
서론
huggingface 에서 제공하는 함수 'generate' 는 매우 훌륭하다. 이에 대해 처음 듣는다면, 다음 글을 먼저 읽어보길 바란다.
https://heygeronimo.tistory.com/34
[huggingface🤗] How to generate text #1
자연어 처리 모델이 언어를 생성하는 방식에 관하여 잘 정리된 글이라서, 한글로 의역(수정)하고자 한다. 나에게도 공부가 되고, 이 글을 통해 한 사람이라도 도움이 된다면 기쁠 것 같다. 그리
heygeronimo.tistory.com
하지만, 아래 그림처럼 generate 의 parameter 개수만 45개다. 이걸 언제 다 읽고 사용해보나 싶더라.
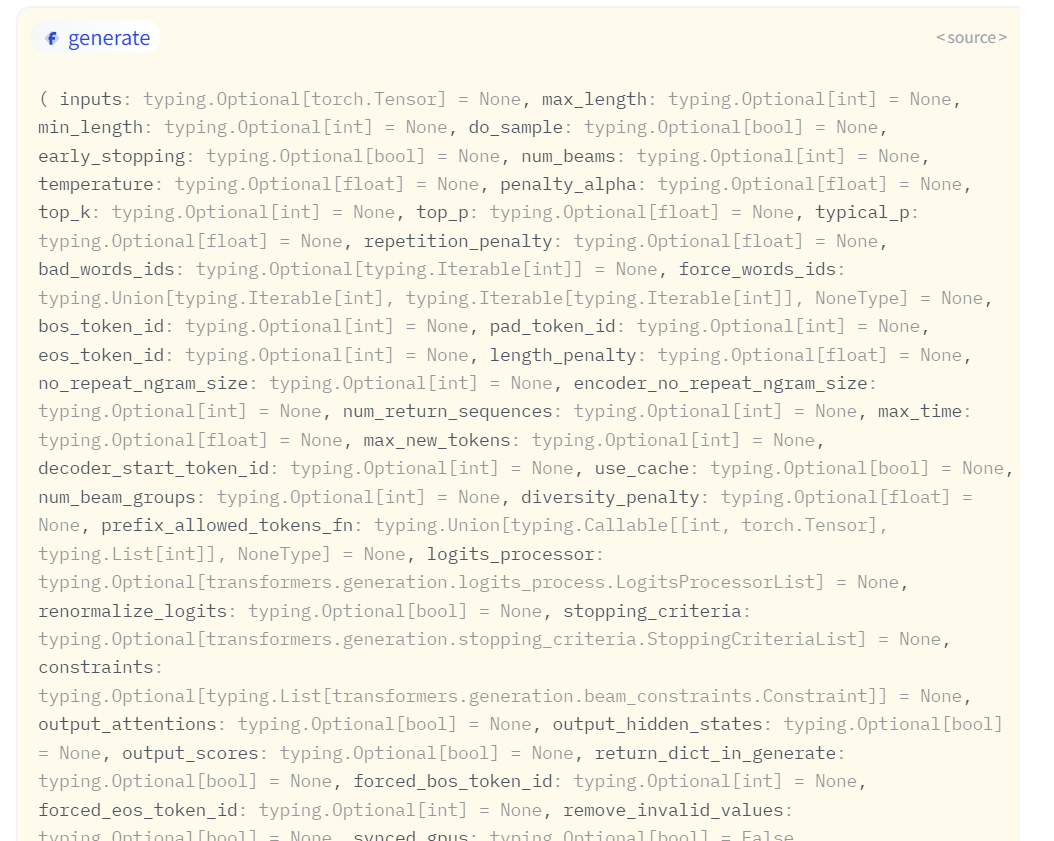
하는 수 없이 좀 더 찾아보다가 이전 블로그에 없던 내용을 발견해서 이어서 소개하고자 한다.
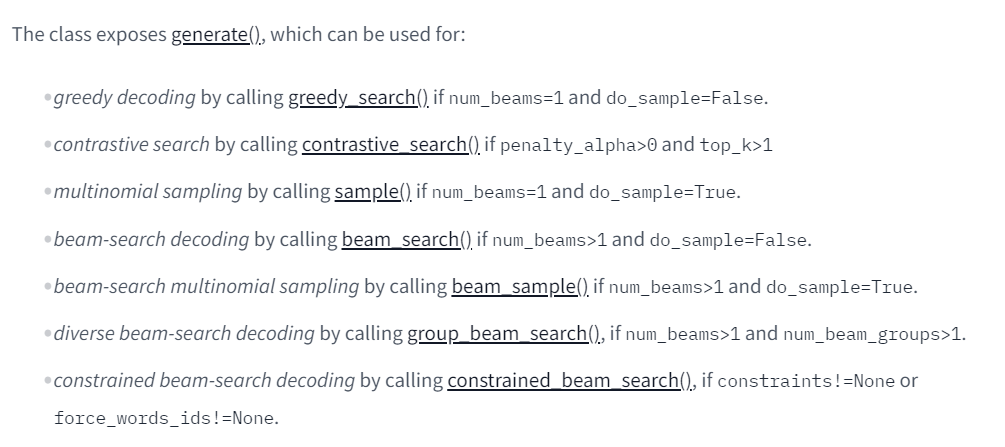
- 지난 글에 있던 내용: greedy_search, sample, beam_search
- 처음 등장한 내용: contrastive_search, beam_sample, group_beam_search, constrained_beam_search
오늘은 그중에서도 contrastive search 에 대해 설명해보고자 한다.
본론: contrastive search
해당 개념에 대해 소개하기 위해 이 글을 참고했음을 밝힌다. 'contrastive search' 는 NeurIPS2022 에 발표된 논문에 쓰인 방식으로, 인간 수준의 글쓰기가 가능하다고 한다. 이는 기존에 있던 언어 모델 모두에게 해당하는 말이다.
기존 Decoding 방식의 문제
기존 방식은 크게 2가지로 나뉜다.
- deterministic methods
- stochastic methods
1. deterministic methods - Greedy Search, Beam Search
deterministic methods 란, 언어 모델이 추측한 확률이 높은 순서대로 text 를 생성하는 방식을 말한다. 대표적으로 'greedy search', 'beam search' 가 이에 속한다. 이러한 방식은 예전부터 불필요한 반복(undesirable repetition)이나 부자연스러운 (unnatural) 결과물을 뱉는다는 문제가 있다.
2. stochastic methods - top-k sampling, top-p sampling
위와 같은 문제를 해결하기 위해, decoding process 에 무작위성(randomness)을 추가한 방식이 바로 'stochastic methods' 다. 대표적으로 'top-k sampling', 'nucleus sampling (also called top-p sampling)' 이 있다.
하지만 이러한 방식은 반복하는 문제는 해결하더라도, 문맥상 맞지 않는(incoherent) 단어들이 나타나기 시작하는 또 다른 문제가 발생한다. 이걸 부분적으로나마 'temperature' 를 통해 해결하고는 있다. 그런데 'temperature' 를 낮추면 낮출수록 'greedy search' 에 가까워지기 때문에 trade-off 관계에 놓인다.
사실 이 문제를 해결하는 것은 그동안 어려운 일이었다.
새롭게 등장한 Contrastive Search
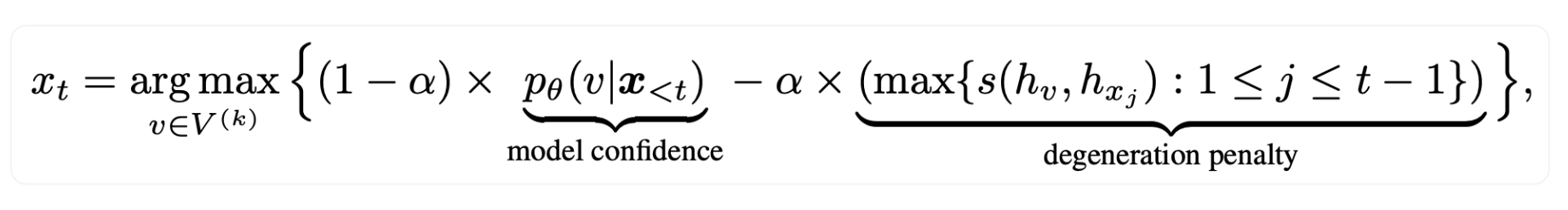
- Xt: t번째로 생성할 token
- V(k): top-k 범위에 포함된 distributions
model confidence
처음으로 등장한 단어는 'model confidence' 다. 이건 그냥 모델이 여태까지를 기반으로 token v 가 생성될 확률을 의미한다.
degeneration penalty
얼마나 기존에 생성했던 결과들과 구별되는가(discriminative)를 측정한다. 저기서 s 는 token representation 간의 cosine similarity 를 의미한다. 그리고 max 가 있으니, 그중에서도 제일 큰 값을 얻을 것이다. 즉, 기존에 생성했던 토큰과 유사한 토큰을 생성하려고 할수록 degeneration penalty 값은 크다.
식의 의미
다시 식의 생김새를 보자. α 는 이해를 돕기 위해 α = 0.5 라고 가정하고 식을 바라보자.
- model confidence: 모델이 다음 단어로 오면 적절하다고 판단한 확률
- degeneration penalty: 여태껏 생성했던 단어들과 유사한 정도
- 식의 의미: 다음에 오면 좋을 것 같은 단어이면서도 동시에 기존과 유사한 단어는 아니었으면 한다. 그래서 둘의 차이가 가장 큰 단어를 생성하겠다.
penalty_alpha(α)의 의미
위에서는 0.5 라고 가정했었다. 즉, 나는 model confidence 와 degeneration penalty 모두 반반 믿겠다고 볼 수 있겠다. 만약 모델에 대해 신뢰도가 크다면 값을 낮출수록 좋다. α = 0.2 이라고 한다면, 8:2 비율로 각각 중요도를 주겠다는 것이다. 이건 조금씩 변경해가면서 결과를 살펴가는 것이 좋아보인다.
penalty_alpha: (float, optional, defaults to model.config.penalty_alpha or None if the config does not set any value) — The values balance the model confidence and the degeneration penalty in contrastive search decoding.
Huggingface 사용법
contrastive search by calling contrastive_search() if penalty_alpha > 0 and top_k > 1
- penalty_alpha 는 위에서 설명했으니 값을 바꿔가며 넣어주면 된다.
- top_k 는 model confidence 가 높은 순서대로 단어 후보 개수를 제한한다.
아래 예시를 돌려보면 결과를 얻을 수 있다. 다만 결과를 함께 첨부하진 않았는데, 한국어 모델(KoGPT) 는 데이터가 뉴스나 모두의 말뭉치 등 문학적/일상적 대화에 능숙하지 않아 정성 평가가 어렵기 때문이다. 차라리 영어 블로그에 들어가서 영어 본문을 읽어보는 것이 훨씬 도움이 될 것이다.
prompt = '중요한 건, 꺾이지 않는 마음'
# encode context the generation is conditioned on
input_ids = tokenizer.encode(prompt, return_tensors='pt')
beam_output = model.generate(
input_ids,
penalty_alpha=0.6,
top_k=4,
max_length=512
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
나머지 방법들(beam sample, group beam search, constrained beam search)은 다음 글에서 이어서 소개하겠다.
참고 자료
https://huggingface.co/blog/introducing-csearch
Generating Human-level Text with Contrastive Search in Transformers 🤗
Generating Human-level Text with Contrastive Search in Transformers 🤗 1. Introduction: Natural language generation (i.e. text generation) is one of the core tasks in natural language processing (NLP). In this blog, we introduce the current state-of-the-
huggingface.co
Generation
Class that holds a configuration for a generation task. A generation configuration file can be loaded and saved to disk. Loading and using a generation configuration file does not change a model configuration or weights. It only affects the model’s behav
huggingface.co
- A Contrastive Framework for Neural Text Generation: (1) Paper and (2) Official Implementation.
- Contrastive Search Is What You Need For Neural Text Generation: (1) Paper and (2) Official Implementation.
'NLP > huggingface' 카테고리의 다른 글
| [huggingface🤗] OSError: You are trying to access a gated repo (0) | 2024.03.22 |
|---|---|
| [huggingface🤗] Prompting? PEFT? 총정리 (3) | 2023.08.09 |
| [huggingface🤗] Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA (0) | 2023.06.27 |
| [huggingface🤗] 8-bit Matrix Multiplication for transformers (0) | 2023.06.23 |
| [huggingface🤗] How to generate text #1 (0) | 2022.12.09 |



