후기가 꽤 기니, 목차를 살펴서 읽어보시면 좋을 것 같습니다.
그리고 보다 진솔하면서도 짧은 글을 위해 반말로 쓰게 된 점, 양해부탁드리겠습니다.
코드가 궁금하신 분들께선 여기를 클릭해주세요.
마지막으로
이 대회를 개최하기 위해 노력하신 모든 분,
참가해서 대회를 완성해주신 분,
누구보다 제 팀원들께
깊은 감사를 전합니다.
Hey, shakesby.
후기 작성해줘.

목차
1. 참가 신청
2. 참가 전
3. 예선 및 본선
4. 서버 제공 기간
5. 북커톤 대회 기간
6. 느낀 점
1. 참가 신청
대회 안내

- 11월초에 신청자를 모집하여 1월 중순까지 약 80일 정도의 긴 대회 여정이다.
- 상금은 추후에 '대상'만 300만원에서 500만원으로 올랐다.
- 본선 대회는 1월 초에 1일 연기된다는 공지를 해줬으니, 기간을 유의하면 좋다.
대회 참가 사유

여기 적혀 있듯이 내가 좋아하는 글과 AI 가 만났기 때문이다. 그리고 그걸 새로운 사람과 함께 하고 싶어서 이런 글을 올렸다. 이 글을 통해서 5명을 모았다.
2. 참가 전
전 대회 참가자들 찾아서
올해 벌써 4번째 대회였으니, 기참가자들의 자료가 있을 것이라 생각했다. 우리가 찾은 분들은 다음과 같다.
- https://github.com/jeina7/GPT2-essay-writer
- https://github.com/kojunseo/bookathon2021-SKKU-Team-COCO
- https://github.com/jskwak98/Bookathon3_Bookie_On_And_On
- https://github.com/dltmddbs100/The-3th-AI_Bookathon
확실히 이분들의 도움이 없었다면, 방향성을 잡기가 어려웠다. AI 가 처음인 친구들에겐 특히 그 흐름을 익히는데 도움이 된 것 같다. 그리고 인공지능이 쓴 글들을 올려놓은 팀도 있으니 꼭 읽어보길 바란다.
미리 데이터를 모으다
가장 먼저 준비할 수 있다고 느낀 것은 데이터였다. AI 를 조금이라도 배웠다면, 과장을 더해서 AI 는 데이터 싸움이라고도 할 수 있다. 이 세상의 모든 개발자나 IT 기업들이 github 에 코드는 공개해도, 데이터는 공개하지 않는 것만 봐도 알 수 있다.
문학성이 높은 데이터를 모은다는 것은 어려웠다. '문학성이 높다' 를 컴퓨터에게 정의한다는 것은 어렵기 때문이다. 실제로 이건 좋은 글과 수상에도 연결되는 이야기니 고민해보길 바란다. 추후에 수상하신 분들의 전략과 함께 자세히 언급해보겠다.
우리가 선정한 후보는 9개였고, 그 중 2개를 선택했다.

참고로 대회 참가 직후, Slack 을 통해서 협업을 진행했다. 운좋게도 대회 진행도 Slack 으로 이뤄졌으니, 미리 익숙해지고 싶다면 쓰는 것을 추천한다. 다만, 대부분의 팀들은 이렇게 미리 준비하더라도 본선 진출하고 나서 준비했을테니 부담을 가지지 않았으면 좋겠다.

미리 전처리를 준비하다

한국어 전처리는 AI가 자연어라는 분야를 개척한 순간부터 지금까지 주구장창 해왔기 때문에, 일찍 시작할수록 좋다. 검색해도 많이 나오고, 파이썬 정규식을 다룰 줄 안다면 그리 어렵지 않을 것이다. 다만 기수상자의 후기에 'KLUE'를 참고했다는 이야기가 있어서 발표 시간에 언급이 잦았던 게 기억에 남는다. 개인적으로는 참고해도 좋지만, 개별적으로 찾아보는 과정을 공부하는 걸 더 권한다. 그 이유는 전처리 대상에 따라 전처리해야 내용이 유동적으로 변하기 때문이다.
https://github.com/KLUE-benchmark/KLUE
GitHub - KLUE-benchmark/KLUE: 📖 Korean NLU Benchmark
📖 Korean NLU Benchmark. Contribute to KLUE-benchmark/KLUE development by creating an account on GitHub.
github.com
대회를 함께 하면서 팀원 중에 AI 의 길을 함께 걷는 친구가 있었는데, 바빴을 텐데도 불구하고 도움이 필요할 때마다 제일 먼저 나서서 새벽까지 밤을 새서라도 해내주었다. 덕분에 우리 팀의 전략에 흔들리지 않고 진행할 수 있었다.

그리고 이 친구 덕분에 알게 된 사실인데, tmux 를 사용하면 동시에 여러 개의 코드를 돌리는 것은 물론이고 내가 SSH 접속을 종료하더라도 서버에서 알아서 작업을 완료하도록 해준다. 아래는 각 분야별 크롤링을 대량으로 진행할 때, 대신해서 돌려준 상황이다.

다른 친구 덕분에 Linux 에서도 selenium 을 사용할 수 있다는 사실 역시 배웠다.
미리 AI 자료를 모으다
AI 와 Python, 글쓰기 등 다양한 분야를 다룰 줄 알아야 하는 대회인 만큼 각자 잘 하는 영역이 달랐다. 예선이 AI 관련 시험이라고 들어서, 그리고 대회 진행에 원활함을 위해서 자연어 기초부터 현재까지를 조사해서 서로 공유했다.
그리고 각 기수상자들의 후기를 참고하여 분석했다. 그리고 역할을 나눠서 각자 주어진 일에 최선을 다했다.


미리 코드를 작성해서 돌려보다
미리 코드를 작성했다. 글을 생성한다는 것이 어떤 느낌인지 궁금했기 때문이다. 그래서 github 을 private 하게 생성하여, crawling 과 generation 모두 돌려보았다. 이것 때문에 Colab Pro 를 결제했다가 실수로 1달 더 결제했다. 코드는 사실 구하기가 어려웠다. 우리 팀 코드는 아래 github 에 공개되어 있으니 참고하면 좋겠다.
https://github.com/goonbamm/4th_bookathon
GitHub - goonbamm/4th_bookathon: 제 4회 북커톤 대회에 참여한 'Hey, Shakesby' 입니다.
제 4회 북커톤 대회에 참여한 'Hey, Shakesby' 입니다. Contribute to goonbamm/4th_bookathon development by creating an account on GitHub.
github.com
물론 이 글을 읽으면서 미리 코드를 돌려보지 못했거나 코드가 어려운 분들에게 괜찮다고 말씀드리고 싶다. 대부분의 수상자가 그날 처음 코드를 완성해서 돌려봤기 때문이다. 그 점에서 코드는 돌릴 수만 있다면 큰 걱정을 하지 않아도 괜찮다.
다만, 그렇다고 팀원 전부 pytorch 가 처음이라면 곤란하다. 대회 측에서 제공해주는 코드가 있긴 한데, 그건 tensorflow1 으로 작성되어 있기 때문이다. 내가 느끼기엔 난이도가 있으니, pytorch 로 AI 코드를 이해할 수 있다 정도의 수준을 갖춘 사람이 1명 이상만 있으면 괜찮아보인다.
3. 예선 및 본선
예선, 2일간의 여정

예선은 2일간 진행된다. 올해 참가한 팀은 대략 50개가 넘는다고 들었다. 함께 온라인으로 수업을 들었다. 대회 안내 사항, 딥러닝 기초, 기수상자 특강 등 다양한 내용들로 구성되어 있다. 아마 참가자가 전국 단위로 구성되기 때문에 그 수가 많아서 코로나가 아니었어도 온라인으로 진행했을 것 같았다.
예선 마지막 날에 본선으로 가기 위한 시험을 치룬다. 총 15개의 팀을 선발한다고 한다. 시험은 딥러닝에 관해서 어느 정도 알고 있는가로 평가한다. 더 자세하게 언급할 수 없지만, AI 대회인 만큼 어느 정도는 갖춘 팀을 고르자는 취지에서 불가피하게 진행하는 것 같다. 전문가가 아니어도 가능하니, 대학생이라면 도전하길 바란다 🔥🔥🔥
본선

우리팀은 본선 진출 이후, 만나서 혹은 온라인으로 회의를 거쳐서 각자 역할을 나눠 준비했다. 방학 기간이라서 가능했던 것 같다. 다들 시간 내서 미리 준비할 수 있는 것들을 했다. 자세한 건 아래에서 이야기해보겠다.
4. 서버 제공 기간
SSH
코드에 미리 적응할 수 있는 시간을 주고자 대회보다 일찍 서버에 접속할 수 있다. 당연히 SSH 방식으로 팀별로 제공하는데, GPU 는 Tesla T4 1개(약 16GB) 다.

처음 하는 사람이라면, 강력하게 VS code 를 권하고 싶다. 현재 세계에서 가장 많이 쓰는 코드 에디터이며, 적응도 쉽고 편리하기 때문이다. 다양한 기능을 제공하니 초보자라면 묻지도 말고 VS code 를 설치해서 SSH 설정을 해두길.
대회 때 사용할 모델을 고르다
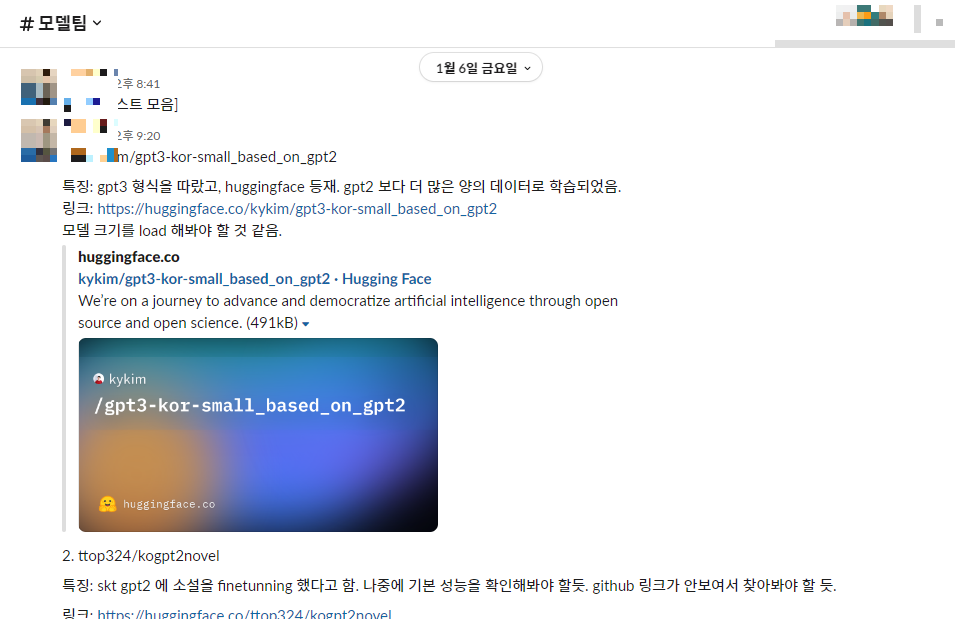

자연어 처리분야의 발달과 huggingface 의 등장으로 다양한 모델들을 사용할 수 있게 되었다. 대회 측에 문의드려본 결과, GPU 와 License 가 허락한다면 모델 사용이 가능하다고 말씀해주셨다. 그래서 위처럼 다양한 모델들을 조사했고, 추합했더니 다음과 같은 후보군이 생겼다.

이에 대해 크게 3가지 기준을 통해 최종 모델을 선정했다. 기준은 다음과 같다.
- 학습 시간이 얼마나 빠른가?
- 학습 데이터에 얼마나 빠르게 적응하는가?
- 생성한 문장은 어느 정도의 문학성을 갖추고 있는가?
1. 학습 시간이 얼마나 빠른가
학습시간이 빨라야 했던 이유는 대회 주제에 따라 어떤 데이터를 학습할지 모르지만 그 변수를 감당할 수 있어야 하기 때문이다. GPU 와 주어진 시간으로 볼 때, 되도록 빠른 모델이 중요했다. Automatic Mixed Precision, 모델 크기 등이 고려되었다.
2. 학습 데이터가 얼마나 빠르게 적응하는가
학습이 빨라도 학습한 데이터를 잘 생성하지 못하는 경우가 있다. 그런 점에서 모델의 데이터 적응 속도가 궁금했다. 이건 prompt 를 넣어가며 정성평가를 할 수 밖에 없었다.
3. 생성한 문장은 어느 정도의 문학성을 갖추고 있는가
1번, 2번 기준을 통과해도 3번에서 막히면 무의미하다고 생각했다. 이것 역시 다양한 입력 문장(이하 'prompt')에 따라 달라질 수 있어서 정성적인 평가가 필요했다.
그렇게 우리가 선정한 모델은 SKT 에서 제공하는 KoGPT2 였다.
https://huggingface.co/skt/kogpt2-base-v2
skt/kogpt2-base-v2 · Hugging Face
This model can be loaded on the Inference API on-demand.
huggingface.co
대회에서 사용할 데이터를 모으다
막상 제공받은 서버로 글을 생성해보니, 원하는 수준의 글을 생성하지 못했다. 그리고 전처리에서 예외사항이 발생한다는 걸 깨달았다. 심지어 대회 당일 날, 어떤 주제와 어떤 전략으로 글을 작성해야 할지 모르니 미리 수집하는 게 맞다고 판단했다.

그래서 우리는 각 분야별로 데이터를 모았다. 데이터 분석 결과는 위와 같다.
사람의 개입이 허용되다
개인적으로 이 대회의 핵심이라 생각했다. 처음엔 금지했었는데, 대회 전날 허용해주었다. 그리고 역대 대회 참가자들의 이야기에 의하면, 사람의 개입을 매번 허용했다고 밝혔다. 이 대회의 취지도 AI 가 글을 창착해 책을 쓴다기보다는 'AI 와 사람의 협업 글쓰기'에 초점을 맞추니 이 점을 강하게 인지하는 게 중요함을 밝힌다.
5. 북커톤 대회 기간
대회 주제 공개
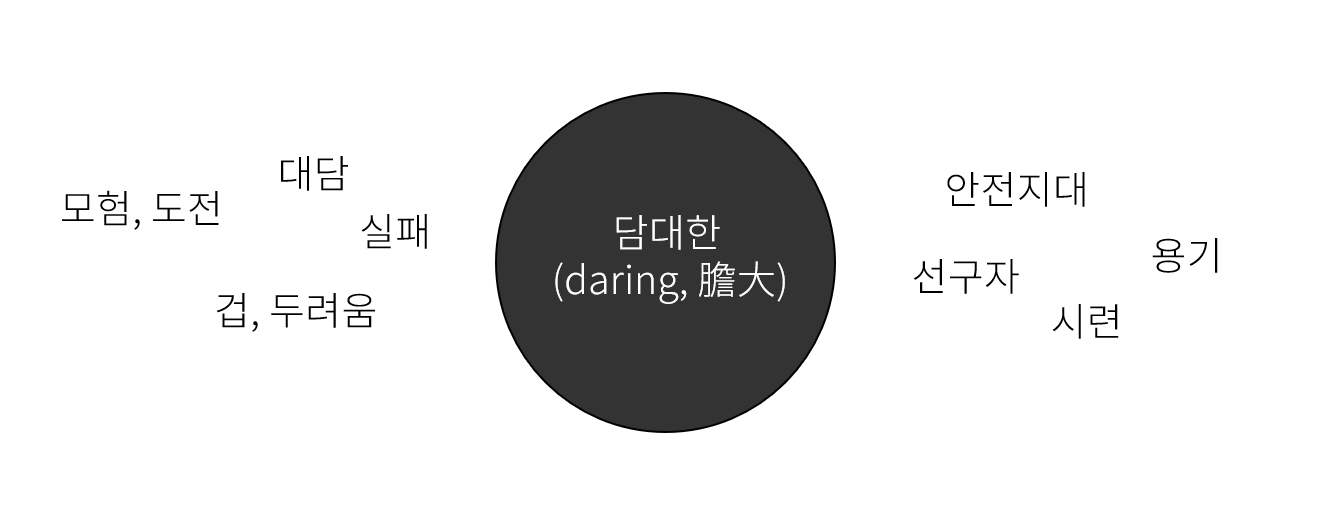
올해 주제는 '담대한'이었다. 주제가 주어진 뒤, 우리는 아래와 같이 진행했다. 참고로 주제는 올해 신임하시는 총장님의 말씀에서 따왔다고 밝혔다.
한 일
- 생각보다 주제가 구체적이고 흔하지 않아서 회의에 들어갔다.
- 사전적 정의를 찾고, 마인드맵을 통해 해당 주제와 관련된 단어들을 떠올렸다.
- 어떻게 글을 작성할 것인가에 대해 구체적인 전략을 세웠다.
했으면 좋았을 일
- '담대한'과 관련된 키워드를 뽑아내는 자연어 처리 프로그램을 만들었다면 어땠을까. 그 당시에 떠올렸지만, 해본 적이 없어서 시간 관계 상 생략했던 기억이 있다.
글쓰기 전략
우리는 우리가 가진 것들을 활용하여 글을 써내려야 가야 했다. 심지어 막상 대회에 들어가니, 2만자에 가까운 글을 쓴다는 게 얼마나 어려운 일인지 새삼 깨달았다. 생각해보면, 자기소개서에서도 악명 높은 길이가 1000자인데. 백일장 대회였어도 20000자는 버거웠을 것이다.
그래서 우리도 나름 다양한 전략을 세워서 갔다. 기수상자들의 글을 참고하여 아래와 같은 계획을 세웠다.
- 과거 시인들끼리 편지를 주고 받았던 걸 책으로 내서 잘 된 게 있었다. 우리도 편지를 주고 받으면 어떨까.
- AI 로 니체의 철학을 가진 모델을 만들어서, 시공간을 초월한 대화를 통해 담대함을 드러내면 어떨까.
사실 대회 전날, 산책하다 우연히 '알쓸신잡'이 떠올랐다. 단 한 번도 본 적은 없지만, 책을 쓰신 분들이 꽤 있어서 프로그램의 존재 정도는 알고 있었다. 때마침 우리도 각 분야별로 엄청난 양의 데이터를 갖고 있겠다, 이를 활용하여 다양한 사람들이 모여 주제에 대해 이야기하면 재밌겠다고 생각했다.

그래서 위와 같이 5개 분야의 전문가들이 모여 글을 쓴다는 전략에 수립했다. 운 좋게도, GPU 가 주말동안 놀지 못하도록 각 분야별로 학습을 시켜둔 게 시간 절약에 큰 도움이 되었다.
정리하자면, 다음과 같다.
- 여행 데이터 학습 모델 → 여행가
- 예술 데이터 학습 모델 → 예술가
- 에세이 데이터 학습 모델 → 교육자
- 사랑 데이터 학습 모델 → 낭만주의자
- 철학 데이터 학습 모델 → 철학자
하지만 뭔가 아쉬웠다. 어떻게 이야기가 더 자연스럽고 대담함을 잘 전달할 수 있을까에 대해 고민했다. 그 결과, 다음과 같은 형식으로 구성하게 되었다.

담대함을 찾아 모험을 떠난 소년,
그 길에서 다양한 사람들을 만났고,
마침내 자신만의 담대함에 다가서다.
이렇게 한다면, 모델이 너무 길게 하나의 글을 완성할 필요도 없었고, 우리의 자원도 활용하면서, 재밌는 글을 완성할 수 있을 것 같았다.
문학성과 담대함을 더하다
하지만 모델은 만만치 않았다. 문학적인 글을 결코 쉽게 허락해주지 않았다. 우리가 겪었던 문제는 다음과 같다.
- 모델이 말을 반복한다.
- 자신이 생성한 말에 정확히 반대되는 문장을 몇 문장 뒤에 뱉는다.
- '담대한'이라는 주제가 생소하다보니, 담대함에 대한 글을 잘 뱉어주지 않는다.
- 글자 수가 일정 수치 이상 길어지면, 주제에서 벗어난다.
우선 문학성을 더하는 게 중요하다 생각했다. 문학성이 높은 데이터를 골라서 finetuning 을 진행하고자 했다. 특히 예술 관련 모델은 예술과도 관련 없는 문장을 생성해서 예술성 역시 높여야 했다. 이 과정에서 기수상자들이 왜 마지막에 문학성이 높은 데이터로 finetuning 을 진행했는지 여실히 깨달았다.
한 일
- 2명이 각각 문학성, 예술성을 맡아서 직접 수집했다.
- 문학성: 다행히 대회 전에 문학성이 높은 작가님들을 미리 선별해두었음. 그 분들의 글을 크롤링하였음. 이에 더해, 저작권이 만료되었느나 문학성이 높은 국내/해외 작품 등을 더했음.
- 예술성: 예술 칼럼, 예술 관련 데이터에서 문학성이 높은 데이터를 모아서 예술 모델을 따로 학습시켰음.
했으면 좋았을 일
기수상자분들 중에서 'elastsic search' 를 사용하신 분이 계셨다. 모은 데이터 중에서 필요한 데이터만 꺼내서 사용하는 것 같았는데, 대회 전에는 필요없다고 생각했다. 하지만 막상 대회가 시작되니 필요성을 깨달았다. 예컨대, '담대한'이라는 주제를 가진 글을 모으는 건 쉽지 않다. 사람이 그와 관련된 단어들(용기, 두려움, 겁)을 연상하여 긁어모아야 한다.
혹시나 언젠가 이런 상황에 다시 놓인다면, 필요한 데이터를 선별하여 찾아내는 기술을 적용해볼 것 같다. 떠오르는 예시로는 'doc2vec', 'Bag of Words' 와 같은 기법들과 'Information Retrieval' 에서 쓰이는 'DPR' 등이 있다. 'SentenceBERT' 역시 고려대상이었으나, 아쉽게도 해보진 못했다.
https://github.com/facebookresearch/DPR
GitHub - facebookresearch/DPR: Dense Passage Retriever - is a set of tools and models for open domain Q&A task.
Dense Passage Retriever - is a set of tools and models for open domain Q&A task. - GitHub - facebookresearch/DPR: Dense Passage Retriever - is a set of tools and models for open domain Q&A ...
github.com
https://github.com/BM-K/KoSentenceBERT-ETRI
GitHub - BM-K/KoSentenceBERT-ETRI: 🌷 Sentence Embeddings using Siamese ETRI KoBERT-Networks
🌷 Sentence Embeddings using Siamese ETRI KoBERT-Networks - GitHub - BM-K/KoSentenceBERT-ETRI: 🌷 Sentence Embeddings using Siamese ETRI KoBERT-Networks
github.com
그렇게 문학성을 더했다. 큰 체감은 못했지만, 도움이 되었다.

중간 발표
대회 당일 일정을 안내하시는데, '중간발표'라는 게 있었다. 평가와는 무관하지만, 서로 소개하고 재미를 더하는 시간이었다. 랩, 비트박스, 연기 등 다양한 끼를 갖추셔서 흥미진진했다. 무엇보다 다들 반응을 잘 해주셔서 모두 긴장을 풀 수 있었던 것 같다.
하나 조언을 하자면, 이 시간이 90분 정도 걸리기 때문에 중간 발표 동안 학습을 돌려놓는 걸 추천한다. 나는 그 때 학습을 시켜서 기분이 좋았다. GPU 가 놀게 하는 걸 볼 수 없지.
Decoding Methods
내가 발표할 때도 사용했던 말인데, "가장 똑똑한 사람이 가장 말을 잘 하는 것은 아니다."라고 생각한다. 이 말을 모델에게 적용해본다면, 'decoding methods' 가 중요하다는 말과 같다.
우리는 그래도 자연어 처리에 대해서 더 깊게 공부하자는 취지로, 관련 논문 및 코드를 조사했다. 그랬더니 총 7가지 방법을 찾을 수 있었다.


- 기본적인 생성 방식: greedy search, beam search, top-k sampling, top-p sampling
- 새롭게 찾은 생성 방식: diverse beam search(2016), contrastive search(2022), typical local sampling(2022)
이에 대해 정리해뒀으니 참고해서 좋은 글을 쓰면 좋겠다.
기본적인 생성 방식에 대해 궁금하다면: https://heygeronimo.tistory.com/34
[huggingface🤗] How to generate text #1
자연어 처리 모델이 언어를 생성하는 방식에 관하여 잘 정리된 글이라서, 한글로 의역(수정)하고자 한다. 나에게도 공부가 되고, 이 글을 통해 한 사람이라도 도움이 된다면 기쁠 것 같다. 그리
heygeronimo.tistory.com
contrastive search 가 궁금하다면: https://heygeronimo.tistory.com/36
[huggingface🤗] How to generate text #2
서론 huggingface 에서 제공하는 함수 'generate' 는 매우 훌륭하다. 이에 대해 처음 듣는다면, 다음 글을 먼저 읽어보길 바란다. https://heygeronimo.tistory.com/34 [huggingface🤗] How to generate text #1 자연어 처리
heygeronimo.tistory.com
locally typical sampling 이 궁금하다면: https://heygeronimo.tistory.com/41
[논문이해] locally typical sampling
논문명: Locally Typical Sampling 논문링크: https://arxiv.org/abs/2202.00666 Locally Typical Sampling Today's probabilistic language generators fall short when it comes to producing coherent and fluent text despite the fact that the underlying models
heygeronimo.tistory.com
diverse beam search 은 따로 써둔 글은 없는데, 대충 이렇게 이해하면 편할 것 같다.
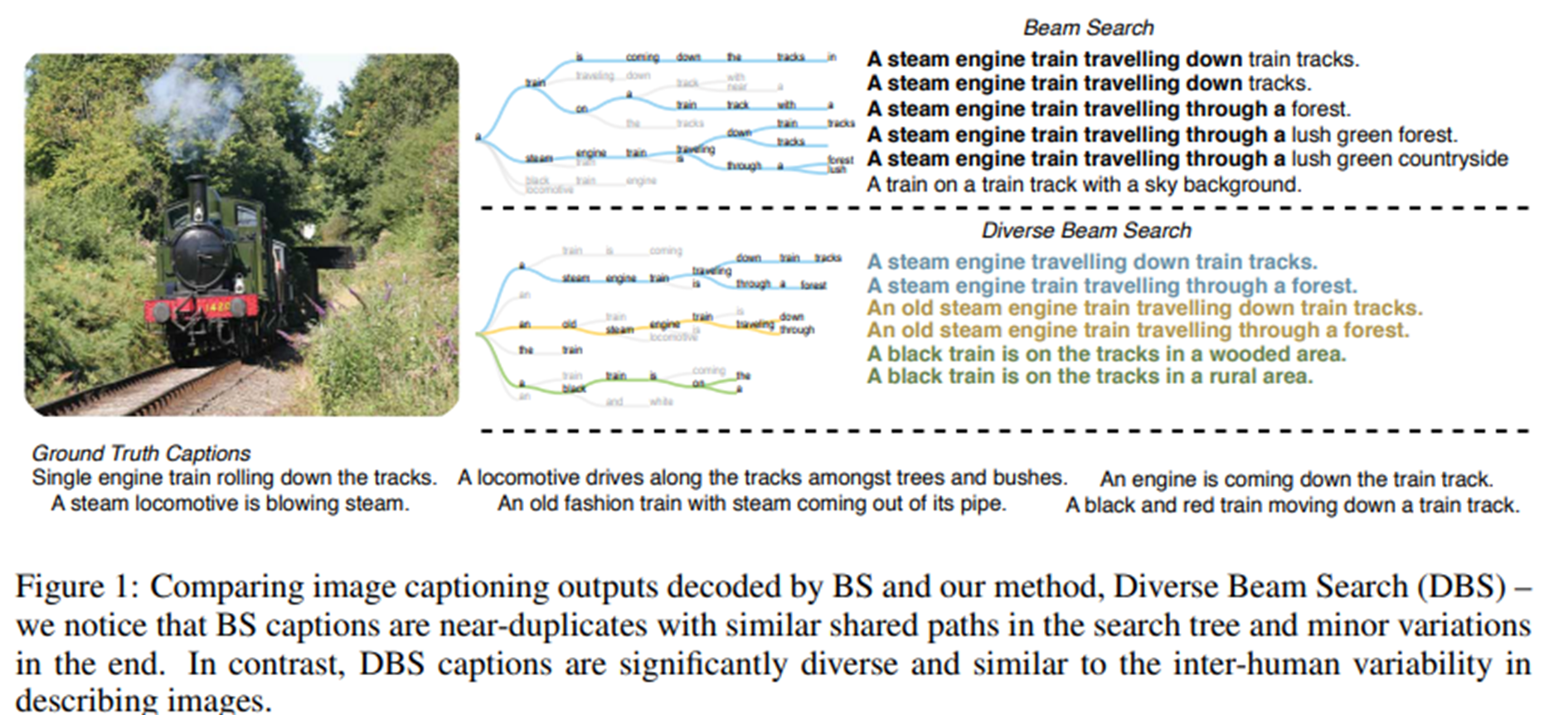
- 기존 'beam search' 는 위처럼 죄다 비슷한 말을 생성한다.
- 저자는 다양성(diversity)을 보장하기 위해, group 을 나눈다.
- 그 group 사이의 유사도를 측정하여 멀어지도록 한다.
- 이를 통해 beam search 의 본연의 취지를 더욱 살려 다양한 문장을 생성한다.

이렇게 수식으로 score 를 측정하는데, 실제로 계산도 효율적이라고 들었다.

각 그림을 설명하는 문장을 만들었는데, 모국어가 한국어인 나조차도 저 문장들이 얼마나 다양해졌는지 알 수 있다.
입력과의 싸움
흔히 자연어 처리(Natural Language Processing)에서 'prompt' 라는 말을 많이 쓴다. 쓰임새가 다양하여, 정확히 정의하기 어렵지만 이 글에선 모델이 생성을 위해 사용하는 입력(input) 정도로 받아준다면 좋겠다. 입력하는 문장은 매우 중요하다. 예시를 들어보겠다.

'중요한건 꺾이지 않는 마음'이라고 넣었더니, 저렇게 만들어줬다. 문장을 완성한 것까지는 자연스러우나, 갑자기 고혈압을 선사해준다. 쉽게 말해서 모델은 우리가 원하는 대로 작성해주지 않는다.
모델은 학습한 데이터를 기반으로, 주어진 문장과 가장 유사한 흐름을 가진 글을 작성한다.
그렇다면, 어떻게 해야 할까. 바로 부모의 마음을 가지면 된다. 우리 딸이 왜 저럴까라는 태도로 팔짱을 끼지 말고, 어떻게든 모델에게 제법 익숙한 문장이면서 우리 주제와 맞는 문장을 넣어줘야 했다.

그래서 우린 새벽 내내, 우리 자식들(?)을 달래가며 다양한 입력을 넣어가며 학습을 시켰다. 그리고 사람의 개입이 자유롭기에 여러 형태의 decoding method 를 모두 사용하여 그 중 가장 마음에 드는 출력을 선택해 글을 완성해갔다.
우연히 우리가 5명이라서 각자 하나씩을 맡아서 글을 만들었다. 모두가 AI 와 함께 글을 생성해보는 좋은 기회라고 생각했다. 나는 철학을 맡았는데, 때마침 니체를 좋아했고 '담대한'이라는 주제와도 걸맞아서 시간 가는 줄 모르고 글을 만들었다. 니체의 철학을 검색하며, 좋은 입력 문장도 찾았고 대회에 임하는 마음가짐도 더욱 단단해졌던 것 같다.

제목: 동행
그렇게 우리는 글을 마무리 지었다. 제목은 '동행'으로 지었다. 결국 삶은 함께 살아가는 것이고, 그 과정에서 배우고 자신을 찾아간다는 의미를 담아서다. 아래 사진에 첨부된 문장들은 순수하게 AI 가 생성한 문장들 중 아름답다고 느낀 문장들을 선별하였으니 감상해도 좋을 것 같다. 그림은 openAI 에서 제공하는 'DALLE2' 를 활용하였다.






발표
발표가 끝난 뒤, 유사도 검사와 표절 검사를 진행하셨다. 유사도 검사는 원본 생성물과 수정본의 차이를 보시는 듯 했다. 즉, 인간의 개입도를 수치화했다고 보면 되겠다. 표절 검사는 전 세계에 인터넷에 공개한 자료들과 비교했다. '카피킬러'를 사용하신 것 같았다.
팀 이름이 'ㅎ'으로 끝나서 마지막에 발표하게 되었다. 3시간을 넘게 기다렸고, 밤을 샌 상태에 긴장까지 하니 쉽지 않았다. 하지만 이 대회는 개인적으로 꼭 참가하고 싶었고, 그 과정이 즐거웠기에 마지막까지 최선을 다하고자 마음먹었다.
마지막 차례이기에 할 수 있는 것에 집중했다. 하나 기억에 남는 건, 심사위원의 질문이었다. 어떤 분께서 각 팀마다 정의하는 '담대한'에 대해 궁금해하셨다. 그 질문을 우리 팀이 받는다면, 어떻게 해야 할지 고민했다. 나는 이렇게 답하고자 준비했다.
저희는 각자만의 '담대한'에 대한 정의는 다르다고 생각했습니다. 예컨대, 저는 니체를 좋아합니다. 그래서 제게 담대함에 대해 물으신다면, '네 운명을 사랑하고 고통을 올바르게 이해하라. 그리고 나아가라'라고 말씀드릴 수 있습니다.
하지만 모두가 저처럼 받아들이진 않습니다. 바로 각자 살아오며 내린 담대함은 다를 것입니다. 저희는 물고기가 아닌 물고기를 잡는 법을 알려드리고 싶었습니다. '담대함'이란, 저희 이야기처럼 살아가보며 다양한 사람들의 '담대함'에 대해 묻고, 그 과정에서 자연스레 자신만의 담대함을 찾아가도록 말입니다.
그 이외에도 마지막 발표라서 다들 지치셔서 간단한 농담을 준비했었던 것 같다. 그리고 이 순간은 돌아오지 않는다, 정말 마지막이니 즐기자는 마음으로 임해서 발표가 끝났을 때 후련하고 마음이 편해졌다.
6. 느낀 점
평가 기준
평가 기준은 공식 홈페이지에 나와있듯이, 다음과 같다.

나는 느낀 점 중 배운 점을 AI 와 전략으로 나눠서 글을 작성하고자 한다. 이 부분은 지극히 주관적이며, 다른 분들의 이야기라 조심스럽다는 점을 인지하고 작성했음을 미리 밝힌다. 이 부분을 작성하는 가장 큰 이유는 이 경험이 내게 '배움'으로 남길 바라기 때문이다. 근사한 사람들과 함께 다양한 방식으로 선의의 경쟁을 펼쳤으니, 글로 정리하며 오래 간직하고 싶다.
AI 의 관점에서 배운 것들
1. 거대 모델을 사용하다
https://github.com/microsoft/DeepSpeed
GitHub - microsoft/DeepSpeed: DeepSpeed is a deep learning optimization library that makes distributed training and inference ea
DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective. - GitHub - microsoft/DeepSpeed: DeepSpeed is a deep learning optimiza...
github.com
대회 측에서 제공한 GPU 는 16GB 라서, GPT3 를 load 하는 건 불가능했다. 아니 그렇게 생각했다. 하지만 놀랍게도 2개 팀에서 GPT3 를 사용했다고 밝혔는데, 'deepspeed' 를 사용했다고 밝혔다. 대회가 끝나고 찾아보니, '10배 더 크게, 10배 더 빠르게' 라는 슬로건을 가진 훌륭한 라이브러리였다. 이 기법을 대회에 녹여내어 거대 모델을 활용했다는 점이 기발하다고 생각했다.
2. Summarization 을 이용하다
사실 AI 대회라서 기대는 했지만, 대학생이라서 우리처럼 최신 논문을 읽는 등의 시도를 한 팀은 없을 거라고 생각했다. AI 점수를 노려볼 만하다고 생각했는데, 기발한 방법으로 멋진 글을 생성하신 팀이 있었다.

그들의 기법은 '요약(Summarization)' 을 뒤집자였다. 쉽게 말해서 다음과 같은 기법이었다.
- 목표: '제목'만 넣으면 글을 작성하도록 하자.
- 문제점 A: 제목만 넣어서 글을 작성하기엔 2만자는 너무나도 길어.
- 해결책 A: 그러면 제목을 넣으면 요약본을 만들고, 요약본을 넣으면 본문을 생성하도록 하자.
- 문제점 B: (제목, 요약본), (요약본, 본문) 과 같은 데이터는 어디서 구해?
- 해결책 B: 요약 모델을 활용해서 만들자. 그러면 가능할 것 같아.
요약을 역이용하자는 발상이 참신했고, 그걸 실제로 행동에 옮겨 좋은 글을 탄생시켰다는 게 인상적이었다. 실제로 모든 팀 중에서 가장 인간의 개입이 적었다. 겨우 4개의 제목에 불과했다. 실제로 생성한 문장들을 보여줬는데, 문학적으로 깊은 문장들이었다.
3. SentenceBERT 를 활용하다
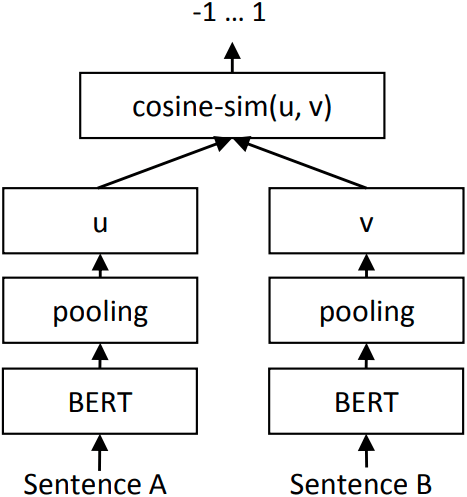
SentenceBERT 란, 간단히 말해서 문장 혹은 문단 등 글을 하나의 벡터로 변환하는 것을 말한다. 벡터로 바꾸는 이유는 크게 2가지가 있는데, 하나는 컴퓨터가 이해할 수 있도록 숫자로 변환하는 것이고, 다른 하나는 의미를 반영하고 싶기 때문이다.
의미를 수치화한다는 의미가 이 대회에서 가지는 의미는 바로 '의미론적 유사도(semantic similarity)'다. 이걸 측정한다면, 유용한 경우가 다음처럼 많다.
활용 가능성 예시
- 담대함이라는 단어가 없어도 담대함이 담긴 글을 찾는다.
- 가장 담대함을 잘 담아낸 글을 점수를 측정하여 순서대로 데이터로 활용가능하다.
- 생성한 문장과 주제가 적합한지 숫자로 알아낼 수 있다.
- 수많은 데이터 중에서 담대함과 거리가 먼 글들을 일일이 읽어보지 않고 확인할 수 있다.
- 담대함과 관련된 키워드를 추출할 수 있다.
실제로 위 과정 중 일부를 사용한 팀이 있었다. 솔직히 말하자면, 늘 염두는 해두고 있었는데 끝내 사용하지 못했다. 내가 생각한 방식은 이러했다.
수집한 데이터의 길이가 기니까 미리 SentenceBERT 로 임베딩해놓고 저장해두자. 그러면 대회 당일 날, 우리가 검색어(query)만 임베딩해서 유사도를 계산하면 시간이 훨씬 절약되면서도 유용하게 사용할 수 있을 거야.
위에서도 언급한 'DPR' 같은 방식을 의미한다. 대회 내내, 아쉬움으로 남는 부분 중 하나긴 하다. 하지만 생각하고도 움직이지 않는 자는 미련한 게 없다. 부디, 활용하고 싶은 사람들은 활용해보시길.
(성능은 보장할 수 없으니, 대회 전에 사용해보고 확인하길 추천한다.)
4. Metric 을 통해 세부적인 정성평가를 진행하다

AI 를 전공할 사람으로서, 2022년에 가장 놀랐던 점은 바로 'Generation' 이 가장 먼저 세상을 놀랍게 했다는 점이다. 'DALLE2', 'Diffusion', 'Imagen' 등 이미지 생성 모델이 전세계에 명성을 떨쳤다.
왜 놀라울 일이냐고 묻는다면, 생성 분야는 평가하기 어렵다.
- 혹시 잘 그린 그림을 점수로 표현할 수 있는가?
- 아니면 좋은 노래를 수치화할 수 있는가?
- 잘 쓴 글을 모두가 납득하도록 숫자로 채점하는 게 가능한가?
그래서 AI 분야에선 '정성 평가'를 진행한다. 정성 평가는 간단히 말하면, 사람이 직접 보고 점수를 매겼다고 보면 된다. 우리가 영화를 보고 평점을 매기듯 말이다. 하지만, 그 점수 역시 신뢰성이 높지 않다. 우리가 영화를 보러 갈 때, 평론가의 점수나 평점을 참고는 해도 그걸로 확신하지 않는다.
자연어 처리 분야에서도 생성 모델을 위한 평가 지표들이 존재한다. 다만, 압도적으로 신뢰도가 높은 평가지표는 없다. 다 각각의 기준에서 평가할 뿐이다. 예시로는 아래의 것들이 있다.
그 이외에도 많으니, 자세히 알고 싶다면 생성(translation, text generation, style transfer, abstractive summarization) 관련 논문을 참고하면 좋다. 거기 실험 목록에 다양한 평가 지표가 있을 것이다.
수상하신 팀에서 이 평가지표를 대략 7개까지 사용해가며 정성평가를 진행하는 걸 볼 수 있었다. 그분들의 실험은 집요했고, 문학성이 높은 문장의 탄생에 귀기울인 게 느껴졌다.
나 역시 문학성이 높은 문장을 위해 다양한 실험을 했지만, 평가 지표와 함께 실험을 기록할 생각은 전혀 하지 못했다. 그 점을 깊이 새겼고, 겸손해질 수 있었다고 생각한다.
전략의 관점에서 배운 것들
1. 데이터의 틀에서 벗어나라

보통 이런 대회에서는 데이터로 글을 쓰는 게 대부분이다. 우리도 상당한 양의 데이터를 가지고 있었지만, 글 이외의 데이터를 사용하지 않았다.
하지만 다른 팀에서는 데이터의 틀에서 벗어나 다양한 분야에서 가져왔다.
- 노래 가사 데이터
- 영화 데이터
- 드라마 데이터
실제로 이번 대회 수상자들의 대다수가 데이터에 변화를 줬다. 그분들의 발표에 의하면, 이런 데이터를 넣으면 좀 더 감정적인 글이 탄생한다고 한다. 이 점을 보고, 때론 나무가 아닌 숲을 바라볼 필요가 있다고 생각했다.
2. 개성을 마음껏 펼쳐라

'담대한'이라는 주제를 표현하는 것은 어렵지만서도, 동시에 다양한 방법으로 표현할 수 있다. 나는 우리 팀이 나름 개성 있게 표현했다는 점에서 자신 있었지만, 다른 팀들도 역시 그에 못지 않은 방식을 가져왔다. 그저 AI 가 생성한 글을 보고, 짜맞춘 주제가 아닌 처음부터 설계/의도했던 작품들이 기억에 남는 것 같다.
발표 역시 그랬다. 모두 훌륭하게 발표를 해주셨지만, 어떤 팀은 연기를 하셨다. 그 글의 주제와 딱 맞아떨어지는 연기에 공연을 보러 온 기분이 들 정도였다.
다음 참가자들이 어떤 주제로 어떤 글을 써내려갈지 모르지만, 부디 원하는 글을 써보길 바란다.
평가에 관하여
우리 팀은 아쉽게도 수상하진 못했다. 그럼에도 불구하며, 이렇게 긴 후기를 썼다. 부족하다면 부족하지만, 나는 이 후기를 쓰면서 다시 한번 확신하듯이 우리는 최선을 다해서 후회가 없다는 걸 깨달았다. 만약 다시 되돌아가더라도 이렇게 준비할 것이다. 나는 내가 쓴 글이 마음에 들고, 참가한 팀 모두에게 감사와 존경을 표하며 기쁜 마음으로 글을 마무리하고 있다.
평가에 관해 하나 더 이야기하자면, AI 에 초점을 두는 것보다 문학과 도전에 중점을 두는 것도 좋은 전략이라 말하고 싶다. 이번에 수상하신 팀들의 대다수가 AI 의 초심자셨기 때문이다. 대회 당일에 처음 코드를 돌려보고 준비하신 분들도 많아보였다.
반대로 말하면, 놀라운 AI 기법을 보여준 팀들은 대다수가 수상하지 못했다. 그 점이 처음에는 충격으로 다가왔었다. 하지만 이 대회의 취지는 사람과 AI의 협업 글쓰기라고 말씀하신 걸 보면, 내가 좀 더 자신을 내려놓고 이 대회를 준비했어야 했던 것 같다. 이렇게 글을 쓰며 보니, 배울 점이 많다는 걸 깨달으며 겸손해지면서도 더 성장할 수 있어서 기쁘다.
그러니, AI에 자신 없더라도 두려워하지 않고 도전했으면 좋겠다. 이 대회에선 초심자의 용기와 도전만 있다면, 담대하게 나아갈 수 있을 것이다.
도움말
: 혹시 글을 좋아하는 사람이라면, '꿀팁'이라는 말을 쓰는 게 부담스럽다고 느꼈을 지도 모른다. 나는 그랬다. '꿀'이라는 단어를 붙여서 탄생한 신조어가 많은데, 하필 영어에 붙는 바람에. 인터넷에 검색해보니, 나 같은 고민을 하는 사람들이 제법 있나보다. 국립국어원에선 순화어로 '도움말'을 추천하길래 써봤다.

사실 배울 점이 곧 내가 드리고 싶은 도움말이기도 하다. 그리고 글 중간 중간에 숨어있을지 모른다. 하지만 정말 드리고 싶은 기본적인 도움말을 정리하고 싶어서 이렇게 다시 써보고자 한다.
- 2만자는 매우 길다. 미리 자신의 모델이 2만자에 적합한지 확인해보라.
- 어느 정도 데이터는 미리 모아두면 좋다. 모으는 코드나 대상을 조사하는 게 시간 절약에 큰 도움이 된다.
- 생성 코드에 대해 익숙해져야 한다. 서버를 괜히 미리 제공해주는 것이 아니다.
- 데이터에 따른 변화를 직접 글을 만들어보며 연습하면 좋다.
- 정성평가라도 다양한 평가지표가 있으니, 그 실험 과정을 발표에 잘 정리해두면 좋을 것 같다.
- 대회 당일에 초중반부터 미리 발표자료도 함께 작성하면 좋다.
- 대회에 열중하느라 사진을 찍는 걸 잊지 마시길. 이럴 때야말로 사진의 진가가 발휘된다고 생각한다.
- 팀이름에 신중하라. 발표순서는 사전순이라서 우리는 늘 마지막이었다....
- 팀원은 많을수록 좋다. 여러모로, 싸우지만 않는다면 매우 좋다고 생각한다.
소감
개인으로서
배울 점이 많았고 새해부터 이런 뜻깊은 경험을 할 수 있어서 감사하다. 솔직히 말하자면, 결과를 바로 수용하는 것은 어렵기도 했다. 무엇보다 우리 팀이 쏟았던 시간과 노력, 문학적인 전략과 AI 전략, 결과물, 발표 등 후회 없이 달려왔기 때문인 것 같다. 하지만 이 글을 쓰면서 내가 놓쳤던 부분들이 보였고, 겸손해졌다. 동시에 많은 것을 배웠다고 느낀다.
인정하는 자에게만 성장의 기회가 주어진다.
관계로서

글에서 눈치챌 수 있겠지만, 자연어 처리를 전공하고 싶어하는 대학생이다. 그래서 AI 전략이 뛰어난 사람들에게 시선이 갈 수 밖에 없었다. 대회 당일 새벽에도 그런 분들과 지나가다 이야기를 나눴고, 그들의 발표에 진정으로 박수를 보냈다.
대회가 끝난 후에 담소를 나눴고, 그들이 자신의 작업물을 공유할 수도 있다는 소식에 당당하게 연락을 보냈다. 이런 인연 역시 깊이 소중하다. 아래엔 함께 참가한 팀의 링크를 남겨두겠다.
- 참을 수 없는 GPT의 묵직함: https://github.com/sudokim/4th-Bookathon-The-Unbearable-Heaviness-of-GPT
- 부커부커: https://github.com/lastdefiance20/Bookathon2022_Team_Booker2
- 쿠봇: https://github.com/khu-bot/ai-essayist
팀으로서

우리는 정말 우리의 글처럼 서로 다른 사람들이 만나 하나의 글을 완성했다. 그렇게 우리만의 이야기를 만들어갔다. 처음 만난 5명이었지만 너무나 만족스럽다. 돌이켜보면, 내가 의견 내는 것을 좋아해서 부담으로 다가왔을 수도 있는데, 그 의견을 존중하고 실행에 초점을 맞춰서 그 선택들이 모두 정답으로 바뀔 수 있도록 이끌어준 것 같다.
대회 당일에도 서로가 피곤한 와중에도 각자 할 일에 집중하고, 빈 곳을 채워주며 끝까지 포기하지 않도록 힘을 내준 것 같다. 다들 무엇을 하든 잘 할 것이고 다음 발자취를 응원하고 싶다. 다시 한 번, 함께 긴 시간 고생했고, 감사하다는 말을 전해주고 싶다.
다음 대회에 얼마나 멋지고 근사한 글이 탄생할지 기대를 하며 글을 마치겠다.
참고 자료
https://arxiv.org/abs/1610.02424
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
Neural sequence models are widely used to model time-series data. Equally ubiquitous is the usage of beam search (BS) as an approximate inference algorithm to decode output sequences from these models. BS explores the search space in a greedy left-right fa
arxiv.org
'후기' 카테고리의 다른 글
| 2022 Uni-DTHON 데이터톤 후기 - 1등 (0) | 2022.11.07 |
|---|
