논문명: Diffuser: Efficient Transformers with Multi-hop Attention Diffusion for Long Sequences
논문링크: https://arxiv.org/abs/2210.11794
Diffuser: Efficient Transformers with Multi-hop Attention Diffusion for Long Sequences
Efficient Transformers have been developed for long sequence modeling, due to their subquadratic memory and time complexity. Sparse Transformer is a popular approach to improving the efficiency of Transformers by restricting self-attention to locations spe
arxiv.org
아이디어만 정리합니다
아이디어
- Transformer attention mechanism 을 개선하자
- attention score 와 value 를 그래프로 보자
- node = value
- edge = attention score
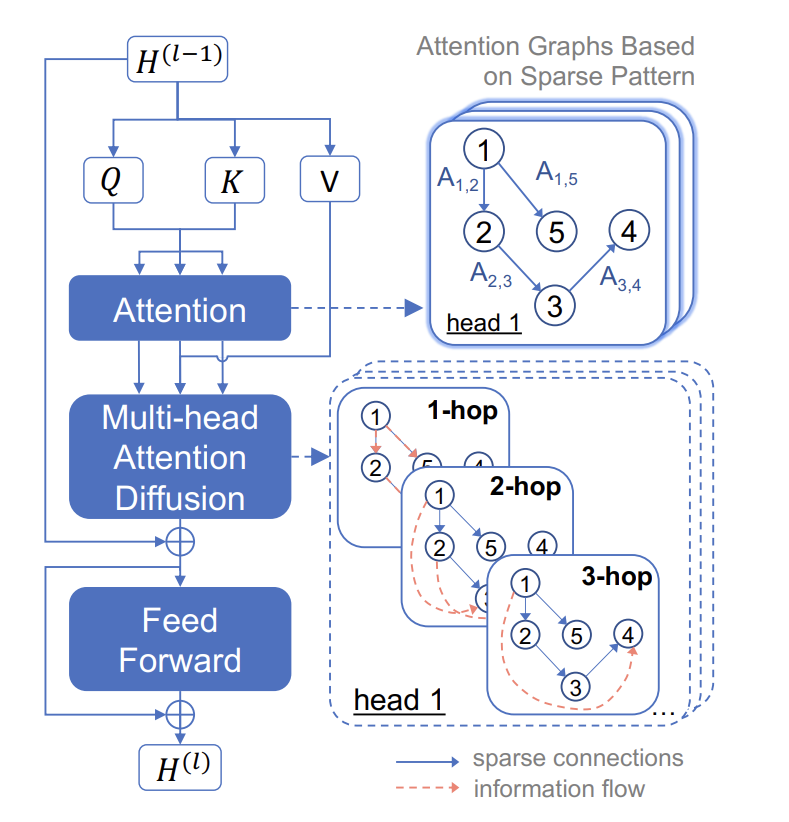
- Q 와 K 만 먼저 연산해서 attention score(A) 를 구한다. 이때, longformer 처럼 주변 토큰만 attention score 를 구한다.
- 그 다음, '기존 V'와 A를 그래프 구조로 보고 page rank 를 적용한다. 그래서 주변 토큰이외에도 전체적으로 attention score 가 흐르도록 한다.
- page rank 가 결국 수렴하니까 여러 번 계산하자. 단, 무한히 많이 하지 말고 실험 결과 5번 정도가 가장 좋았으니 page rank 를 5번 실행하자.

- Longformer: 주변 토큰끼리만 attention 해서 효율적으로 가자
- BigBird: 주변 토큰끼리 보는 것도 좋은데, 노란 토큰은 전체 다 보게 하고, 무작위로 파란색 토큰들끼리 attention 하자
- diffuser: 위 방식에 추가적으로 random 하게 일부 행이나 열은 global attention 이 작용하도록 한다
결론: attention score 와 v 를 adjacency matrix 와 node 로 간주해서 page rank 알고리즘을 적용할 생각을 했다



