계기
NLP 분야를 공부하다 보면, Prompting, prompt tuning, soft prompt, p-tuning, prefix-tuning, In-Context Learning 등 다양한 용어들 때문에 헷갈린다. 하지만 새로운 분야와 방법이 등장하며, 점차 자리를 잡아가는 과정이기 때문에 이런 혼란스러움은 필연적이다. 그래도 한번 정리할 필요가 있겠다 싶어서 나름 정리 해봤다. 아무리 검색해봐도 제대로 정리한 이미지는 찾지 못했다.
기준
NLP 분야에서 어느 정도 권위가 있는 huggingface 문서를 따랐다. 개인적인 의견이 담긴 블로그나 논문보다는 그나마 가장 객관적이라 판단하였다.
https://huggingface.co/docs/peft/conceptual_guides/prompting
Prompting
🤗 Accelerate integrations
huggingface.co
https://huggingface.co/docs/peft/index
PEFT
🤗 Accelerate integrations
huggingface.co
정리

- 갈래가 갈리기 시작하며, 이렇게 변화해왔으며 파란색과 빨간색의 크기가 커졌다고 보면 된다.
- 제목에 써놨듯이, p 가 들어간 녀석들이 문제다. 논문을 제대로 봐도 헷갈릴 수 있으니 하나씩 정리해보겠다.
Prompting
- 우선 이 단어부터 정리해야 한다.
- huggingface 에서 정의한 걸 그대로 번역해서 옮겨보겠다.
Prompting primes a frozen pretrained model for a specific downstream task by including a text prompt that describes the task or even demonstrates an example of the task. With prompting, you can avoid fully training a separate model for each downstream task, and use the same frozen pretrained model instead.
- frozen pretrained model: 우선 model parameter 가 frozen 되어야 한다는 전제가 필요하다
- including a text prompt: 텍스트 형태의 프롬프트를 포함해야 한다. 단, 인간의 눈에 보이듯 명확한 글자가 아니여도 되는데, 이건 곧바로 이어 나오는 soft prompt 에서 설명하겠다.
hard prompt & soft prompt
- hard prompt (discrete): 손으로 직접 작성한 입력 토큰을 의미한다. 노력이 많이 든다고 한다.
- soft prompt (continuous): learnable, 즉 학습가능하며 input embedding 과 함께 넣어준다고 한다. 즉, 모델은 frozen 인데, 입력 벡터를 넣어서 학습해준다고 한다. 이건 읽을 수가 없는데, 벡터이기 때문이다.
여기까지 봤을 때, 위 그림에서 prompting 으로부터 hard prompt, soft prompt 가 나온다.
prompt design & prompt tuning
- soft prompt 나 hard prompt 에서도 갈래가 나뉜다
- prompt design: 직접 사람이 수작업을 통해 좋은 프롬프트를 제작 및 설계하는 행위
- prompt tuning: 데이터셋에 맞춰서 학습/조율하는 행위
hard prompt 와 prompt design 이 똑같은 건 같은데, 이렇게 나눈 이유는 'AutoPrompt' 라는 논문 방식 때문이다. hard prompt, 그러니까 사람이 읽을 수 있는 프롬프트를 tuning 하며 찾는 방식을 제안한 논문이 있어서 갈래를 나눴다. 즉, hard prompt 방식에서 learnable 이 포함될 수 있어서 나눴다.
In Context Learning
- hard prompt 를 design 하는 분야로서, API 형태와 거대모델의 등장으로 학습이 불가능할 때 유용하여 발전한 분야다.
- 이건 검색해도 나오고, 교통 정리를 위한 글에선 이 정도만 해도 될 것 같아 넘긴다. 궁금하다면, 이걸 참고해보길.
Prompt tuning vs Prefix tuning vs P tuning v1 vs P tuning v2
- 난 이 녀석들이 제일 싫었다. 이름도 비슷해서 부르는 게 헷갈렸다.
- 우선 모두 모델을 frozen 한 상태에서 일부만 업데이트하기 때문에 soft prompt 로 분류한다.
Prompt tuning
- 입력 단계에서 task 별로 프롬프트가 들어가 학습되고 있다
- 맨 앞에 넣어주는 것이 특징이다
Prefix tuning
- prompt tuning 과 매우 유사하다
- 하지만 다른 점은 모든 레이어에 파라미터가 추가된다는 점이다
- 자세한 논문이 읽고 싶다면 여기를
P tuning v1
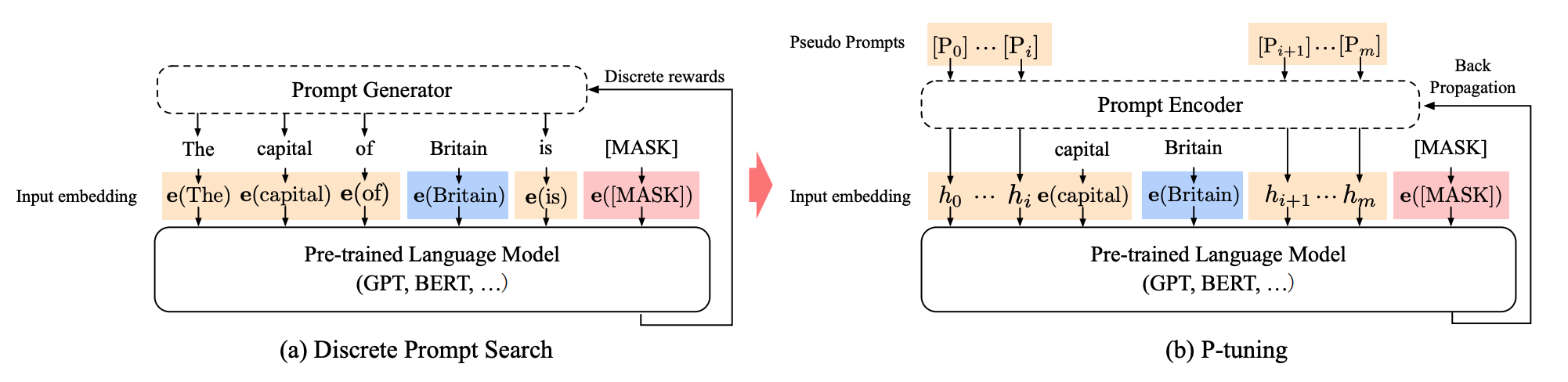
- 맨 앞에 넣어야 할 필요가 없이 중간에 삽입이 가능하다
- 입력 단계에만 추가된다
- anchor tokens 이라고 해서 학습을 돕는 토큰이 있다. 위 그림에선 capital 이 여기에 해당한다.
P tuning v2
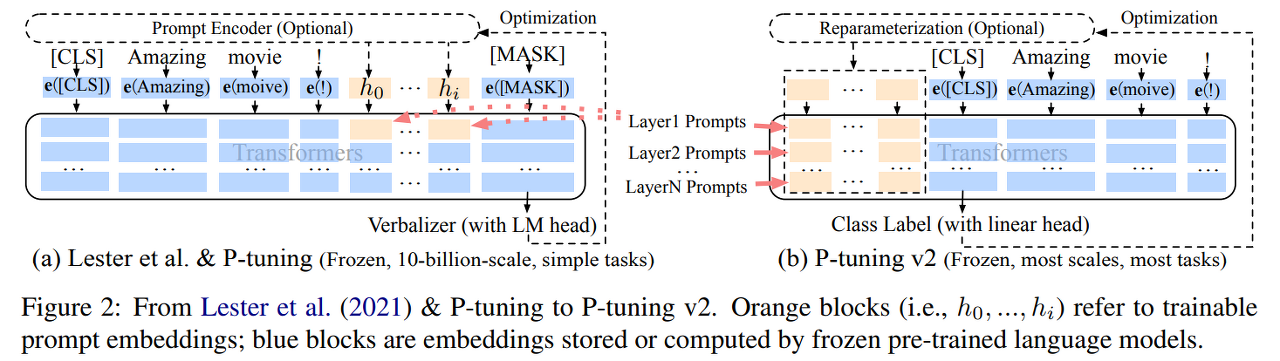
- v1 과 달라진 점은 모든 레이어에 삽입하게 되었다는 것이다
왜 LoRA, IA3 같은 녀석들은 soft prompt 가 아닐까
- prompting 의 정의를 따랐기 때문이다
- 즉, 입력 단위에서 프롬프트가 포함되어야 prompting 갈래에 포함될 수 있다.
- 그 대신, 더 넓은 범위인 PEFT엔 속한다.
Parameter Efficient Fine Tuning
: 말 그대로 효율적으로 fine tuning 을 할 수 있다면, 모두 속할 수 있다. 그래서 model 을 frozen 한 채, 일부 파라미터만 학습하면 모두 이곳에 포함된다.
'NLP > huggingface' 카테고리의 다른 글
| [huggingface] 대용량 데이터셋 로컬 다운로드 방법 (1) | 2024.10.22 |
|---|---|
| [huggingface🤗] OSError: You are trying to access a gated repo (0) | 2024.03.22 |
| [huggingface🤗] Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA (0) | 2023.06.27 |
| [huggingface🤗] 8-bit Matrix Multiplication for transformers (0) | 2023.06.23 |
| [huggingface🤗] How to generate text #2 (1) | 2022.12.28 |


