3줄 요약
- 정의: 텍스트 생성 task 성능 평가 지표
- 의미: 영어로 '복잡한 정도', '당황스러운 정도'를 의미함
- 값을 읽는 법: 즉, 낮을수록 모델의 성능이 좋다고 볼 수 있음

무슨 뜻인가?
perplex: '당황스러운'이라는 뜻임. 즉, 'perplexity'를 붙이면 '당황스러운 정도'라고 이해할 수 있음. 이 사실로 볼 때, 적어도 높을수록 좋은 지표는 아니라는 걸 유추할 수 있음. NLP에서 '당황스럽다'의 의미는 뒤에서 설명하겠음.
어디에 쓰이는가?
생성에 쓰인다. Natural Language Generation 과 관련된 Task 는 다 가능함. 즉, 자연어처리 생성 분야에서 사용하는 지표임.
어떻게 계산하는가?

언어모델이 생성하는 과정은 위 그림처럼 다양한 경우의 수와 확률을 토대로 추측한다. 선택지가 많아서 우왕좌왕할수록 언어모델은 '당황스러울 것이다'. 즉, 선택지가 많아서 어쩔 줄 몰라하는 모델은 perplexity 가 높다고 본다.
여기서 엄밀히 말할 부분이 있는데, 바로 언어 모델의 선택지는 개수가 모두 동일하다는 점이다. 당연히 그렇다. Vocab space 를 미리 정하고, 각 확률을 연산하는 게 언어 모델 아닌가. (이 부분이 이해가 안된다면, 자연어 처리 모델이 어떻게 생성하는지를 다시 공부해야 하는 게 맞다.)

그래도 예시를 들어주자면, 가위바위보를 떠올려보라. 우리가 가위바위보를 하는 모델을 만들 때, '가위', '바위', '보' 이외의 경우를 고려하는가? 아니면 반대로 저 3개 중 몇 개를 배제하기도 하는가? 아니다. '가위를 낼 확률', '바위를 낼 확률', '보를 낼 확률'만 모델이 구할 것이다.
즉, 경우의 수는 사실 정해져 있고 각 경우마다 확률은 구하는 게 일반적인 자연어 모델이 하는 일이다. 그래서 모델이 '당황'하는 경우는 확률이 정답이외의 단어로 골고루 퍼져 있는 경우를 말한다고 볼 수 있겠다.
공식과 계산 방법은 어떻게 되는가?
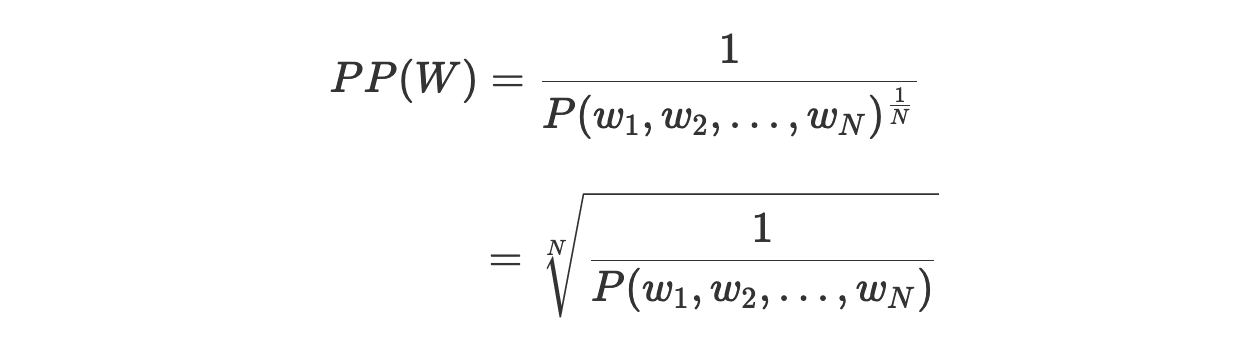
공식을 해석해보겠다.
W 와 ω 의 의미
W: 만들고 싶은 sequence, 즉 정답(reference)를 의미한다. 예컨대, '나는 너를 좋아해.' 같은 문장 말이다.
ω: W 를 토큰로 나눈 후, 각 토큰을 의미함.
P의 의미
여기선 P란 '해당 모델이 정답 토큰을 생성할 확률'을 의미한다.
공식의 의미
공식은 우선 P 를 다 곱한다. 전체적으로 정답을 구할 확률을 구해본 것이다. 그런 후, 역수를 취한다. 즉, 정답에 가깝지 않을수록 해당 값은 커진다.
한편, 1 / N 이 지수로 존재한다. 확률은 N번 곱했으니, N 으로 나눈 것이다. 확률의 역수는 반드시 1보다 크거나 같으므로, 지수에 의해 그 값은 감소한다. perplexity 를 정규화하는 시도로 볼 수 있다.
결론
- perplexity 가 높다 ⇄ 모델이 정답을 구할 확률이 낮다
perplexity 는 좋은 평가지표인가?
Test Dataset 의 신뢰도가 높아야 한다.
위 결론은 'perplexity 가 높다 ⇄ 모델이 정답을 구할 확률이 낮다' 이거였다. 그렇다면, perplexity 에선 정답이 정답다운지가 핵심이다. 예를 들어서, 'I like you.' 를 한글로 번역했다고 치자. 근데 정답이 '마, 내가 니 생각만 하믄 미치고 환장하겠다.' 였다면, 어떤 모델도 낮은 perplexity 를 받기 힘들다.
그래서 Test Dataset 이 어느 정도 신뢰할 만할 때, 사용하는 게 좋다. 또한, 이 지표이외에 여러 지표들을 함께 검토하는 것이 현명하다.
범위가 넓고, 흔히 아는 Percentage 가 아니다.
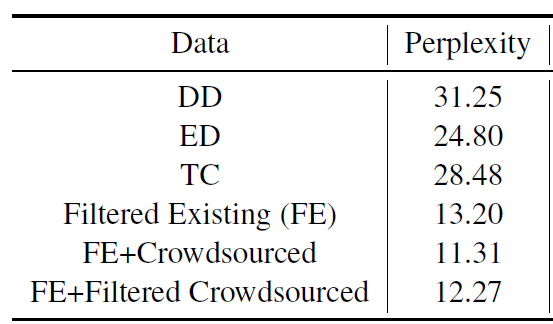
위 자료는 실제 논문에서 발췌한 실험 결과의 일부다. 저 값들을 보고, 선뜻 이해가 되는가? 된다면, 미안하다. 나는 안 되더라. 나는 DD 가 가장 복잡하구나 정도는 이해해도, 상대적으로 얼마나 복잡한지 이해하기 어려웠다. 난 그 이유가 우리가 흔히 쓰던 percentage 가 아니기 때문이라고 느꼈다.
내가 사고실험을 해볼테니, 들어주라. 예시를 들어보겠다.
- A: 모든 토큰에 대해 정답을 구할 확률이 0.5 인 모델
- B: 모든 토큰에 대해 정답을 구할 확률이 0.1 인 모델
- C: 모든 토큰에 대해 정답을 구할 확률이 0.01 인 모델
- D: 모든 토큰에 대해 정답을 구할 확률이 0.001 인 모델
대충 느끼기엔 'A 가 B 보다 5배 잘 하네' 등 상대적인 비교가 쉽다. 왜냐하면 우리는 percentage 에 익숙하니까.
한편, perplexity 로 보면 이렇다.
- A's perplexity: 2 (1 / 2의 역수)
- B's perplexity: 10 (1 / 10의 역수)
- C's perplexity: 100 (1 / 100 의 역수)
- D's perplexity: 1000 (1 / 1000 의 역수)
물론 직접 서로 비교해보면, 위와 크게 다를 바가 없다. 하지만 단순히 역수라는 이유로 눈에 잘 들어오진 않는다. 그래서 perplexity 를 좀 더 익숙하게 보려면, 역수라는 사실을 인지하는 게 중요한 것 같다.
세상엔 단 하나로 좋다고 평가할 수 있는 지표는 없다
미술이나 음악 분야에 절대적으로 모두에게 사랑받는 작품이 있는가? 없다. 생성이라는 분야는 애초에 객관적이지 못하다. 'I like you.' 를 가장 잘 번역한 게 무엇일까?
- 나는 너를 좋아한다.
- 난 널 좋아해.
- 난 네가 좋아.
- 좋아해, 너를.
상황에 따라 다르고, 사람에 따라 다르다. 애초에 하나로 결정짓는 게 말이 안 된다는 것이다. 그러니, 사람을 볼 때도 다양한 방면에서 바라봐야 하듯 metric 도 다양하게 종합적으로 바라보는 시선이 필요하다.
참고 자료
https://heytech.tistory.com/344
[NLP] 언어모델의 평가지표 'Perplexity' 개념 및 계산방법
📚 목차 1. Perplexity 개념 2. Perplexity 값의 의미 3. Perplexity 계산방법 1. Perplexity 개념 1.1. 개요 Perplexity(PPL)는 텍스트 생성(Text Generation) 언어 모델의 성능 평가지표 중 하나입니다. Perple..
heytech.tistory.com
Foundations of NLP Explained Visually: Beam Search, How it Works
A Gentle Guide to how Beam Search enhances predictions, in Plain English
towardsdatascience.com
https://arxiv.org/abs/2109.06427
Commonsense-Focused Dialogues for Response Generation: An Empirical Study
Smooth and effective communication requires the ability to perform latent or explicit commonsense inference. Prior commonsense reasoning benchmarks (such as SocialIQA and CommonsenseQA) mainly focus on the discriminative task of choosing the right answer f
arxiv.org
'NLP > 용어정리' 카테고리의 다른 글
| [용어 정리] oracle summary (0) | 2022.12.14 |
|---|---|
| [용어정리] METEOR Score (0) | 2022.11.01 |
| [용어정리] BLEU Score (1) | 2022.10.04 |
| [용어정리] agnostic (0) | 2022.09.14 |
| [용어 정리] Ablation Study (0) | 2022.06.27 |



