
논문명: CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
논문링크: https://arxiv.org/abs/2104.08860
CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
Video-text retrieval plays an essential role in multi-modal research and has been widely used in many real-world web applications. The CLIP (Contrastive Language-Image Pre-training), an image-language pre-training model, has demonstrated the power of visua
arxiv.org
서론
우선, 제목에서 CLIP 과 Clip 을 이해하면 좋다.
- CLIP: openAI 에서 발표한 논문이다. text 와 image 간의 연관성을 깊게 배운 모델이라고 보면 된다.
- Clip: video 의 일부. 같은 자막이 나올 동안 나오는 길이 정도의 비디오라고 보면 되겠다.
Video Clip Retrieval

- 위 그림처럼 (video clip, caption) 쌍으로 주어질 때,
- 주어진 caption 과 가장 잘 어울리는 video clip 을 찾는 걸 의미함.
What is CLIP?

텍스트와 이미지를 연결하여 학습한 모델
- Text encoder: Transformer
- Image encoder: Vision Transformer(ViT)
- 텍스트와 이미지를 각각 인코딩해서 Cosine Similarity 를 구한다.
- 그림(이미지)과 일치하는 설명(텍스트)은 유사도를 높게 하고, 나머지는 낮도록 contrastive learning 을 진행한다.
여기서 헷갈리면 안 되는 부분은 CLIP 이라는 모델은 image 이고, CLIP4Clip 은 video 라는 점.
Natural Language Supervision
CLIP idea 는 단순하다. 하지만 주목을 받은 이유는 높은 성능을 낸 학습 방식이다. 이 논문에선 'Natural Language Supervision' 이라고 부르기로 했다.

간단히 말해서 인터넷에 널린 이미지와 텍스트 쌍을 방대한 규모로 모아서 학습했다. 이때, 이 방식을 부르는 게 논문마다 달랐다고 한다.
The other papers call this method unsupervised, self-supervised, weakly supervised, and supervised respectively.
그 이유는 따로 라벨링 작업이 없기 때문에 그걸 unsupervised 라고 볼 수도 있는 것이고, 반대로 텍스트의 도움을 받아 image representation 을 학습했으니 weakly supervised 혹은 supervised 라고도 볼 수 있다는 것이다. 위 그림에 나오는 논문 3개 모두 다르게 부르기 때문에, openAI 에서 'Natural Language Supervision' 으로 통일한 셈이다.
어찌됐건 핵심은 따로 데이터셋을 제작하지 않고, 그저 인터넷에서 모아왔는데도 성능이 매우 좋다는 점이다. 그리고 텍스트와 연결된 image representation 을 배울 수 있다고 강조한다.

실제로 Computer Vision 분야에서 유명한 ImageNet 이라는 데이터셋이 있다. openAI 에 따르면, 25000명의 작업자가 1억 4천만개의 annotation 을 22000개의 카테고리별로 작성했다고 한다. 즉 엄청난 비용을 절약하면서도 성능이 탁월했다는 게 이 논문의 핵심이었다.
목적: CLIP 을 video 에서도 써보자

- image 에서도 좋은 성능을 냈으니
- knowledge of CLIP model 을 이전(transfer)하여
- video-language retrieval 에서도 end-to-end manner 로 사용해보자.
본론
구조를 3등분해서 보다

- 1. Text Encoder
- 2. Video Encoder
- 3. Similarity Calculator
1. Text Encoder
(헷갈릴까봐 말하자면, BERT 같은 PLM 이 아니라 Transformer 를 쓴다. 차원도 768 이 아니라 512 라서 확실하다.)

- Transformer 이기 때문에 [CLS] token 이 애초에 없다.
- [EOS] token 을 전체를 대표하는 representation 으로 사용한다.
2. Video Encoder
2-1. Vision Transformer
: Video Encoder 에 쓰이기 때문에 먼저 ViT 부터 봐야 한다.

- 이미지를 patch 단위로 나눈다. 위에선 9개로 나눴다.
- linear projection 에 의해 3차원(channel, width, height) 에서 1차원으로 바뀐다.
- 여기서 맨앞에 [class] embedding 을 넣어준다.
- 그 후, 전체적인 위치 정보를 반영하기 위해 positional embedding 을 추가한다.
- Transformer Encoder 에 넣는다.
2-2. Video Encoder

자, 이제 CLIP4Clip 으로 돌아오면, image 를 video 로 바꾼 것뿐이다. 기존에 image 는 3차원이었다면, video 는 시간 정보(t)가 있으니 4차원인 게 유일한 차이다. 이걸 어떻게 linear projection 으로 1차원으로 바꾸는 지가 핵심이겠다.
2-3. Linear Projection of Flattened Patches Module
Linear Projection of Flatten

- 기존 ViT 처럼 2차원으로 patch 를 자르는 방식
- 시간적 정보가 반영되지 않음

- 3차원 단위의 patch 로 자른다.
- 시간적 정보를 반영할 수 있다.
- 3D convolution with kernel [t × h × w] 을 사용한다.
(자세히 1차원으로 변경하는 방식은 나오지 않는다. 궁금하다면, 코드를 직접 뜯어야 한다.)
3. Similarity Calculator
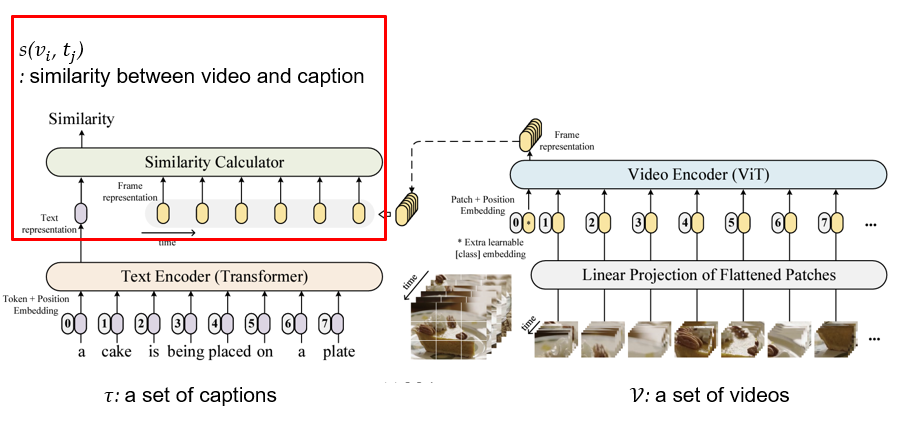
이제 text embedding 과 video embedding 을 통해 유사도만 구하면 된다. 사실 여태껏 과정은 CLIP 과 매우 유사해서 novelty 가 없다고 생각했다. 기존 CLIP 에서 썼던 cosine similarity 와 다르게 3가지 방법을 제시한다.
ㄱ. Parameter-free type

제목처럼 새로운 parameter 가 없다. video embedding 을 mean pooling 한 후, text representation 과 consine similarity 를 그냥 구하면 된다.
ㄴ. Sequencial Type

Video Embedding 의 순서정보를 활용하기 위해 LSTM/Transformer Encoder 를 활용한다. 그 결과물을 가지고 유사도를 구한다.
ㄷ. Tight Type

얼핏 보면 ㄴ과 차이가 없어보이지만, text 와 video 정보가 함께 입력으로 들어간다는 점을 주목해야 한다. 둘을 함께 쓰기 때문에 Tight type 이라고 부르는 듯하다.
Loss Function

- v2t: 하나의 비디오에 대해 여러 개의 자막이 있을 때, 가장 적절한 자막을 찾도록 학습함.
- t2v: 하나의 자막에 대해 여러 개의 비디오가 있을 때, 가장 적절한 비디오를 찾도록 학습함.
Cross Entropy Loss 로 각각 구하고, 합친 게 최종 loss 다.
Post Pre-training
갑자기 사후 사전학습이라는 말이 나온다. 저자가 그냥 이대로 하려니, video 가 가진 시간적인 정보를 CLIP 이 제대로 학습하지 못할까봐 우려한 듯하다. 그래서 Video Dataset 으로 학습을 해준다.
HowTo100M Dataset

- 어떻게 하는지(how to ~)를 알려주는 영상들
- 100M, 즉 1억개나 있다.
- 모두 학습하기엔 방대해서, ‘Food and Entertaining’ category 만 사용한다. 약 38만개쯤 된다.
학습 설정
- MIL-NCE loss
- Similarity Calculator: parameter-free type (encoder 학습이 목적이라서 이렇게 한 듯 하다)
- Optimizer: AdamW
- Learning rate: 1e-8
- token length: 32, frame length: 12, batch size: 48
- GPU: 8 NVIDIA Tesla V100 GPUs
- Time: 2 weeks (5 epoch)
실험 결과
: 실험 결과를 세부적으로 해석하지 않고, 논문처럼 결론만 작성하겠다. dataset 은 5개를 사용했다.
- TrainD: dataset used for pre-training & training
- E2E: End to End manner from raw video
1. MSR-VTT Dataset

- M: MSR-VTT, H: HowTo100M, W: WIT, C: COCO Captions, G: Visual Genome Captions
- 위 실험 결과의 핵심은 train dataset 의 크기가 다르다는 것이다. 다른 이유는 baseline 마다 기준이 달라서 각각 비교하기 위해 둘 다 실험해본 것 같다.
- 두 실험 모두 다른 baselines 에 비해 압도적으로 성능이 높다.
- 이때, train dataset 이 증가(7K → 9K)하니 'mean pooling 방식'에서 transformer 기반 유사도 계산 방식이 최고 성능으로 바뀌었다.
- 이를 통해, similarity calculator 에 새롭게 생긴 parameter 는 학습 데이터가 많을 수록 성능이 오른다는 걸 확인할 수 있다고 저자는 밝힌다.
2. MSVD Dataset
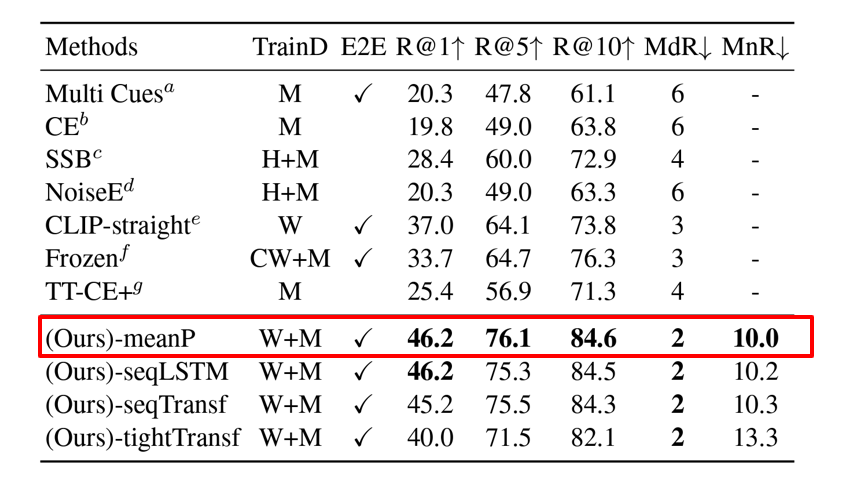
- M: MSVD, H: HowTo100M, W: WIT, CW: CC3M + WebVid-2M
- 1번 dataset 에 비해 절반 정도로 train dataset 의 크기가 작다고 한다.
- 이 점에서 미루어 보아, 역시 train dataset 의 크기가 클수록 sequencial type 이나 tight type 의 새로운 parameter 가 학습을 잘 하게 된다는 걸 알 수 있다.
3. LSMDC Dataset

- L: LSMDC, H: HowTo100M, W: WIT, MD: MSR-VTT,LSMDC,HowTo100M, CW: CC3M + WebVid-2M
- sequencial type 중에선 LSTM 이 더 낫다고 저자가 말한다.
4. ActivityNet Dataset
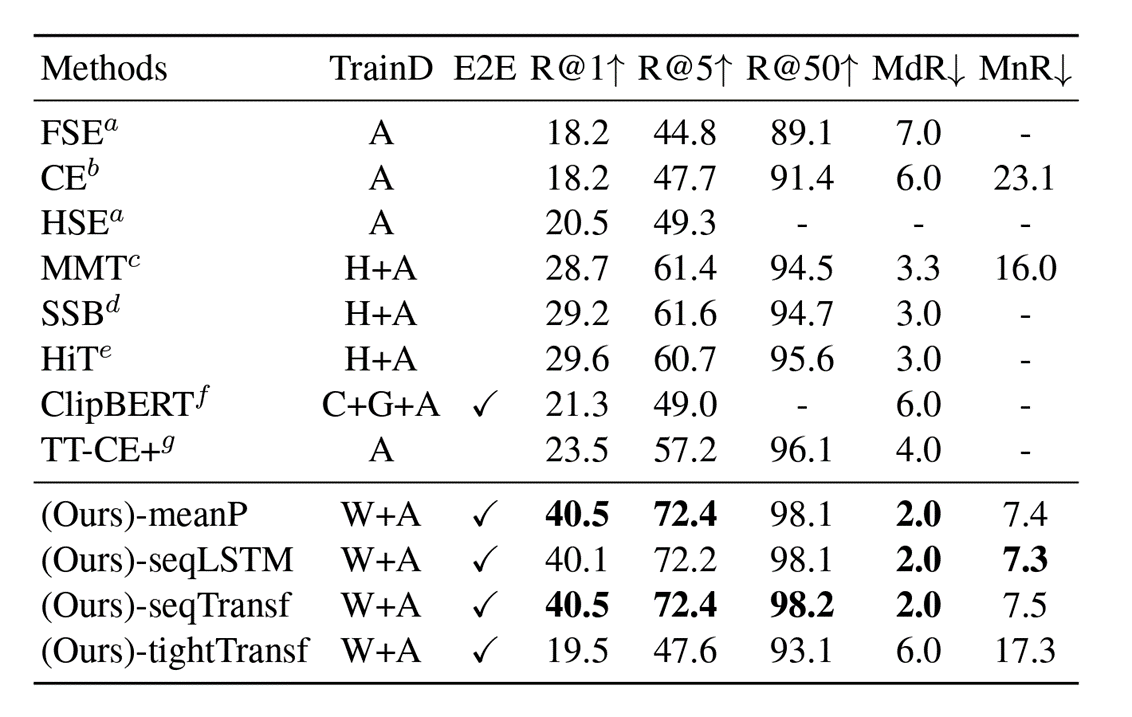
- A: ActivityNet, H: HowTo100M, W: WIT, C: COCO Captions, G: Visual Genome Captions
- 딱히 언급 없음. 하지만 압도적 SOTA.
5. DiDeMo Dataset

- D: DiDeMo, H: HowTo100M, W: WIT, C: COCO Captions
- G: Visual Genome Captions, CW: CC3M + WebVid-2M
- 딱히 언급 없음. 하지만 압도적 SOTA.
실험 결론
- 상당한 차이로 모든 데이터셋에 대해 SOTA 를 달성했다.
- 새롭게 추가한 parameter 들은 train dataset 이 충분히 커야 성능을 낸다.
- tight type 이 대부분 가장 성능이 안 좋았다. 이 점으로 볼 때, 충분한 크기의 데이터셋이 없다면 text 와 video 사이의 cross-modality 를 배우는 건 아직 어렵다고 볼 수 있다.
Hyperparameter 실험


- 다른 건 잘 모르겠고,
- learning rate 가 성능에 치명적이었다는 것 정도만 기억하면 된다.
Post-pretraining 실험

- 'ZeroShot' 과 'ZeroShot + P-PT' 를 비교해보면, 성능이 1 ~ 2 % 정도 오른다.
- 'FineTuning' 과 'FineTuning + P-PT' 를 비교해보면, 성능이 1% 이하로 오른다.
- 즉, zero shot 일 때 더 효과적임을 알 수 있다.
- 또한, 이를 통해 같은 data type 일 때 general knowledge 이 더 잘 전이(transfer)된다.
2D/3D Patch linear 실험

- 3개 중 2개가 2D가 성능이 더 좋다.
- 기존 CLIP 이 2D 에 대해 학습했다보니, 시간 정보를 충분히 학습하기에 어려움이 있었다고 보았다.
의견
- 성능이 baseline 에 비해 엄청나게 올랐다는 점에서 대단한 논문이라고 생각함 (+)
- CLIP 을 video 영역으로 끌여들인 실험 정신 역시 어렵지 않으면서도 좋은 시도라고 느낌 (+)
- 2D/3D patch linear 실험은 데이터셋 3개만 놓고 결론을 내리기엔 아쉽다고 느낌. 본 실험에선 5개 다 썼는데, 왜 여기선 3개밖에 사용하지 않았는지 의문임 (-)
- 실험에 TrainD 라고 해서 실험에 쓰인 학습데이터셋을 적는 란이 있는데, baseline 마다 다 달라서 정밀한 비교는 아니란 생각이 들었음 (-)



