
자연어 처리 모델이 언어를 생성하는 방식에 관하여 잘 정리된 글이라서, 한글로 의역(수정)하고자 한다. 나에게도 공부가 되고, 이 글을 통해 한 사람이라도 도움이 된다면 기쁠 것 같다. 그리고 무엇보다 이렇게 좋은 글을 써준 patrickvonplaten 에게 감사드린다.
초록
초거대 언어 모델의 등장

자연어 처리 분야(NLP)에선 초거대 모델을 대거 등판하고 있다. 대표적으로 openAI 에서 공개한 GPT 시리즈가 있다. 사람들은 놀라운 성능을 몸소 확인했고, 이미 세상을 바꿀 준비를 하고 있다. 실제로 자연어 처리 관련 AI 서비스의 양과 질이 대폭 상승했다.

이게 가능했던 이유는 Transformer 의 등장과 pre-training 이다. 두 방식은 자연어 처리 근간을 이루는 혁신이었다. 텍스트 데이터를 효과적으로 학습할 수 있는 구조인 Transformer. 그리고 데이터 그 자체로도 많은 정보를 학습할 수 있는 방식인 pre-training. 이 둘의 만남은 마치 콜라와 멘토스처럼 폭발적인 영향을 미쳤다.
올바른 평가에 대하여

한국인끼리는 토익 만점이면 영어를 잘한다고 할 수도 있다. 하지만 원어민은 어떨까? 원어민이 토익 만점을 받았으면, 우리는 그 사람에게 영어를 잘한다고 말하는가? 원어민에게 토익은 자신의 영어 능력을 잘 드러낼 수 있는 지표일까?
아니다.
토익에는 회화를 평가하는 방식 자체가 존재하지 않는다. 우선 여기서부터 원어민의 영어 능력을 담아내기에 부적절한 지표다. 그 이외에도 다양한 요인들로 인해 토익은 어느 정도 수준 이상의 영어 능력을 평가하기엔 부적절하다고 볼 수 있을 것이다.

생성 모델도 마찬가지다.
모델은 충분한 자연어 처리 능력을 갖춘 것 같아도 생성방식에 따라 모델의 성능이 과대/과소 평가를 당할 위험이 있다. 만약 모든 생성 모델이 'greedy'하게만 시험을 본다면, 불공평하지 않겠는가. 마치 모든 한국인의 한국어 능력을 받아쓰기로만 평가하겠다라는 말과 같다.
모델의 생성 방식
(제대로 공부하고 싶다면, 이 글을 읽기 전 여기를 클릭하세요.)
저자는 초장부터 이렇게 말하는데, 이걸 보고 바로 이해하면 천재다.
In short, auto-regressive language generation is based on the assumption that the probability distribution of a word sequence can be decomposed into the product of conditional next word distributions.
차근차근 하나씩 단어를 뜯어서 이해해보겠다.
Auto-regressive langauge generation
이해를 돕고자, 두 문장을 준비했다.
- A: 새벽에 배가 고파서 라면을 끓여 [ _ _ _ ]
- B: 난 이제 지쳤어요 [_ _ _ _ ]
A, B 문장의 마지막 말에 들어갈 단어는 무엇일까? 상식적으로 각각 '먹었다.', '땡벌 땡벌' 이다. 모델이 하는 일이 정확히 저것뿐이다. 입력으로 문장을 주면, 딱 하나 덧붙여준다. 기억하자, 모델이 할 줄 아는 건 주어진 문장에 그럴듯한 거 딱 하나 붙이기.
하지만 사람들이 원하는 것은 긴 문장이다. 겨우 하나 만들라고 AI 연구를 했을 리가. 그래서 아래처럼 생성한 걸 이어서 자동적으로 넣어줬다. 처음에 '새벽에' 만 넣어서 얻은 결과다.
- 1번째 입력: 새벽에 [ 배가 ]
- 2번째 입력: 새벽에 배가 [ 고파서 ]
- 3번째 입력: 새벽에 배가 고파서 [ 라면을 ]
우린 이 과정을
- 원하는 길이만큼 자동적으로(auto)
- 문맥에 맞는 결과를 예측(regressive)하기 때문에
auto-regressive langauge generation 이라고 부르기로 했다.
product of conditional next word distributions
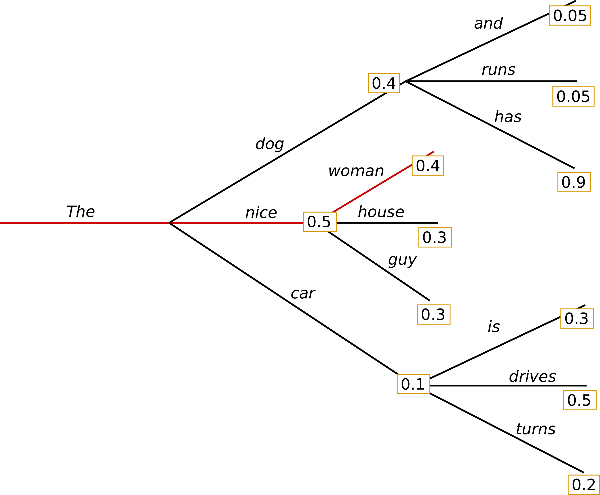
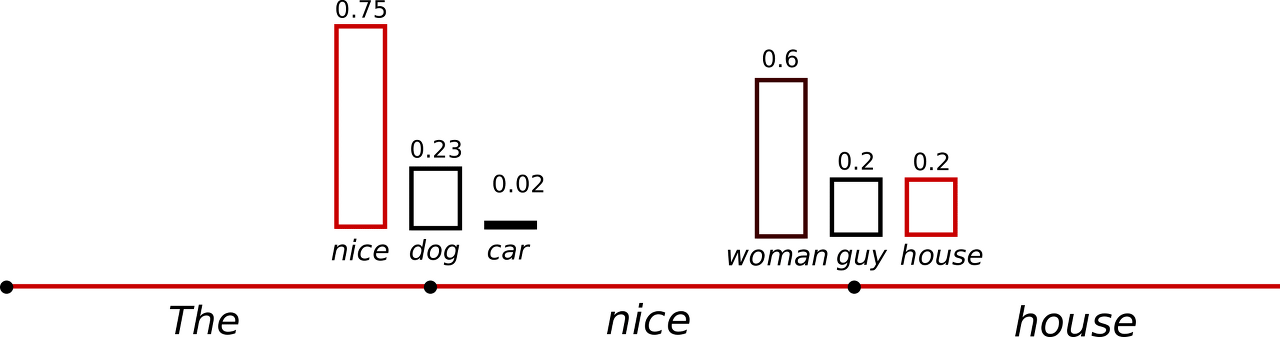
위 그림은 'The' 라는 입력이 모델에 들어왔을 때, 모델 예측 결과를 담고 있다. 위 그림을 보면 다음과 같은 사실들을 알 수 있다.
- 'The' 를 넣었을 때, 'nice' 가 나올 확률이 0.5 로 가장 높다.
- 'The nice' 를 넣었을 때, 'woman' 이 나올 확률이 0.4 로 가장 높다.
위 그림을 통해, 모델은 주어진 입력 문장에 따라 다음 단어의 확률을 결과로 도출한다는 점을 명확히 알 수 있을 것이다. 이게 확실히 이해가 되었다면, 차례로 아래 문장들이 이해가 될 것이다.
- 주어진 입력에 따라 확률이 달라지기 때문에 조건부(conditional) 확률이다.
- 단어마다 확률을 갖고 있으니, 확률의 곱(product)이 곧 해당 문장이 생성될 확률이다.
결국 우린, 모델이 어떤 문장을 생성할 확률은 product of conditional next word distributions 이라고 표현할 수 있다.
자, 다시 돌아가서 아래 문장을 읽는다면 이해할 수 있을 것이다.
In short, auto-regressive language generation is based on the assumption that the probability distribution of a word sequence can be decomposed into the product of conditional next word distributions.
How to generate text
이 글은 huggingface 에서 작성했다. 그러니 코드 예제가 당연히 필요하다. 원본 글에서는 Tensorflow 를 사용했지만, PyTorch 로 예제를 변경해서 작성했다. checkpoint 도 KoGPT2 를 사용한다.
pip install transformers # install transformers
그리고 tokenizer 와 model 을 불러오도록 하자.
from transformers import GPT2LMHeadModel, PreTrainedTokenizerFast
checkpoint = 'skt/kogpt2-base-v2'
tokenizer = PreTrainedTokenizerFast.from_pretrained(checkpoint)
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained(checkpoint, pad_token_id=tokenizer.eos_token_id)
그리고 오늘 예시를 담당해줄 prompt(입력) 을 정했다.
prompt = '중요한 건, 꺾이지 않는 마음'
# encode context the generation is conditioned on
input_ids = tokenizer.encode(prompt, return_tensors='pt')
Greedy Search
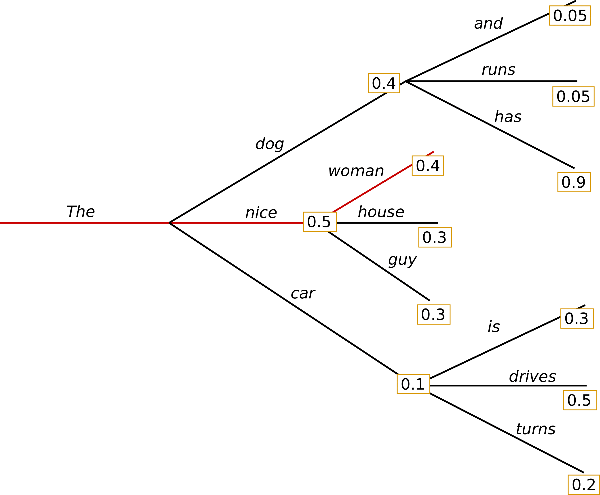
말 그대로 욕심(greedy) 가득한 방법이다. 욕심 많은 사람들의 특징이 뭔가? 욕심에 눈이 멀어 그때 끌리는 선택을 내린다. 주어진 상황에서 가장 이득이 되는(=가장 확률이 높은) 선택을 내린다.
위 그림에서 빨간선을 따라가면 그렇다. 'The' 를 넣었을 때 선택지가 (dog, nice, car) 3가지다. 각각 0.4, 0.5, 0.1 의 확률을 갖고 있으니 'greedy search' 를 따라간다면 'nice' 를 택하게 된다.
코드로는 이렇게 하면 된다. 참고로 'generate' method 하나로 모든 방식을 사용할 수 있다.
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
결과는 다음과 같다.
Output:
----------------------------------------------------------------------------------------------------
중요한 건, 꺾이지 않는 마음가짐이다.
그런데도 나는 그걸 모른다.
그건 내가 그걸 모를 때다.
그건 내가 그걸 모를 때다.
그건 내가 그걸 모를 때다.
그건 내가 그걸 모를 때다.
생각보다 그럴듯한 문장을 만들었다.
하지만 엄밀히 말해서 '그건 내가 그걸 모를 때다.' 라는 문장은 문맥에 어울리지 않는다. 게다가 벌써부터 반복(repeat)하는 문제점이 보인다. 이런 문제는 'greedy search' 와 'beam search' 방식에서 흔히 볼 수 있다고 한다. (자세한 건, Vijayakumar et al., 2016 과 Shao et al., 2017 을 참고해보자.)
'greedy search' 의 장점은 빠르다는 것이다. 그리고 어떤 문제는 'greedy search' 가 optimal 할 수 있다. 하지만, 그렇지 않은 경우가 더 많다. 즉 단점으론, 그 순간에는 좋은 판단이었으나 전체적으로 봤을 땐 그렇지 않을 위험이 있다는 것.
이 점을 해결하기 위해 'beam search' 가 등장한다.
Beam Search

빨간색 선의 개수가 2개로 늘었다. 모델의 예측 결과를 매번 확인하는 대신, 가장 높은 확률뿐만 아니라 2번째로 가장 높은 확률까지 함께 확인하는 것이다. 이 과정을 진행하다보면, 새롭게 등장한 경우의 수를 놓치지 않을 수 있다. 'greedy search' 보다 더 많은 경우의 수를 고려하게 된다.
위 그림의 빨간선을 단계별로 따라가기만 해도 알 수 있다.
- 'The dog' (0.4) < 'The nice' (0.5)
- 'The dog has' (0.4 * 0.9 = 0.36) > 'The nice woman' (0.5 * 0.4 = 0.2)
장단점은 다음과 같다.
- 장점: 'greedy search' 보다 언제나 높은 확률을 찾아낸다.
- 단점: 'greedy search' 보다 느리다. 여전히 최적의 결과라고 볼 수는 없다.
이 방법, 코드에선 어떨까?
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5, # 빨간선의 개수와 같은 의미다.
early_stopping=True # EOS 토큰이 나오면, max_length 보다 길이가 짧아도 종료할 수 있다.
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
중요한 건, 꺾이지 않는 마음가짐이다.
그런 마음가짐으로 살아가야 한다.
그런 마음가짐으로 살아가야 한다.
그런 마음가짐으로 살아가야 한다.
그런 마음가짐으로 살아가야 한다.
그런 마음가
'greedy search' 보다 낫다고 하기엔 애매하다. 문장의 길이도 짧고, 여전히 반복하는 문제가 있어서 그렇다. 반복하는 문제에 대한 간단한 해결책으로 n-grams ( penalties as introduced by Paulus et al. (2017) and Klein et al. (2017) ) 이 있다. 방법은 손수(manually) n-gram 이 반복되지 않도록 parameter 로 입력하는 것이다.
예컨대, no_repeat_ngram_size=2 이라고 넣으면 2-gram 이 반복되는 일은 없다.
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
중요한 건, 꺾이지 않는 마음가짐이다."
"그런데 그게 무슨 말입니까?"
그녀는 고개를 끄덕였다.
"어떻게 그런 말을 할 수 있단 말인가요? 그건 그렇고 말입니다."
더 이상 반복되지 않는다.
하지만, 문맥에 어울리게 생성했는지는 여전히 의문이다. 저자의 글에선 훌륭한 예시가 나왔지만, 나는 아니다. 결국 모델이 봐온 데이터가 중요하기 때문에, 'greedy search' 나 'beam search' 나 '중요한 건 꺾이지 않는 마음' 에 대해 잘 모르나보다.
하는 수 없이 'beam search' 가 추적한 5개 후보를 모두 출력해보기로 했다. num_return_sequences 에 출력하고 싶은 개수를 입력하면 된다. 당연히 num_return_sequences 은 num_beams 보다 커선 안된다.
# set return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
Output:
----------------------------------------------------------------------------------------------------
0: 중요한 건, 꺾이지 않는 마음가짐이다."
"그런데 그게 무슨 말입니까?"
그녀는 고개를 끄덕였다.
"어떻게 그런 말을 할 수 있단 말인가요? 그건 그렇고 말입니다."
1: 중요한 건, 꺾이지 않는 마음가짐이다."
"그런데 그게 무슨 말입니까?"
그녀는 고개를 끄덕였다.
"어떻게 그런 말을 할 수 있단 말인가요? 그건."
"아니요.
2: 중요한 건, 꺾이지 않는 마음가짐이다."
"그런데 그게 무슨 말입니까?"
그녀는 고개를 끄덕였다.
"어떻게 그런 말을 할 수 있단 말인가요? 그건 그렇고."
"아
3: 중요한 건, 꺾이지 않는 마음가짐이다."
"그런데 그게 무슨 말입니까?"
그녀는 고개를 끄덕였다.
"어떻게 그런 말을 할 수 있단 말인가요? 그건."
"아니오,
4: 중요한 건, 꺾이지 않는 마음가짐이다."
"그런데 그게 무슨 말입니까?"
그녀는 고개를 끄덕였다.
"어떻게 그런 말을 할 수 있단 말인가요? 그건."
"아니.
읽어보면 알겠지만, 생각보다 매우 근소한 차이를 보인다.
open-ended generation 에선, 'beam search' 가 최고의 선택이 아닌 이유로 3가지를 제시한다.
- Beam search 는 번역이나 요약처럼 길이가 적절할 때, 효과가 좋다. (see Murray et al. (2018) and Yang et al. (2018).) 하지만, dialog and story generation 처럼 open-ended generation 에선 그렇지 않다.
- Beam search 는 반복 문제가 심각하다. 이걸 해결하고자 n-gram 을 사용하는데, 각 분야나 목적마다 적절한 n-gram 을 찾아내는 건 매우 어려운 일이다
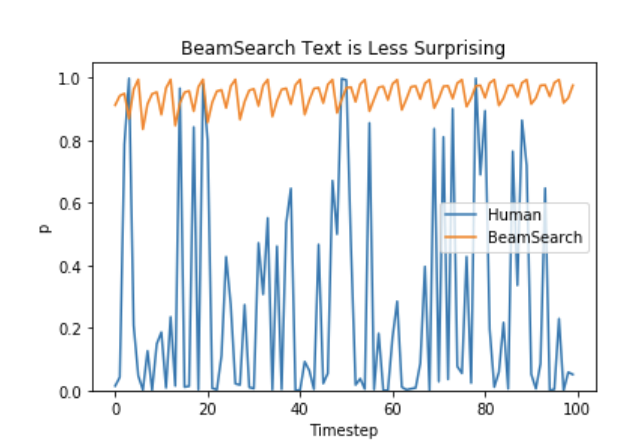
- Ari Holtzman et al. (2019) 에서 이야기하듯, 높은 수준의 문장은 확률순이 아니다. 확률을 잘 따라가봤자, 예측가능하고 뻔한 글이 된다. 즉, 지루하다. 아래 그래프가 이를 증명해준다.
Sampling
: 말 그대로 무작위로 뽑는 것을 말한다.
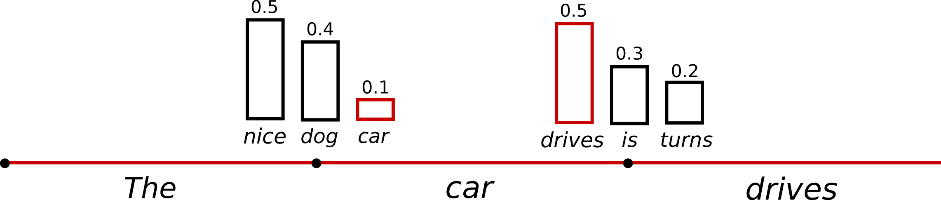
위 그림을 보면, 가장 낮은 확률인 'car' 가 뽑힐 수 있다는 걸 확인할 수 있다. 참고로 확률이 무시된 채로, 1 / 3 이 아니라 각 확률대로 뽑히는 게 sampling 이다.
아래 코드를 보자. do_sample=True 와 top_k=0 로 하자. top_k 는 나중에 이야기할테니, 일단 이렇게 해보자.
# set seed to reproduce results. Feel free to change the seed though to get different results
import torch
torch.manual_seed(2022)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
중요한 건, 꺾이지 않는 마음가짐입니다.
과거 ‘이재민은 잡지 않는다’ 이후 지구촌 핫 이슈(뉴스 포함)를 선정해 속보하는 새로운 매체가 나왔죠.
1990년대 후반 삼성물산의 레저·대용차 사업
결과를 보니, 확실히 무작위로 뽑았다는 게 느껴진다. 다만, 전혀 일관성이 없다. 이건 그럴 듯한 헛소리(gibberish)를 만들 수 있어서 위험하다.
그래서 한 가지 장치로 쓰는 건 'temperature' 다. 이 방식을 적용하면, softmax 의 결과가 빈익빈 부익부 형태를 띈다. 즉, 높았던 확률은 더 높아지고, 낮았던 확률은 더 낮아진다.
이걸 저자는 확률분포(probablitiy distribution)가 더 날카로워진다(sharp)라고 표현한다. 위 그림만 봐도 확률의 격차가 더욱 뚜렷해진 걸 볼 수 있다. 'temperature' 는 0 ~ 1 사이의 값으로, 낮아질수록 sharp 하게 바꾼다. temperature=0 일 때, 결국 sharp 하다 못해 'greedy search' 와 동일해진다는 걸 기억하자.
코드로 보자.
# use temperature to decrease the sensitivity to low probability candidates
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
중요한 건, 꺾이지 않는 마음가짐이라고 말한다.
이런 자세를 가진 사람이 마음가짐을 잘 지킨다고 한다.
패기 넘치고 정감 있는 성격이라서 주위에서 보거나 아는 사람들이 다 말했지만 다들 그런 것 같아요.
그런
확실히 결과가 새로우면서도 그럴싸해졌다. 하지만 마지막 문장은 인간이 썼다기에는 이상하다.
Top-k Sampling
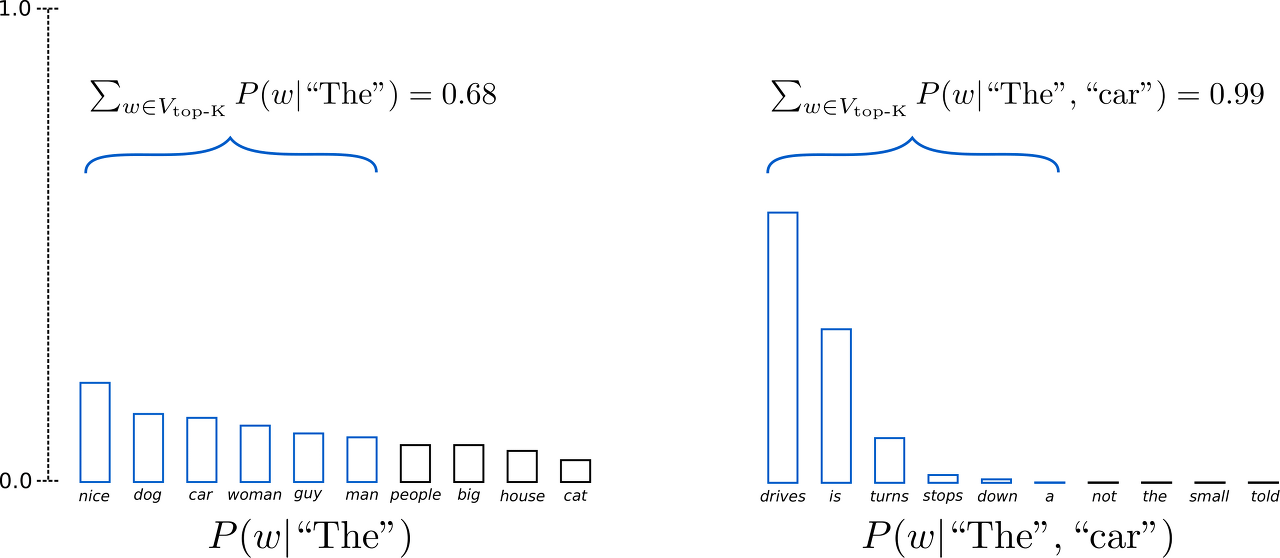
Fan et. al (2018) 가 제시한 방법으로, 높은 확률을 가진 특정 개수 중에서만 선정하는 걸 말한다. 위 그림에선 K=6 이다. 확률순으로 6개의 단어를 선정하고 그 중에서만 sampling 을 진행한다.
코드로도 진행해보자. top_k=50 으로 진행할 경우, 확률이 높은 순서대로 50개 후보에서 선정한다.
# set top_k to 50
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
중요한 건, 꺾이지 않는 마음에서 시작된다는 점이다.
나아가서 우리들은 항상 그런 마음이 중요하다고 생각한다.
그래서 우리끼리 서로의 마음을 나누며 살아갈 때 서로 다름이 없는, 그러니까 서로 신뢰할 수 있는 마음이 된다고 나는 생각한다.
지금은 많은
오, 확실히 더욱 그럴듯해졌다. 하지만, 잘 읽어보면 끼워맞춰주려고 해도 찜찜한 느낌은 남아있다.
그러나 저자는 여전히 남아있는 문제점을 하나 지적하는데, 바로 확률순으로 뽑다보니 다소 지루하고 뻔한 글이 탄생할 위험이 적지 않다는 것이다. 이를 위해 예시를 다시 보자.
처음(t=1)에 제거된 ("people", "big", "house", "cat") 는 그럴듯한 후보다. 그런데도, K 에 의해 제거되었다. 반면, 두번째(t=2)에서 제거된 ("not", "the", "small", "told") 는 제거하길 잘했단 생각이 든다. 이로 미루어볼 때, 특정개수 K 로 고정하는것이 문제가 될 수 있다는 생각이 들어야 한다.
결과적으로, 헛소리를 만들거나 창의성을 해치는 수단이 될 수 있다는 이야기다.
Top-p Sampling
위 문제를 해결하기 위해, Ari Holtzman et al. (2019) 가 Top-p- or nucleus-sampling 을 제시했다. 특정개수 K 가 아니라 특정 확률 p 를 경계선 삼아 sampling 을 시도한다.
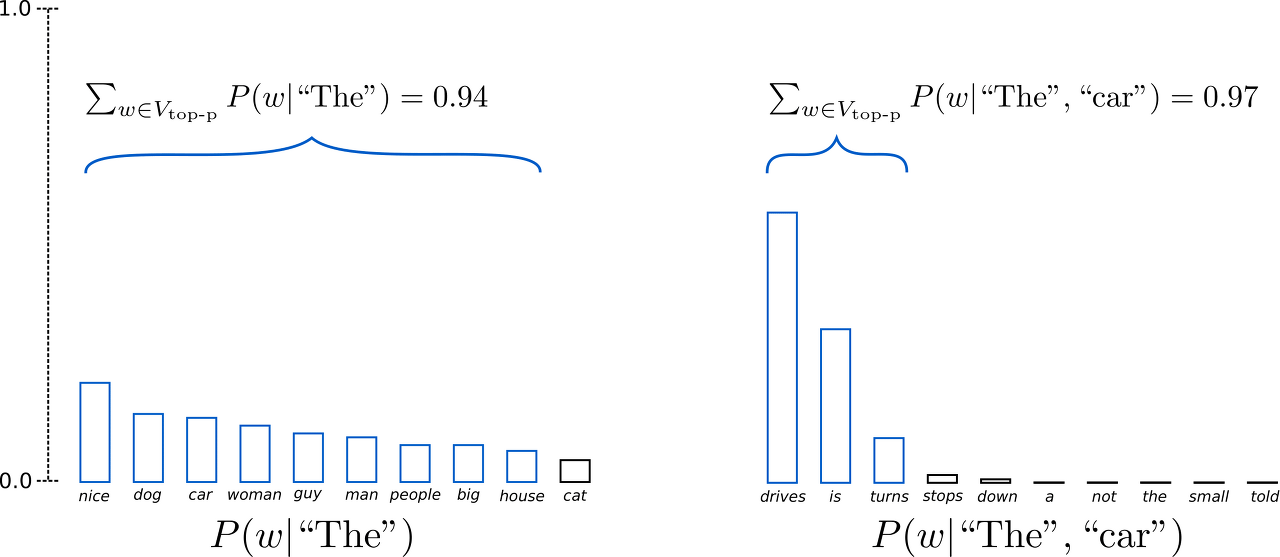
p=0.92 라고 가정하자. 왼쪽 그림을 보면 9개 파란색 단어의 확률을 합치면 0.94 가 된다. 즉, 0.92(p) 를 넘었기 때문에 더 이상 단어 후보를 추가하지 않는다. 오른쪽 그림도 마찬가지다. 3개의 파란색 단어 확률을 합치면, 0.97로 0.92(p) 를 넘었기 때문에 더 이상 단어 후보를 추가하지 않는다.
코드로 보자. top_k=0 으로 사용하지 않도록 유념하고, top_p=0.92 로 둬보겠다.
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
중요한 건, 꺾이지 않는 마음”이라고 말했다.
동시에 “(교육 당국이) 사드 문제 때문에 늘 그렇듯 사드가 들어갈 것도 아니고, 친북세력이 들어올 것도 아니다.”라고 말을 아꼈다. 김근태 의장은 이날 첫 상임
결과물은 내가 원하는 느낌이 아니어서 그렇지, 솔직히 정말 있을 법한 수준이다. 확실히 글의 수준이 한층 올라간 걸 느낄 수 있었다.
저자는 top_p 가 top_k 보다 좋은 것처럼 설명했지만, 실제로는 둘 다 훌륭한 성능을 발휘한다고 말한다. 그래서 둘을 적절히 섞는 것을 추천한다. top_k 를 통해 헛소리를 생성할 가능성을 배제하되, top_p 로 창의성을 보장하는 느낌으로 보인다.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}\n".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
Output:
----------------------------------------------------------------------------------------------------
0: 중요한 건, 꺾이지 않는 마음, 끈끈한 인내심을 갖고 꿋꿋하게 살아가는 사람이 성공하기 좋은 사회입니다.
성공은 항상 기쁨으로 가득 차게 됩니다.
하지만 불행하면 성공할 수 없습니다.
그런데도 왜 그렇게 많은 사람들이 실패에
1: 중요한 건, 꺾이지 않는 마음가짐이다.
그래서 나는 오늘을 살아가고 또 살 것이다.
내게 이 책을 바치는 건 내게 감사하고 또 감사하며.
그런데 어째서 나를 찾는 게 쉽지 않았는지 모르겠다.
왜 하필
2: 중요한 건, 꺾이지 않는 마음가짐이다.
그리고 나는 언제나 늘 항상 "저 사람 한번 잡아 봐!" 하는 마음으로 살고 있다.
그것은 당신이 아무리 자신을 믿어 주는다 할지라도 자신의 모습을 드러내지 않는 것이다.
나는 오늘 이렇게 말하고 싶다.
저자가 만든 예시는 여기서 훌륭한 결과를 보였으나, 내가 얻은 결과는 그렇지 않다.
당연히 그럴 수 밖에 없는 게, 내가 사용한 모델 'KoGPT2' 가 학습한 데이터가 "중요한 건, 꺾이지 않는 마음" 이라는 텍스트를 거의 본 적이 없을 게 분명하기 때문이다. (2022년 후반기 유행어니까.) 하지만 그래도 대충 보면, 그럴싸한 문장을 만들어준다. 이 정도면, fine-tuning 의 힘을 잘 빌려서 좋은 결과로 이어질 수 있겠다는 확신이 든다.
결론
저자는 최근 연구 결과에 따르면, 반복하는 이유가 decoding method 가 아닌 model 에 있다고도 알려준다. 그 이외에도 다양한 것들을 알려주는데, 이에 대해 궁금하다면 원본 글을 꼭 읽어보길 강력히 권한다.
내가 이 글을 쓴 이유는 단순히 decoding method 의 종류와 코드 및 결과를 제시하고 싶었을 뿐이다. 혹시나 generation 을 섬세하게 할 필요가 있다면, parameter 를 일일이 수정하거나 새로운 방식을 customize 해도 좋을 것 같다.
참고 자료
원본 제목: How to generate text: using different decoding methods for language generation with Transformers
원본 자료: https://huggingface.co/blog/how-to-generate
How to generate text: using different decoding methods for language generation with Transformers
How to generate text: using different decoding methods for language generation with Transformers Introduction In recent years, there has been an increasing interest in open-ended language generation thanks to the rise of large transformer-based language mo
huggingface.co
'NLP > huggingface' 카테고리의 다른 글
| [huggingface🤗] OSError: You are trying to access a gated repo (0) | 2024.03.22 |
|---|---|
| [huggingface🤗] Prompting? PEFT? 총정리 (3) | 2023.08.09 |
| [huggingface🤗] Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA (0) | 2023.06.27 |
| [huggingface🤗] 8-bit Matrix Multiplication for transformers (0) | 2023.06.23 |
| [huggingface🤗] How to generate text #2 (1) | 2022.12.28 |



