논문 설명만 보고 싶으신 분들은 글을 조금 내려주세요.
실험직전까지만 해석하니, 참고바랍니다.
오타 교정
: 비록 본 논문은 Apple 에서 작성하였으나, 오타가 여러 군데 보여서 부득이하게 교정하고 시작하겠다. 물론 내 식견이 모자랄 확률이 가장 클테니 이상이 있다면 알려주시면 감사드리겠습니다.
5페이지 일부

[수정 전]
In particular, we create DataCompDR-1B and DataCompDR-12M by reinforcing DataComp-1B and DataCompDR-12M.
[수정 후]
In particular, we create DataCompDR-1B and DataCompDR-12M by reinforcing DataComp-1B and DataComp-12M.
- 사소한 오타이긴 하나, DataComp 가 뭔지 몰랐던 나에겐 막히는 문장이었다
6페이지 일부

[수정 전]
λ = 0: regular CLIP training
λ = 1: distillation loss only
[수정 후]
λ = 1: regular CLIP training
λ = 0: distillation loss only
근거는 본 논문의 손실 함수를 살펴보면 된다.
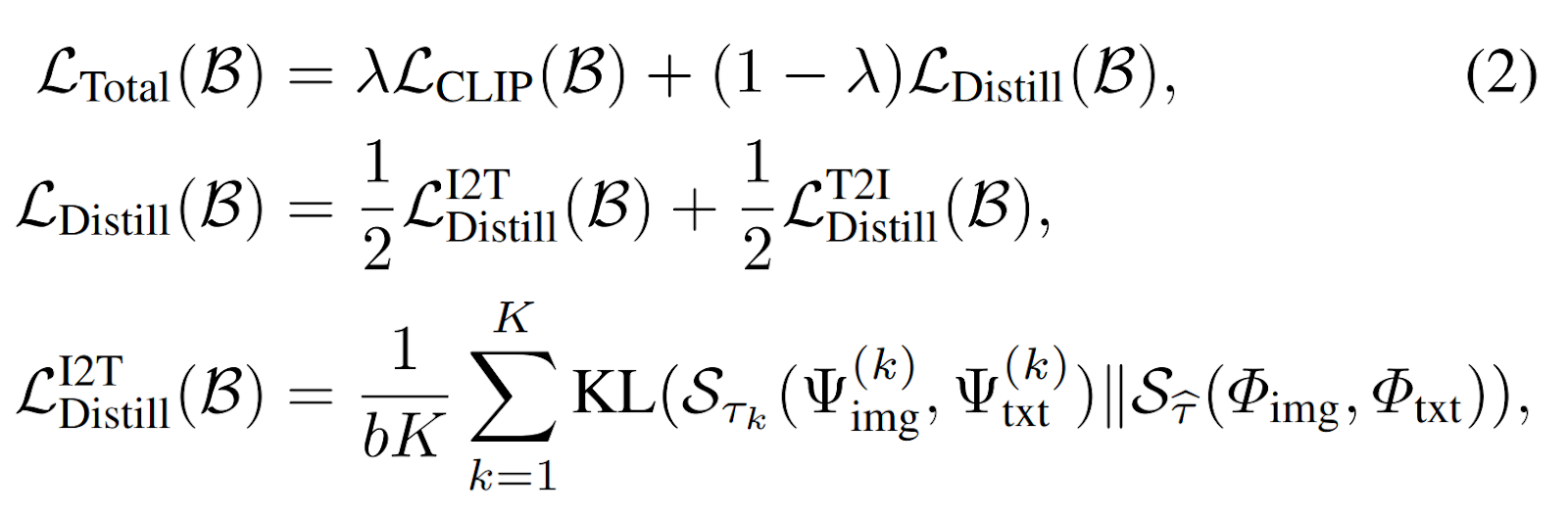
- 이로 인해 정확하게 알 수 없는 점이 생겼다.
- 바로 lambda = 0.7 일 때가 어느 쪽이 0.3 이고 어느 쪽이 0.7인지 말이다.
(이메일을 보내고 싶었는데 저자 이름을 넣고 검색해도 나오질 않는다. 링크드인 가도 이메일이 없으셔서 부득이하게 여기 일단 기록해두려고 한다.)
논문명: MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
논문 링크: https://arxiv.org/abs/2311.17049
MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
Contrastive pretraining of image-text foundation models, such as CLIP, demonstrated excellent zero-shot performance and improved robustness on a wide range of downstream tasks. However, these models utilize large transformer-based encoders with significant
arxiv.org
3줄 요약
- 강화학습인 줄 알았는데, 그냥 성능 좋은 모델(teacher model)의 지식을 흡수하는 논문
- 이미지 및 텍스트 증강, teacher model embedding 추출, teacher model 유사도 따라잡기 (KL-divergence Loss) 사용
- 참신한 발상보다는 기존 기법을 적절히 활용한 실험/경험을 담아 진짜 모바일에서 (아이폰) 실험한 논문
(개인적으로 강화학습이라고 하니, RLHF처럼 기발한 방법론이 담겼을까 기대했던 것 같다. 아니, 애플인데 기대할 수 있잖아? MobileCLIP 이라는 이름에 강화학습 더해지면 어떻게 참아.... 하지만 Knowledge Distillation 에 가까운 논문이었던 걸로)
초록
- 현재 text-to-image 분야엔 이미 뛰어난 모델들이 많음
- 그런데 상당한 메모리와 latency 가 필요해서 mobile device 에서 사용하기엔 무리가 있다
- 그래서 우리가 multi-modal reinforced training 을 통해서 효율적이면서도 성능도 뛰어난 모델을 만들었다
방법론
(미리 말하자면, 진짜 별 거 없음. 기존 데이터셋에서 텍스트는 captioning model 로 증강하고, 이미지는 augmentation 기법들 써서 증강함. 그리고 teacher model, 즉 기존에 잘하는 모델들을 통해서 임베딩을 미리 저장해둠. 그래야 student model 학습할 때 teacher embedding 만 있으면 teacher model 의 유사도를 알 수 있으니까. 학습할 때 teacher model 의 유사도 행렬도 KL-divergence Loss 를 통해 따라함. 이게 끝임.)
- Knowledge Distillation: 선생님이 두 종류가 계신다. 두 명이 아니라 두 종류다.
- Captioning Model: 이미지에 자막(caption)을 생성하는 모델이다. 기존 이미지에 제공되는 자막이외에도 여러 개 더 생성한다.
- a strong ensemble of pretrained CLIP models: CLIP 계열 모델 중 거대하지만 성능이 뛰어난 모델들을 여러 개 사용한다.
사견
- Captioning Model: 이미지나 비디오에 비해 텍스트 정보는 빈약하다. 특히 Caption 은 특성상 짧고 추상적이다. 예컨대, "한 여성이 말을 타고 있다" 라는 자막이 있다고 치자. 그 여성이 노인일 수도, 초록색 옷을 입었을 수도, 머리가 길수도, 구두를 신었을 수도 있다. 말도 이렇게 세세하게 들어가면 엄청나게 많은 특징을 가지고 있을 것이다. 이미지나 비디오는 다 표현하고 있지만, 텍스트는 자막의 특성상 짧고 간결할 것이다. 그래서 증강하는 것이 유의미한 것 같고, 실제로 captioning model 을 활용한 논문들이 꽤 있다.
- a strong ensemble of pretrained CLIP models: '일단 잘해라. 그러면 누가 경량화해줄 것이다.' 내가 지어낸 말이다. 하지만 딥러닝의 규칙과 같다. 일단 무겁더라도, 돈이 많이 들더라도 뛰어난 성능을 보인다면 그걸 효율적인 구조에 담아내는 건 비교적 쉽다. 그래서 어느 정도 정복된 text-to-image Retrieval 분야를 mobile device 로 옮기려는 시도에 이런 방법은 필수적인 것 같다.
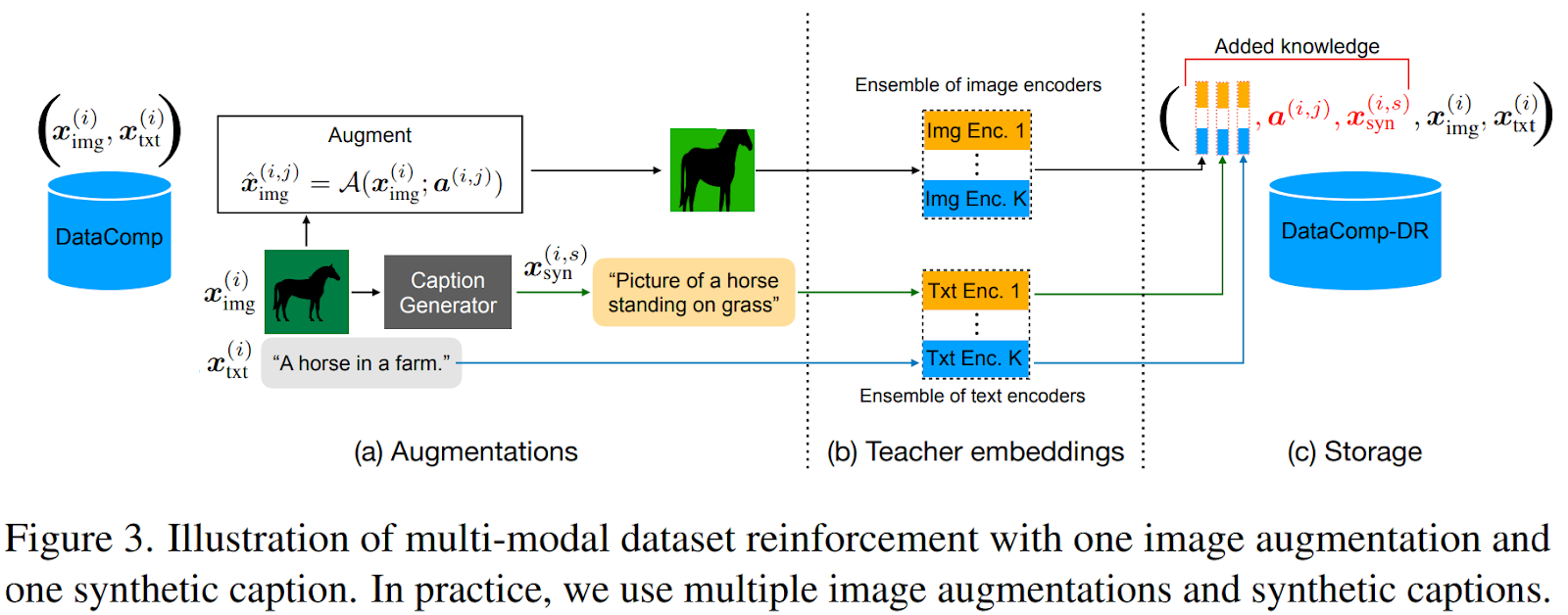
- 위 과정은 크게 3가지로 나눠진다
- 대충 위 과정을 통해서 DataComp 에서 DataComp-DR 로 진화했다 이런 내용이다
- 위 과정은 아래에서 세세하게 나눠보겠다
A) Augmentations
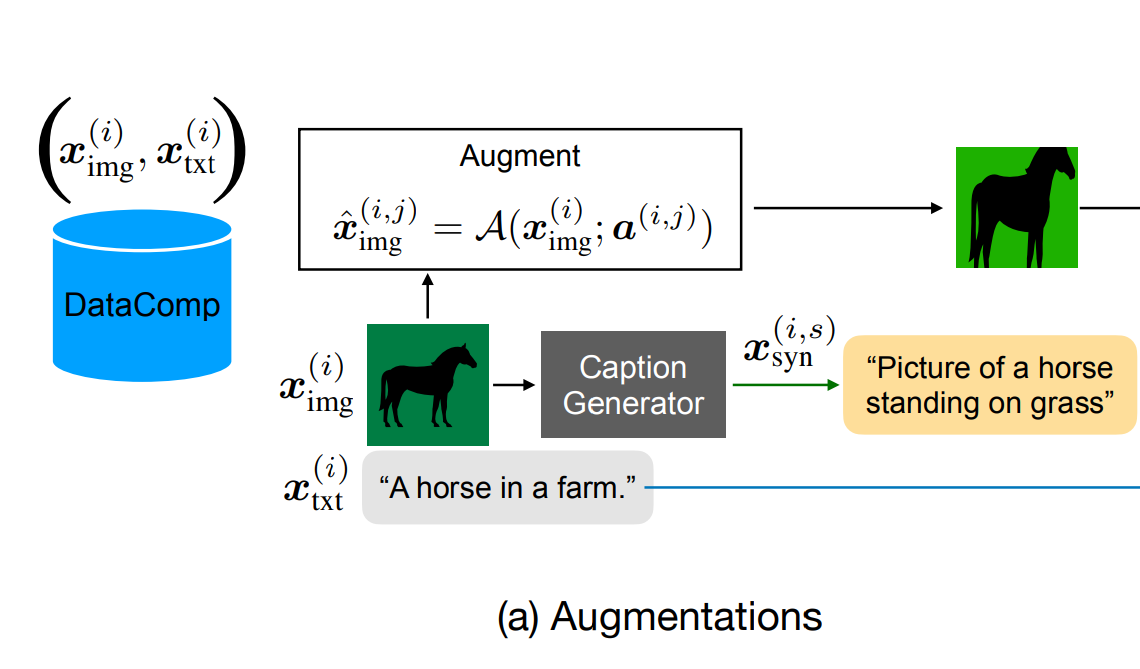
- 자막 증강: CoCa 라는 Captioning Model 을 활용해서 증강한다고 함. 증가개수는 실험쪽에서 다루겠음.
- 이미지 증강: 여러 증강 기법 중 하나를 무작위로 골라서 증강한다고 함. 이것도 실험쪽에서 자세히 말하겠음.
결론: 기존 이미지를 사용해서 Caption 과 증강 이미지를 생성함.
B) Teacher Embeddings

- Teacher Model Embedding 을 미리 계산하여 저장한다
- 목적: 나중에 Student Model 학습할 때, 유사도도 따라할려고 (KL-divergence Loss)
- 여기서 주의할 점은 무엇의 임베딩을 저장했냐는 것이다. 기존 이미지, 기존 자막, 증강 이미지, 증강 자막 이렇게 4가지가 있다. 여기서 기존 이미지를 제외한 3가지 종류(기존 자막, 증강 이미지, 증강 자막) 에 대한 임베딩을 구했다.
- 신기한 점은 기존 이미지에 대한 임베딩을 구하지 않았다는 점? 왜인지 따로 적힌 것은 없었다. 원래 이 분야는 그런건가? 실험 부분을 읽어봐도, 원본(기존) 이미지를 전혀 사용하지 않는다.
C) Storage
- 이제 저장하면 끝이다.
- 증강한 이미지와 자막, 그리고 teacher model embedding 을 기존 데이터셋에 더해 저장한다.
- 여기서 강조하는 것은 "우리는 선생님들을 학습 전에 딱 1번만 모셔도 임베딩을 미리 구해놨으니 효율적이야. 학습할 때마다 선생님 불러서 GPU에 올려드리는 게 뭐하는 짓이야. 당연히 이렇게 1번만 저장해두면 평생 앞으로 선생님들을 부를 필요 없이 모든 학생 모델들이 편하게 학습할 수 있다구!" 이다.
솔직히 이게 Novelty 라고 볼 수 있나...Retrieval 분야에선 pre-calculated 라는 개념은 워낙 당연해서 참신하다고 느끼기 어려웠다....
Training Loss

- 첫번째 식부터 보자.
- CLIP Loss: 우리가 다 아는, Contrastive Loss 다. CLIP에서 쓰는 손실함수인데, 이걸 모르는데 이 논문을 읽고 있었다면 OpenAI 에서 낸 CLIP 을 먼저 읽어보길 강력히 추천한다.
- Distill Loss: Distillation Loss 다. 특수 기호 설명 하나도 안 넣은 이유는 대충 teacher model embedding 불러와서 유사도 구한 다음에 student 도 유사도 따라하라는 의미이기 때문이다.
- Lambda: 실험에서 나오는데, Lambda 를 통해서 teacher 를 얼마나 활용하는지를 조절한다고 보면 된다. 근데 내가 맨 위에 써놨듯이 치명적인 오타가 있다. 그래서 실험 설명 부분에선 내가 생각하기에 어울리는 대로 해석할 것이다.
Efficient Training
: 어떻게 데이터를 불러와서 사용하는지 친절하게 알려준다.
- 불러올 데이터 x번째 정해지면, x번째 원본 자막(텍스트)와 x번째 원본 이미지를 불러온다
- 이미지 증강 기법이 여러 개 있는데 그 중 무작위로 뽑아 결정한다. 결정된 방법에 따라 이미지를 증강하여 증강한 이미지를 만든다. (논문에 대놓고 적혀 있지는 않는데 더 정확히 말하자면, 사실 이미 모든 기법에 대해 증강되어 있다.)
- 증강된 자막 역시 무작위로 하나 고른다 (왜냐면 한 이미지에 대해 여러 개의 자막을 미리 생성해뒀기 때문이다)
- 이를 통해 2개의 데이터 쌍 조합을 만들 수 있다. 하나는 (기존 자막, 증강 이미지) 나머지 하나는 (증강 자막, 증강 이미지) 다.
- 마지막으로 미리 계산해둔 teacher embedding 을 불러온다. K개의 teacher model 이 있으니 여러 개 불러온다고 보면 된다.
이렇게 하면, 기존 데이터셋에 비해 2배 많은 학습량이 발생한다. (물론 Teacher Embedding 은 제외하고 말했을 때)
Architecture
: 여기가 대략 난감하다. RepVGG 와 FastViT 논문의 핵심 아이디어를 이해해야 한다.
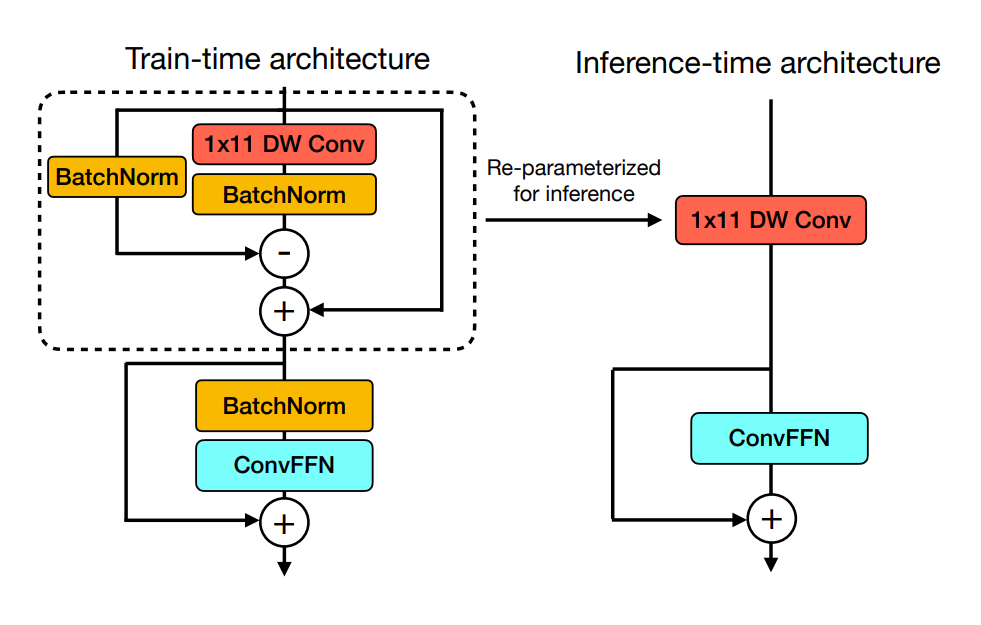
- 대충 설명하자면, 학습할 때는 왼쪽처럼 복잡하게. 추론할 때는 오른쪽처럼 간단하게 할 수 있다는 말. 이걸 어떤 논문에서 멋있는 말로, 'training-inference decoupling' 이라고 표현하더라 ~
- 아무래도 Mobile 이니까 가벼우면서도 효과적인 모델을 텍스트 인코더를 위해 준비했다고 보면 된다.
- 그 핵심 원리는 RepVGG 논문에서 따왔고, FastViT에서 구체화하니 검색해서 핵심이라도 읽어보시길.
Our MobileCLIP architectures are formed as pairs of MCi:MCt architectures.
MCi: MobileCLIP image encoder 의 줄임말인 것 같다
MCt: Mobile CLIP text encoder 의 줄임말인 것 같다
MobileCLIPS0 (MCi0:MCt)
MobileCLIP-S1 (MCi1:Base) - MCi1 is a deeper version of MCi0
MobileCLIP-S2 (MCi2:Base) - MCi2 is a wider version of MCi1
where Base is a 12-layer Transformer similar to the text-encoder of ViT-B/16 based CLIP.
We also train a standard pair of ViT-B/16:Base and refer to our trained model as MobileCLIP-B.

대충 여기까지가 논문에서 실험전까지 아이디어를 이야기한 부분이다. 솔직히 MultiModal Retrieval 논문, 특히 Apple 논문이라 기대가 컸나보다. 참신함은 없고 막대한 실험과 현존하는 최고의 실험 설정을 알려줬다는 쪽에 가깝다. 그래서 연구자에게 큰 도움이 될 것 같지는 않아서 여기서 멈추고자 한다.
특히 Multi-Modal Reinforced Training 이라는 표현을 제목에 넣으면 어떻게 기대를 안해...



