논문명: Dataset Distillation with Attention Labels for Fine-tuning BERT
논문링크: https://aclanthology.org/2023.acl-short.12/
Dataset Distillation with Attention Labels for Fine-tuning BERT
Aru Maekawa, Naoki Kobayashi, Kotaro Funakoshi, Manabu Okumura. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023.
aclanthology.org
아이디어만 정리합니다
Dataset Distillation
- 전체 데이터셋을 요약한 하나의 벡터를 만들어서 그 벡터를 1번만 학습해도 전체 데이터셋을 학습한 것처럼 만드는 것
방법
학습 벡터 준비

- 요약할 하나의 벡터를 설정한다. (M, 512, 768) 로서 데이터셋처럼 해석하자면, M개의 데이터가 있는데 길이가 512이고 차원이 768인 벡터를 입력으로 넣는다.
- 이 벡터의 정답은 hard label 과 soft label 로 나뉘는데, soft label 이면 입력처럼 학습할 벡터를 넣어주면 된다.
- M개가 class 개수와 같기 때문에, hard label 인 경우 학습가능한 벡터 대신 각 클래스 정답을 넣어준다. 예컨대, 3개의 클래스로 구성된 데이터셋을 요약한다면 M = 3 이다. 그러므로 hard label 은 0, 1, 2 이렇게 넣어준다.
모델 구성
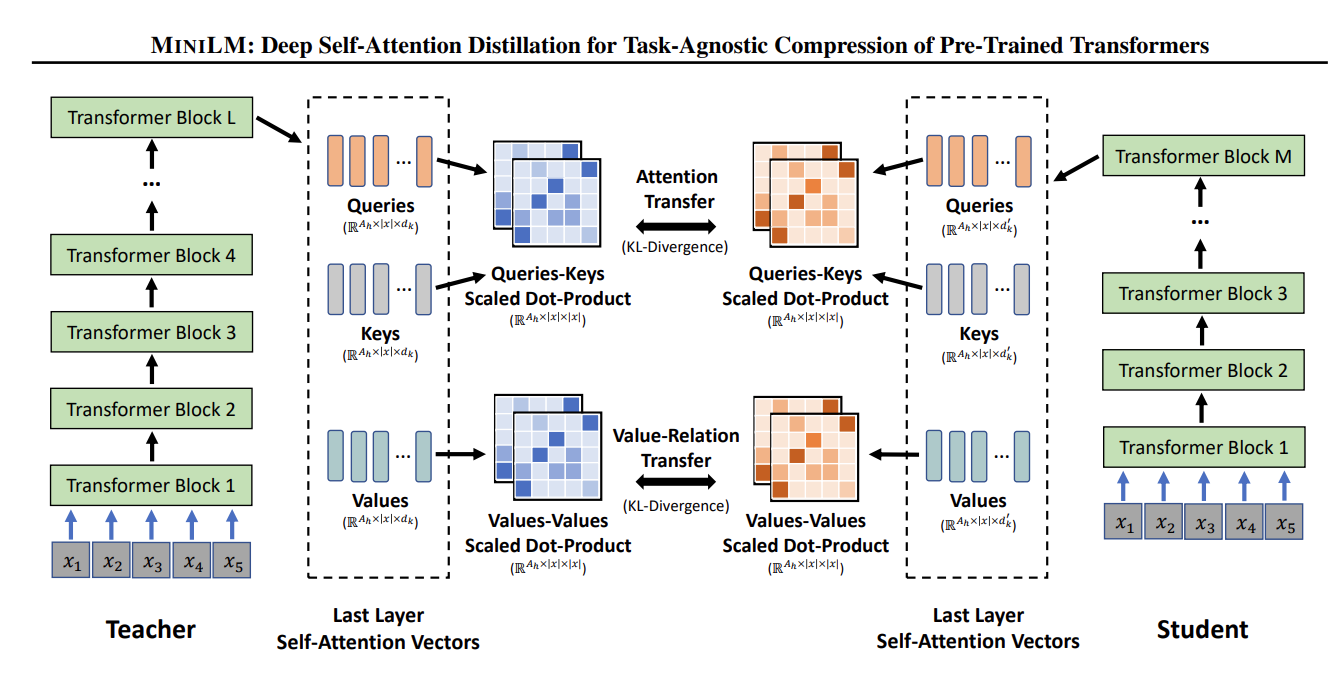
- Teacher 와 Student 가 있다.
- Teacher 는 전체 데이터셋으로 학습할 것이고, Student 는 위에서 초기화한 벡터를 계속 학습할 것이다.
- 이때, teacher 모델의 attention score 와 sutdent 모델의 attention score 가 같도록 해줄 것이다. 이걸 이해하기 쉽도록 타 논문에서 그림을 가져왔다.
모델 파라미터와 데이터셋 벡터는 따로 학습하는데, 이때의 loss 함수나 자세한 알고리즘은 논문을 참고할 것. 핵심은 전체 데이터셋을 요약하는 데이터셋 벡터를 만들어서 이걸 통해 한번만에 높은 성능을 낼 수 있도록 distillation 할 수 있다는 점이다.
다만 같은 모델이 아닌 경우, 사용이 힘들다는 점이 있고 Prompt tuning 과 결국 다른 점이 무엇인지 모르겠다는 생각이...
참고 자료
https://arxiv.org/abs/2002.10957
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers
Pre-trained language models (e.g., BERT (Devlin et al., 2018) and its variants) have achieved remarkable success in varieties of NLP tasks. However, these models usually consist of hundreds of millions of parameters which brings challenges for fine-tuning
arxiv.org



