논문명: EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa

https://arxiv.org/abs/2108.12009
EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa
We present EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa, a simple yet expressive scheme of solving the ERC (emotion recognition in conversation) task. By simply prepending speaker names to utterances and inserting separation tok
arxiv.org
(이 글도 한국사람이 저자다. 대화 속 감정 인식은 한국인들이 관심이 많은 분야인 것인가?!)
요약
- 발화 앞에 사람 이름을 넣고 [SEP] token 을 넣어주는 것만으로도
- 대화자간, 그리고 대화자 자체의 상태를 배울 수 있다.
- 이것만으로도 성능이 오른다.
문자뿐인 대화에서 감정을 읽다
인간도 감정 파악이 어렵다
인간은 대화를 할 때, 표정, 목소리, 몸짓 등 다양한 측면에서 정보를 받을 수 있다. 하지만 현대사회에서 주로 문자를 주고 받는데, 이때 알 수 있는 것은 오로지 글자와 맥락뿐이다. 실제로 인간조차도 문자를 통해 여전히 많은 오해를 낳고, 이로 인해 관계가 멀어지기도 한다.
이걸 모델에게 시키는 분야가 바로 'ERC' 다. 'Emotion Recognition in Conversation', 즉 대화 속에서 감정을 인식하라는 말이다. 과연 사람도 어렵다고 느끼는 걸 인간이 할 수 있을까?
기계는 최대한 정보를 끌어내려고 한다
기계가 하고자 하는 것은 대화 속에서 알 수 있는 다양한 정보들이다. 가장 쉬운 것은 그동안 나눴던 대화를 통해 문맥을 이해하는 것이다. 또, 발화자마다 성격이 다르니 그걸 포착해야 하기도 한다. 혹은 발화를 통해 발화자간의 관계를 파악하는 게 도움이 될 수 있다. 'Sentimental Analysis' 처럼 단순히 입력만 받아서 알아낼 일이 아니라, 모델이 여러 정보를 끌어야 내야 한다는 것이다.
방법론: EmoBERTa
기존의 방법들은 RNN 에서 겨우 벗어났다.
ERC 분야의 여태껏 접근 방법으로 RNN(GRU) 와 같은 모델을 활용한 시도가 많았다고 한다. 하지만 BERT 같은 모델들은 훨씬 효율적이고 성능도 좋다. 그래서 최근에 HiTrans 나 DialogXL 같은 모델을 등장했다.
HiTrans
- 여러 개의 발화들 앞에 [CLS] tokens 을 붙여서 하나의 입력으로 받는다.
- BERT 모델을 통과한 후, 다른 Transformer 모델의 입력으로 들어간다고 한다.
DialogXL
- XLNet 을 기반으로 했음.
기본 설정
- Natural Language Pretrained Model 중 'RoBERTa-Large' 를 사용했다.
- 참고로 RoBERTa 는 특이하게 BERT 와 쓰임새는 같으나, 생김새가 다른 special token 을 사용한다. 예컨대, '[CLS] token' 은 '<s>', '[EOS] token' 은 '</s> token' 이다.
→ 즉 모델에서 어떠한 수정도 없었고, 입력하는 방식에 변화를 줬다고 보면 된다.
입력: 과거, 현재, 그리고 미래
- 입력은 3문장으로 한다. (보통 사전학습모델은 두 문장까지는 입력받아도, 세 문장은 흔하지 않다. 특이하게 설정했다.)
- 이때 문장 사이의 구분은 '과거 문장 <s> 현재 문장 </s> 미래 문장' 과 같은 형식으로 넣는다. (시작과 끝으로 쓰이는 토큰을 구분하는 토큰으로 사용했다.)
아래 그림에서 2가지 점을 명백히 드러낸다.
그런데 다른 건 다 이해가 되는데, 'i = i + 1' 과 while 반복문이 있는 걸 보니, 최대 길이가 허락하는 한 해당 문맥 전체를 다 넣는 것 같다. 가령, 4번째 발화인데 3번째 발화와 5번째 발화를 넣고도 자리가 남으면 2번째, 6번째 발화도 추가하겠다는 걸로 보인다.
훈련 설정
- 다른 건 볼 필요가 없으나, optuna 를 사용했다는 점은 눈여겨볼 필요가 있다. 사실, ERC 분야는 Learning rate 가 다른 자연어 처리 분야에 비해 다른 것 같다고 느꼈다. 물론 내 짧은 경험이 일으킨 소견일 수 있으나, 보통 '1e-5' 를 썼다면 여기선 '1e-6' 을 써줘야 하는 느낌이었다.
데이터셋
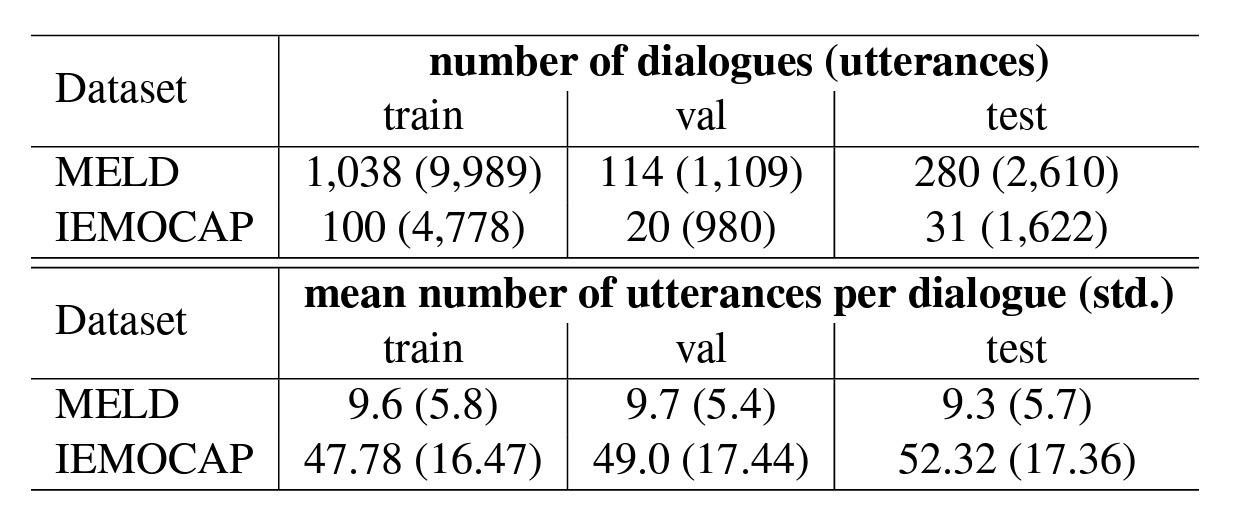
MELD
- multi-modal (visual, audio and text) → 여기선 글자만 사용했다.
- 2명 초과의 대화
- 7가지 감정: neutral, joy, surprise, anger, sadness, disgust, and fear
IEMOCAP
- multi-modal (visual, audio and text) → 여기선 글자만 사용했다.
- 2명간의 대화 (dyadic)
- 11개로 나눠졌으나, 6개의 감정만 사용: neutral, frustration, sadness, anger, excited, and happiness
2개의 데이터셋 모두 발화자가 없어서 임의로 배우 이름을 넣어서 발화자의 이름을 붙였다고 한다.
실험 결과
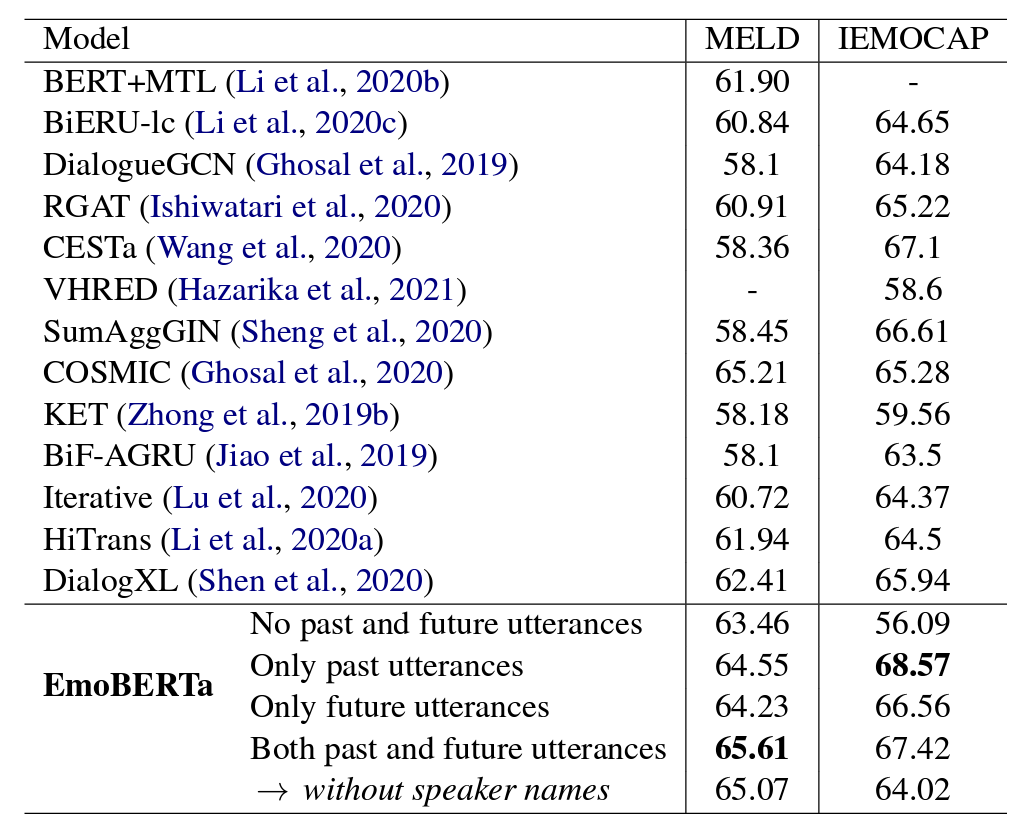
- 별다른 모델 수정 없이 두 데이터셋에서 SOTA 를 달성함.
- 이름을 빼면, 성능이 하락하는 걸 볼 수 있음. 즉, 발화자의 이름이 정보를 인코딩하는데 도움을 준다는 걸 알 수 있음.
- IEMOCAP 에선 미래의 화자를 빼는 것이 더 성능이 높았음. 저자는 추측컨대, 발화의 양이 상당해서 이럴 때는 과거의 발화만 잘 넣어주는 것이 더욱 좋은 것 같다고 함.
- 과거, 미래 발화를 넣지 않을 때와 SOTA 성능을 비교해보면, IEMOCAP 에서 상당한 성능 향상을 볼 수 있음. 이에 대해서 저자는 IEMOCAP 의 대화 길이가 상당하기 때문에, 문맥이 많은 도움이 된다고 추측함.
정성 분석
test dataset 에서 맞춘 데이터 10개, 틀린 데이터 10개를 무작위로 추출했다. 그리고 <s> 토큰의 attention 을 분석했다. MELD, IEMOCAP 2개의 데이터셋이니 총 40개를 human evaluation 했다.
- 녹색: 첫번째 레이어에서 <s> 토큰이 attention 을 두고 있는 상위 토큰 10개를 표시한 것
- 노란색: 마지막 레이어에서 <s> 토큰이 attention 을 두고 있는 상위 토큰 10개를 표시한 것
아래는 맞춘 예시다. 마지막 레이어에서 current utterance 의 발화자를 잘 가르키고 있는 걸 볼 수 있다. 맞춘 예시 20개 모두 이런 모습을 보였다고 한다. 논문에선 100% 라고 표현했다.

한편, 아래는 틀린 예시다. 마지막(노란색)엔 엉뚱한 토큰들에 attention 을 두고 있는 모습을 볼 수 있다. 틀린 예시에선 60%만이 현재 발화의 당사자를 가르키고 있다고 말한다.

즉, 발화자를 마지막 레이어에서 <s> token 이 가르키는 것이 중요하다고 저자는 지적한다.
의견
1. 미래의 발화를 넣는 것은 정당한가?
: 정확도를 높이는 수단으로는 당연히 이해한다. 하지만 논문은 정확도뿐만 아니라 실제 기술적으로 활용가능성이 있어야 한다. 그런 점에서 미래의 발화는 당연히 배제하는 게 맞지 않을까? 괜히 Transformer Decoder 가 attention 을 masking 하겠는가?
2. 최대길이가 허락한다고 발화를 최대한 넣는다면, 그게 무슨 의미가 있는 것인가?
: 알고리즘에 의하면, 앞뒤 문맥을 길이가 허락하는 한 최대한 넣는다. 사실 납득이 되지 않았다. 성능이 높은 것은 이해하나, 이것이 어떻게 도움이 되었는가에 대해선 잘 모르겠다.
3. 정성 분석이 타당한가?
: 인간이 직접 평가하는 것이 매우 힘든 일이라는 건 생성 논문을 한편이라도 본 사람이라면 다 아는 일이다. 그래서 40개의 데이터를 분석하는 것도 엄청 고된 일이었을 것 같다. 하지만, 그 분석이 타당한가에 대한 이야기는 별개다.
- A: 맞은 데이터 20개 중 20개는 발화자 토큰에 attention 을 두고 있었다.
- B: 틀린 데이터 20개 중 8개(40%) 는 발화자 토큰에 attention 을 두지 않았다.
- C: 그러므로, 발화자 토큰에는 정보가 많다.
이런 분석이 타당한가? 타당한지 떠올리기 어려울 것 같아서 예시를 준비했다.
- A: 물고기 1000마리 모두 헤엄을 잘 친다.
- B: 인간 1000명 중 400명은 헤엄을 못 친다.
- C: 그러므로, 헤엄 능력은 물고기와 인간을 판단하는데 도움을 준다.
나는 이 예시의 분석이 타당하다고 본다. 실제로 헤엄을 못 치면, 바로 인간이라고 단정지을 수 있기 때문이다. 단, A 가 100 % 신뢰도를 가져야 이 분석이 타당해진다. 우리는 물고기가 1000마리 정도가 아니라 모든 물고기가 헤엄을 잘 친다는 걸 확실히 알고 있다. 우리가 한국인에게 한국말을 잘할지 못할지 고민조차 안하듯 말이다.
고로, 위 분석이 맞으려면 맞은 데이터 20개가 전체 데이터에서도 동일한 특성을 가지면 된다. 그때, 분석 C 는 타당해진다. 좀 더 구체적으로 말하자면, 전제 A 의 신뢰도가 높을수록 C 의 타당성이 올라간다. 이는 B 도 동일하다.
그렇다면, 총 40개가 집단을 대표할 수 있을까? 테스트 데이터셋 2개의 개수를 모두 합치면 4232개다. 이게 집단을 대표할 수 있는가에 대한 신뢰도가 곧 이 분석의 신뢰도를 결정한다. 나는 확률을 잘 모르지만, 적어도 이 분석이 그렇게 와닿지 않았다고는 말해볼 수 있을 것 같다.



