논문명: The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
논문 링크: https://arxiv.org/abs/2402.17764
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It ma
arxiv.org
이게 가능하다면, 엔비디아의 독주를 막고 AI의 새로운 혁명이 일어날 수도 있다고 한다. 그래서 한 번 읽어봤다.
아이디어(숲)를 먼저 이해하고, 논문(나무)을 해석하겠다. 그러니 숲을 먼저 보자.
1번째 숲: 왜 1비트가 대단한거야?

- 원래 컴퓨터가 이진법을 통해서 모든 걸 표현한다는 건 다들 알고 있다
- 요즘 뜨거운 AI 모델(사람)은 파라미터(세포)로 구성되어 있고, 파라미터 1개당 32비트를 사용한다
- 여기서 파라미터에 사용되는 비트가 많을수록 숫자를 훨씬 자세히 표현할 수 있다
- 하지만 파라미터 1개당 비트가 많이 쓰인다는 건 연산도 메모리도 엄청나게 필요하다는 의미다
- 그래서 FP16, BF16, 양자화 등 온갖 방법을 통해 파라미터의 크기를 최소화하려는 시도가 있었다
- QLoRA 같은 방법도 겨우 8비트까지 줄였는데.....뭐? 1비트?
- 1비트면 이론상 기존 모델들이 32비트를 썼다는 가정하에 32배나 가벼워진 셈이다
좋아, 1비트면 가벼워진다는 건 알겠어.
근데 왜 엔비디아까지 건드리는거야?
32비트나 1비트나 GPU에서 하면 더 빠르잖아?
2번째 숲: 곱셈이 사라져버린 구조
FP16
- FP16을 모를까봐 간단히 말하자면, 32비트 연산을 16비트에서 진행하면서도 성능을 거의 유지하는 방법론이다
- 하지만 16비트 역시 실수를 표현해야 하기 때문에 행렬곱(주황색 연산)을 진행해야 한다
1(.58)-bit
- 사실 1비트는 버림으로 계산한 거고, 정확히는 1.58비트다
- 숫자를 단 3개밖에 사용하지 않는다. 즉 1, 0, -1 로만 표현한다
- 그러니 실제로 행렬곱을 진행해보면, 곱셈이 아니라 뺄셈과 덧셈으로 이뤄진다
- 그러므로 행렬곱에 특화된 GPU가 없이 뺄셈과 덧셈만 잘 하는 하드웨어면 된다
3번째 숲: 못 믿겠어, 실험해서 결과로 이야기해봐
: 누구나 실험하기 전엔 그럴싸한 아이디어는 있어. 실험 결과 있어?
성능 측면 실험
- 같은 파라미터 혹은 비슷한 파라미터로 실험한 결과, 우선 성능은 비슷하거나 더 높다
속도 및 메모리 측면

- Latency, Memory Consumption, Throughput 네가 뭘 좋아할지 몰라서 다 준비해봤어...> <
- Y축은 지수형태로 되었는데도 격차가 벌어진다는 건 대단한거다....
이쯤에서 잠시 제 소견이 있겠습니다
: 이제 찬물을 끼얹어볼 시간입니다.
1. 저자가 오픈소스를 아직 공개하지 않았다
https://huggingface.co/papers/2402.17764
Paper page - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
@brandf It doesn't address the packing question, but now that you say, with practically free bit shifts, one could avoid multiplication up to (-2, -1, 0, 1, 2) with evenly spaced weights, and even (-4, -2, -1, 0, 1, 2, 4) doesn't look too bad.
huggingface.co
- 물론 여기 댓글에 가보면, 저자가 직접 여러 가지 이야기를 하고 있다. 오픈 소스를 공개할 것이라는 점, 더 큰 모델에 대해서도 실험하고 있는데 준비가 되면 공개하겠다는 점도 말이다.
- 다른 사람들이 재현했을 때도 유사한 결과가 나와야 의미가 있다는 건 누구나 다 아는 사실이다.
2. 그래서 정말로 써먹을 만한가?
- ChatGPT가 잘 된 이유는 논문의 성능이 뛰어나서가 아니라 사람들이 썼을 때 특이점을 느꼈기 때문이다
- 예컨대, QLoRA 와 같은 효과적인 학습방법을 직접 생성 모델에 적용한 바 있다. 논문에선 Full Fine-tuning 에 버금간다고 했으나 막상 학습해보니 생성 질이 좋지 않았다. 정성 평가, 정량 평가조차도 보통 유리하게 측정되는 경우가 많으며 실제 현실에 영향력을 끼치는 것은 다른 이야기다.
- 하지만 써봤는데 정말로 차이가 없다? 그리고 거대모델에서도 적용이 가능하다? 그렇다면 당장 무엇이 오르고 무엇이 내릴지 추측하라. ChatGPT가 탄생한 날, 엔비디아를 샀어야 하듯이 말이다. (투자는 매우 복합적인 영역이니 저는 책임 안 져요.)
자, 이제 숲을 봤으니 자세히 나무를 보러 가시죠.
논문 요약
- 요새 거대 모델들이 등장하면서 파라미터를 효율적으로 사용하는 연구가 활발해졌다
- 우리는 1비트, 즉 {-1, 0, 1} 로만 파라미터를 표현하는 방법론을 제시한다
- 실험 결과, 같은 파라미터 크기를 가진 기존 모델들과 성능이 비슷하거나 더 높다
- 심지어 Latency, Memory Consumption, Throughput 측면에선 훨씬 효율적이다
관련 연구
: 여태까지 4bit 까지 줄여서 사용한 관련 연구는 있는데, 최초로 1비트 논문을 쓴 게 본 논문의 저자들이다.
https://arxiv.org/abs/2310.11453
BitNet: Scaling 1-bit Transformers for Large Language Models
The increasing size of large language models has posed challenges for deployment and raised concerns about environmental impact due to high energy consumption. In this work, we introduce BitNet, a scalable and stable 1-bit Transformer architecture designed
arxiv.org
- 작년 10월 경에 BitNet 이라는 논문을 같은 기관에서 낸 적이 있다
- 이때는 진짜 1비트, 그러니까 {-1, 1} 로만 표현을 했다고 한다
- 지금과 차이점은 '0' 을 추가했다는 점? 그래서 정보량이 log 2 (1비트)에서 log 3 (1.58비트)로 증가했다는 점뿐이다. 그런데 여기서 '0' 을 추가한 것만으로도 성능이 상당히 올랐다고 한다.
방법론
: 기존 연구에 비해 딱 2가지가 바뀐다고 한다.
1. Quantization Function
: 당연히 기존엔 -1, 1 로 했던 걸 -1, 0, 1 로 양자화할 수 있도록 바꿔야 한다

- Weight(파라미터)를 {-1, 0, 1} 에 속하도록 위 함수를 적용했다고 한다
- 이런 건 어려울 게 없고, 맨 밑에서부터 해석하면 쉽다.
- Gamma: W (n x m) 의 각 요소의 절댓값을 모두 더한다. 그리고 개수만큼 나눈다. 이게 의미하는 건, 대충 평균이다. 대충을 붙인 이유는 음수는 절대값을 붙이면서 정확히 평균은 아니기 때문이다. 어쨌든 Gamma 는 평균보다 확실히 높은 숫자가 된다.
- 그러면 이제 round(x) 만 보면 된다. 여기서 x 는 W / Gamma 다. 여기서 round 는 소수점첫째자리에서 반올림하면서 정수가 되도록 만드는 것 같다.
- 이 식을 통과하면, 각 원소가 1, 0, -1 중 하나로 결정된다.
2. Activation Scaling
: 솔직히 이거 이해하려면 직전 논문을 읽어야 하는데, 그러고 싶지 않다.... 그리고 대충 읽어보면 음음 하고 넘어갈 수 있다.


실험 결과
모델
- FP16 LLaMA 랑 붙는다
- 공정한 대결을 위해 pretraining 과정, 모델 구조, 하이퍼 파라미터 등 모든 부분을 동일하게 구성했다고 한다

- 같은 파라미터에선 2.71배 빠르고, 3.55배나 메모리를 절약하는데 성능이 더 좋다고 한다
- 갑자기 3.9B 는 왜 있지? 라고 생각할 수 있는데 파라미터의 크기를 키울수록 성능이 더 좋아진다는 가능성을 보여주려고

- 다양한 데이터셋에서 같은 파라미터로 비슷하거나 더 좋은 성능을 보여준다
- 여기서도 3.9B로 늘리니까 더 잘하는 걸 볼 수 있다. 더 큰 파라미터도 자신 있다 이말이다.
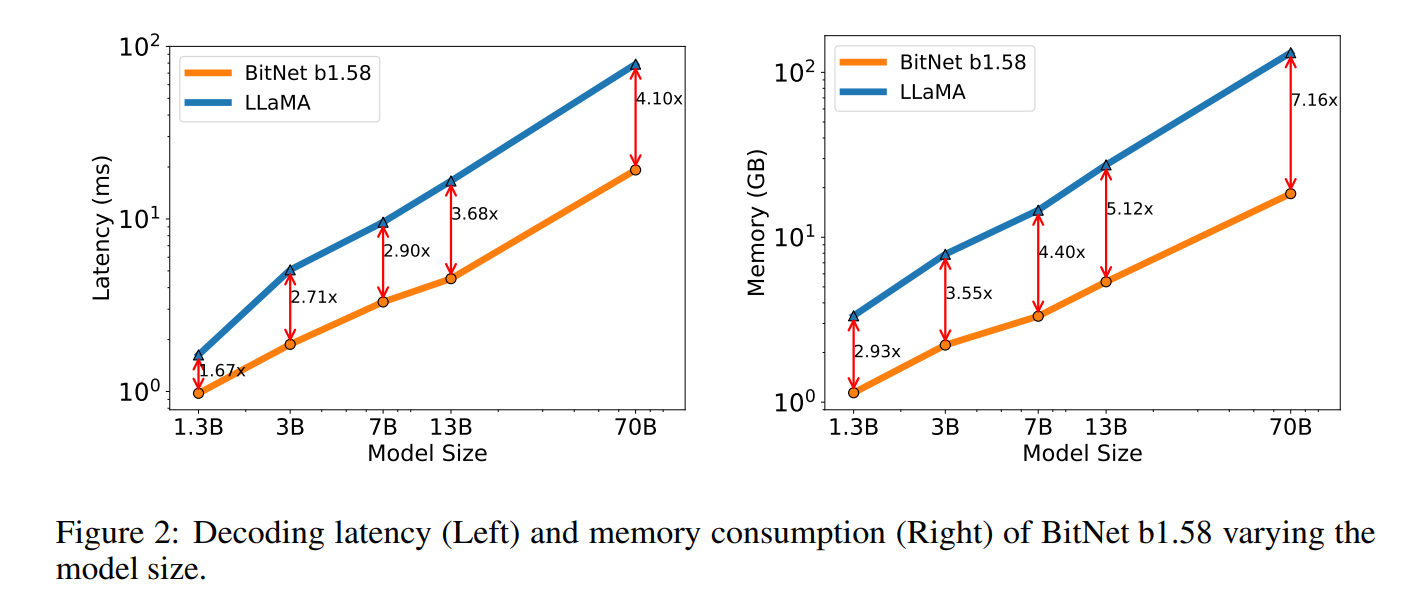
- 파라미터를 크기를 키우며 Latency 와 Memory 사용량을 측정했다
- 그 결과, 크기가 커질수록 격차를 벌리는 것을 보여준다. 즉 앞으로 모델의 거대화에 있어서 이 방법론이 더욱 효과적/효율적이라는 걸 실험적으로 증명했다.
- 기업의 입장에선 비싼 장비 비용, 엄청난 전기세 등에 대한 부담을 덜 수 있고 정부의 입장에선 친환경적인 방법으로 볼 수 있어서 요즘 경향과도 잘 맞다.
Both latency and memory were measured with a 2-bit kernel, so there is still room for optimization to further reduce the cost.
- 이런 구절이 Figure 2와 함께 있었는데 2-bit kernel 이 무슨 소리인지 모르겠다.
- 아무튼 더 최적화할 부분이 있었는데, 봐준거라고 보면 될 것 같다.

- Energy 라는 단어를 논문에서 처음 봤다 (제 실력이 부족해서겠지만요). 여기서 Energy 는 곱셈과 덧셈과 같은 행렬 연산이 대부분 해당한다고 한다. 측정 결과, 무려 71.4배나 효율적이다.
- 오른쪽은 크기를 키워가며 Energy 를 측정한 결과다. 역시 점점 격차를 벌린다.
- 이렇게 격차가 벌어지는 이유는 nn.Linear 가 거대모델이 될수록 크기가 커지기 때문이라고 한다. 저 부분에 기술이 적용되기 때문에 가능성이 무궁무진한 것.

- Sequence Length = 512 기준, Batch Size 도 11배나 더 올릴 수 있다고 한다 (2 X 80GB A100 기준)
- Throughput 도 8.9배나 더 뛰어나다

- 어 뭐야, 똑같은 문장을 3번이나 말하네? 자랑하고 싶은건가요?
- 그런 건 아니고, 잘 보면 처음과 끝의 파라미터(B)가 다르다.
- 대충 내가 (BitNet) 파라미터 많이 써도 FP16 보다 효율적인데 이 말이다. "내가 자동차 13대 굴려도 네가 3대 굴리는 것보다 기름값이 덜 나와." 이런 뜻.

- 현재 3B 에서 가장 세다는 StableLM 은 2T 개의 토큰으로 학습했다고 한다.
- 다들 아시다시피, 데이터셋의 크기가 성능에 지대한 영향을 미친다.
- 그래서 2T Token 으로 학습해서 붙었더니, 우리 모델이 또 이겼더라.
우리 아들이 또 전교 1등했더라.
앞으로에 대하여: 그대들은 1비트로 어떻게 살 것인가

- 여기다가 Mixture-of-Experts 같은 방법론을 붙이면 어떨까?
- 전교 1등에게 일타 강사로 과외한다면 어떨까와 같은 논의인데 흥미롭다....

- 언어 모델의 고질적인 문제 중 하나는 긴 길이를 잘 다루지 못한다는 거
- 효율적인 구조를 제시했으니 이제 어떻게든 해결할 수 있지 않겠어? 라고 말씀하신다

- 가볍고 성능 좋으면 뭐다? 바로 온디바이스 AI, 모바일 AI 로 만들어버린다 ~

- 이게 진짜 좀 먹힌다? 그러면 전용 하드웨어를 만들어야 한다
- 그러면 엔비디아는 뭐해야 한다? GPU 말고 1비트 전용 하드웨어 만들어야 한다 ~
개인적으로 논문은 매우 쉬운데 구현이 궁금하다. 누가 구현해주기 전에 빨리 공개해줘, 마이크로소프트! 현기증 난단 말이야....



