: Towards Training-Efficient Video Foundation Models
논문링크: https://arxiv.org/abs/2303.16058v1
Unmasked Teacher: Towards Training-Efficient Video Foundation Models
Video Foundation Models (VFMs) have received limited exploration due to high computational costs and data scarcity. Previous VFMs rely on Image Foundation Models (IFMs), which face challenges in transferring to the video domain. Although VideoMAE has train
arxiv.org
배경지식
: 자연어 처리를 주로 공부하는 사람으로서 배경 지식을 일부 정리하겠습니다.
MAE: Masked Autoencoders Are Scalable Vision Learners

- BERT 에서 사용한 Masked Language Modeling 을 이미지 분야에 적용했다고 생각하면 편하다.
- 픽셀 단위는 아니고 패치 단위로 가린 뒤, 가린 부분을 맞추도록 학습한다.
- 이미지 분야에서 finetuning 이 아니라 pretraining 을 사용하는 기법 중 하나다.
- 자연어 처리 분야와 다른 점이 있다면, 공격적으로(agressive) 마스킹하는데 비율이 75%나 된다. BERT 의 MASK 비율은 15% 다.
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training

- 이미지는 무작위로 가려서 맞추게 했지만, 비디오는 무작위로 하기엔 문제점이 있다.
- 위 그림을 보면, 손이나 검정 바닥 같은 경우에 시간이 지나도 여전히 픽셀에 변화가 없다.
- 저런 부분을 가리게 된다면 오히려 손해다. 그래서 VideoMAE 는 tube masking 을 제안한다.
- tube masking 은 모든 프레임이 동일한 위치의 패치를 가리는 방식이다.

- 실제로 논문 부록에 있는 그림인데 이걸 맞출 수 있나 싶을 정도로 가린다.
- 75 ~ 95% 까지 가리는데, 이에 대한 근거는 실험을 통해 밝혀지니 궁금한 사람들은 읽어보면 될 듯하다.
문제점
- IFM, 즉 이미지 영역에서 사전학습된 모델을 쓰자니 도메인 차이가 있어서 시공간적 정보를 제대로 활용할 수 없다.
- VideoMAE 방식은 mask reconstruction 을 해야 하니, 학습이 오래 걸리며 attention 연산때문에 scaling 이 부담된다.
방법
- 이 논문은 기존의 Video Foundation Model 의 pretraining 방식보다 더 효율적이고 성능이 뛰어난 방식을 제시했다.
- 자연어 처리로 비유하자면, RoBERTa 처럼 pretraining backbone model 을 제시한 셈이다.
- Video 분야뿐만 아니라 multi-modal 분야 친화적인 학습방법이다.
- 그래서 Action Recognition, Action Detection, Video Retrieval, Video QA 등 다양한 downstream tasks 에 fine-tuning 하여 골고루 성능 향상을 보였음을 입증한다.
- VideoMAE 에 비해 중요하지 않은(의미가 없는) 토큰들은 마스킹을 하기 때문에 효율적이다.
- VideoMAE 에 비해 decoder 없이 학습하기 때문에 GPU 사용량도 줄일 수 있다.
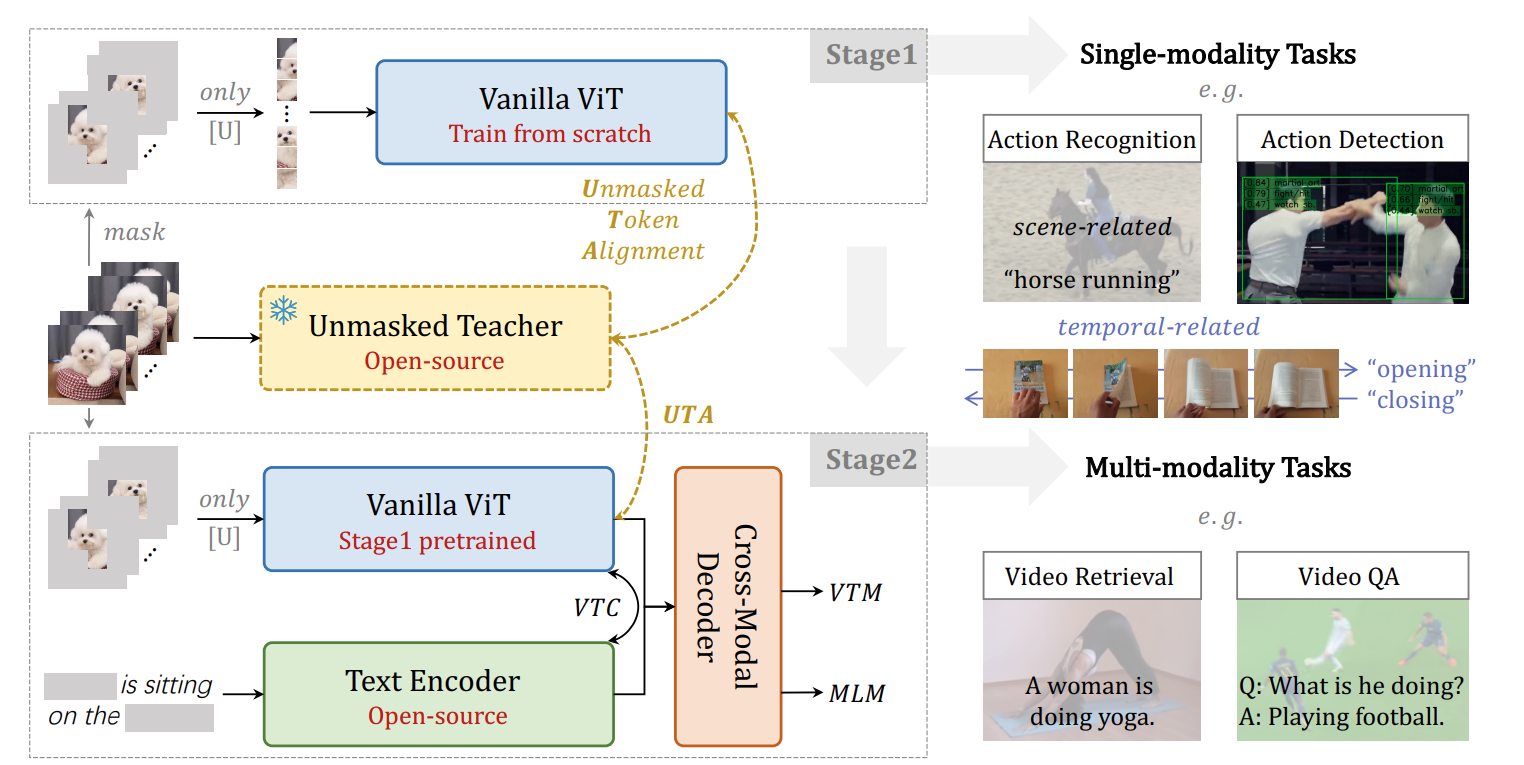
Stage 1
- 오로지 Video dataset 만 사용된다.
- teacher student 방식으로 이뤄진다
- teacher: CLIP-ViT, student: Vanilla ViT (without CLASS token)
- CLIP-ViT 는 이미지에 관한 지식이 풍부하고, multimodal 로 학습되었기 때문에 도움이 될 것으로 보았다.
Masking
- VideoMAE처럼 높은 masking 비율 80%을 사용하되, random masking 을 사용하지 않는다.
- Semantic Masking: last layer 의 attention score 에 softmax 를 적용해서 중요도를 판단한다. attention score 가 높을수록 중요하다고 본다. 즉, 중요도가 높을수록 masking 될 확률이 높다.


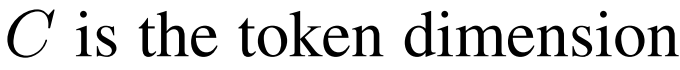
- ViT 모델에 넣은 임베딩에서 Class token 과 나머지 프레임 임베딩간의 attention score 를 구한다.
- 이걸 중요도로 간주하겠다는 이야기다.
Semantic Masking 제안 논문: https://arxiv.org/abs/2208.06049
MILAN: Masked Image Pretraining on Language Assisted Representation
Self-attention based transformer models have been dominating many computer vision tasks in the past few years. Their superb model qualities heavily depend on the excessively large labeled image datasets. In order to reduce the reliance on large labeled dat
arxiv.org
요약하자면, Teacher model 인 CLIP-ViT를 통해 Class token embedding 과 frame embedding 을 비교하여 attention score 를 구하고, 그 score 를 기준으로 마스킹 중요도를 구한다는 것이다.
Target
- Teacher model: 원본 비디오가 Class token과 함께 들어간다.
- Student model: 마스킹되지 않은 토큰들만 들어간다. L(1 - r)T tokens 인데, r 은 masking ratio 를 의미한다. L 은 한 이미지당 토큰 개수를 의미하고, T는 프레임 개수를 의미한다.
- 각 모델 모두 output 에 projection 을 통해 차원을 맞춘다.
- 그 후에 distillation 을 진행하는데, Mean Squared Error (MSE) 를 사용한다.
Stage 2
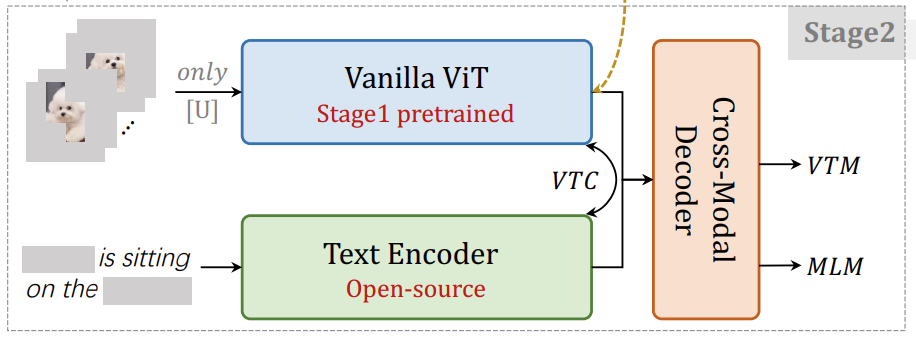
- Multi Modal Dataset 이 사용된다.
- Text Encoder 는 어떤 것이든 Open-source 라면 사용가능하다.
- Video-Text Contrastive (VTC) learning: Masking 한 채로, 진행한다는 점이 주목할 만하다.
- Video-Text Matching (VTM): Video 와 Text 임베딩을 함께 넣어서 둘이 맞게 짝지어졌는지 아닌지 맞춘다. Binary Cross Entropy 및 Hard Negative Mining 이 사용되었다고 한다.
- Masked Language Modeling (MLM): 비디오는 복구하지 않고 텍스트만 한다고 한다.
실험
데이터셋
- Stage 1: Kinetics-710 dataset
Stage 2
- corpora 1 - 5M Corpus: WebVid-2M video-text pairs and CC3M image-text pairs.
- corpora 2 - 17M Corpus: image-text datasets: COCO, Visual Genome, SBU Captions and CC12M 을 추가한다.
- corpora 3 - 25M Corpus: larger version of WebVid containing 10M video-text pairs 을 사용한다.
모델
student
- Base: ViT-B/16 with BERT base
- Large: ViT-L/16 with BERT large
Teacher
- Base: CLIP-ViT-B/16
- Large: CLIP-ViT-L/14
하이퍼파라미터
Stage 1
- VideoMAE 를 대부분 그대로 따랐다.
- 8개의 프레임을 sampling 했고, Masking 비율은 80%다.
- GPU: A100 32개 사용 (말이 되는 것인가....)
- Batch size: 2048 & Epoch: 200
- Base 와 Large 학습하는데 각각 60, 90시간 걸렸다고 한다.
Stage 2
- 4개의 프레임을 비디오에서 sampling 했다.
- image 는 50%, video 는 50% masking 했다.
- GPU: A100 32개 사용 (이거 부자 분야네요...)
- Batch size: 4096
- 25M corpus 기준 Base 와 Large 학습하는데 각각 20, 40시간 걸렸다고 한다.
Ablation Study: Pretraining Method of Stage 1
: 처음부터 ablation study 성능이 나온 논문이 거의 없어서 신기하다.
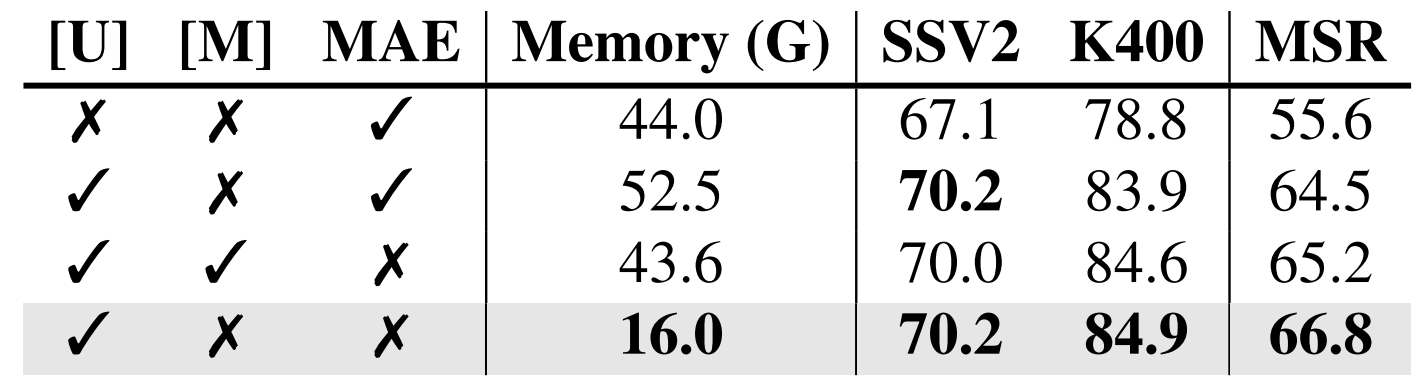
- [U]: Unmasked Token Alignment, 즉 해당 논문에서 제시한 방법이다
- [M]: Maksed Token 을 reconstruction 하는 것이다
- MAE: pixel-level reconstruction 으로, 위와 다른 점은 토큰 단위이냐, 픽셀 단위이냐이다.
- [U]만 단독으로 사용하는 것이 다른 것과 병행한 것보다 높고, MAE 단독보다 성능이 높다는 걸 알 수 있다.
Ablation Study: Masking

- attention score 를 활용한 semantic masking 방식이 가장 성능이 좋다는 걸 보여준다.
- SSV2: 해당 데이터셋은 물체를 인식하는 것보다 어떤 동작인지 알아채는 것이 중요하기 때문에, Random masking 으로도 충분하다는 걸 알았다.
- K400: 어떤 물체인지 인식하는 것도 중요하기 때문에 Semantic masking 이 distillation 에 더 도움이 되었다고 저자는 해석한다.
Ablation Study: Layer
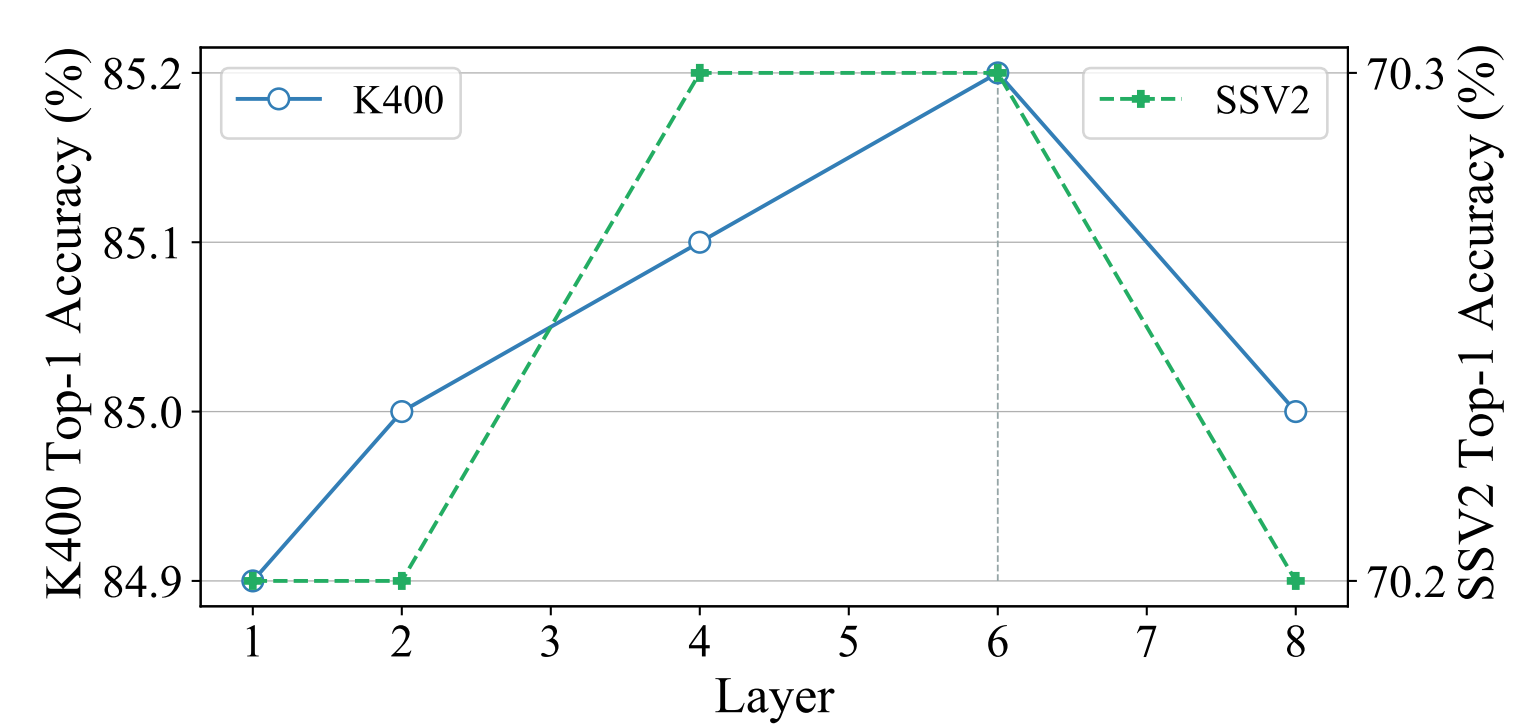
- 여기서 layer 가 무엇인지 정확히 모르겠으나, 문맥상 stage 2 의 decoder 로 추정된다.
- GPU 사용량과 속도 차이가 거의 없어서 성능이 가장 좋은 6개를 사용하기로 결정했다.
Ablation Study: Masking Ratio

- 80% 보다 낮으면, 시공간 정보를 익히기에 난이도가 쉬운 것 같고
- 95% 이상일 땐, 급격히 성능이 하락하기 때문에 80%로 정했다고 한다.
Ablation Study: Why does UMT work?

- Student: 학생은 시공간 정보를 모두 활용한 ST가 가장 좋았다
- Masking: 공간 정보만 활용한 경우, 즉 프레임별로 따로 따로 정보를 활용할 때는 마스킹까지 할 때 난이도가 올라서 성능이 떨어진다고 보았다. 반면, 시공간 정보를 모두 활용한 ST는 Masking 해도 적절히 정보를 활용할 수 있어서 성능이 오른다고 보았다.
- CLIP-ST: ST 성능 자체는 S보다 높지만, 선생으로서 활용될 때 Post training in video domain 이 오히려 그 전에 배웠던 image domain 의 성능을 해친다고 보았다.
- 결국 가장 좋은 방법은 청출어람을 보여준다. Teacher model 보다 Student model 이 성공적으로 좋은 성능을 보여줬다.
Ablation Study: Multi-modality masking ratios

- 비율 실험 결과, 이렇게 하는 게 가장 좋았다고 한다.
Ablation Study: Multi-modality pre-training objectives

- 모든 loss 의 weight 는 1로 설정했다. 공평하게 반영했다는 이야기다.
- 이때 모두 적용한 것이 성능이 좋았다는 걸 보여준다.
- 그리고 Masking 을 적용하지 않으면, 메모리 사용량이 3배나 증가하는데 성능도 소폭 감소한다는 걸 맨 밑과 맨 밑에서 두번째 것과 비교하면 알 수 있다.
성능

- 비전 분야를 하는 사람은 아니어서 세부적인 성능을 넣진 않았고, 요약표만 봤다.
- 사전학습 방법을 통해 다양한 태스크에서 성능이 높다는 걸 보여준다.



