논문명: Should You Mask 15% in Masked Language Modeling?
논문링크: https://arxiv.org/abs/2202.08005
Should You Mask 15% in Masked Language Modeling?
Masked language models (MLMs) conventionally mask 15% of tokens due to the belief that more masking would leave insufficient context to learn good representations; this masking rate has been widely used, regardless of model sizes or masking strategies. In
arxiv.org
일부 아이디어만 정리합니다
아이디어

- Masking Ratio 를 40%로 올렸더니, 성능이 더 오르더라
- 80%도 성능이 그렇게 나쁘지 않더라 → 이 말을 하는 저자의 의도를 추측해보자면, 80%도 성능을 올리는데 기여하는숫자다. 즉 모델 크기를 많이 키우는 요즘 추세에 맞춰서, 더 큰 모델에겐 80%가 더 잘 작동할 수 있을 것이다
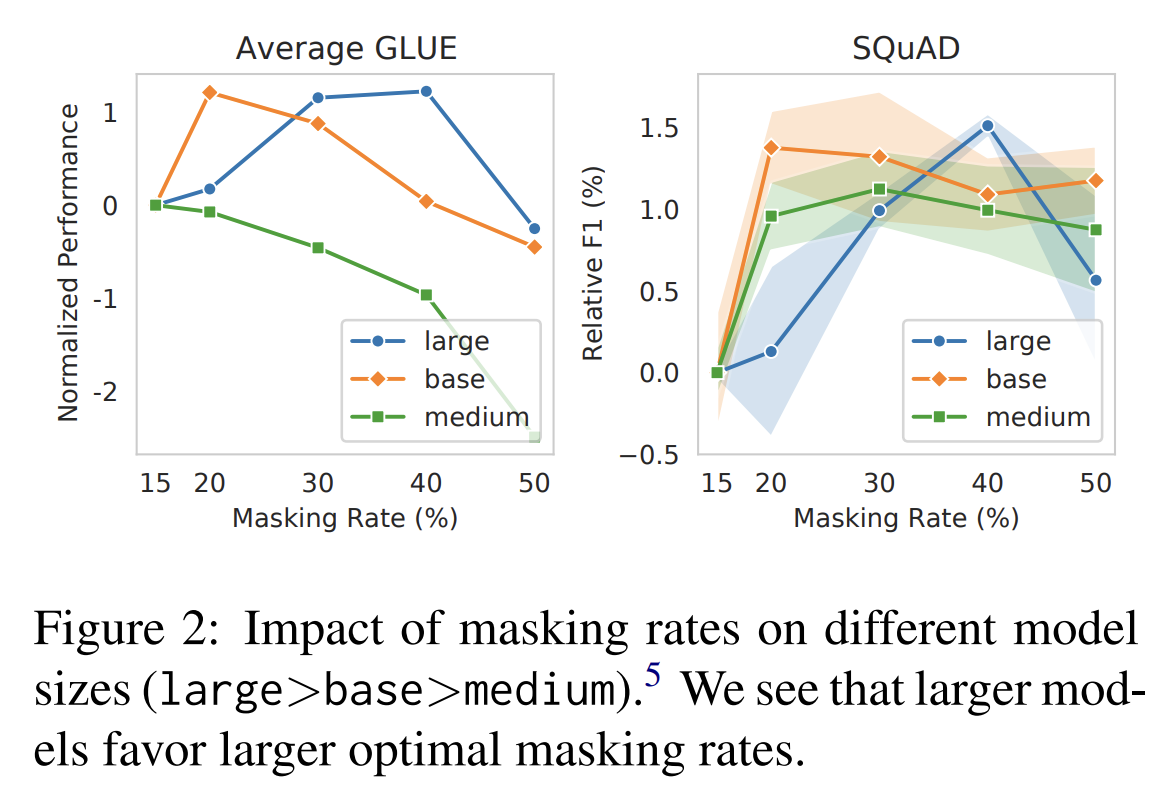
- 모델 크기가 클수록 Masking Ratio 를 올려주니 더 잘하더라
Masking 을 이해하는 2가지 관점
- Corruption: masking 양이 증가할수록 난이도 역시 증가하기 때문에 해당 task 의 난이도를 조절할 수 있을 것이다
- Prediction: prediction 의 양을 늘리는 것이 데이터 양을 조절하는 효과가 있어 최적화를 조절할 수 있을 것이다



