3줄 요약
- NVIDIA 와 Baidu 에서 부동소수점의 이점을 이용하여
- 딥러닝 연산량을 줄여서
- 속도를 높이는 기법

(참고로 여기서 'precision' 은 평가 기준 '정확도'를 의미하는 단어가 아닙니다.
저는 처음에 착각해서 혹시나 저처럼 착각하시는 분들이 계실까봐 작성합니다.)
사용법
pytorch docs: https://pytorch.org/docs/stable/amp.html#
- pytorch 에선 AMP: Automatic Mixed Precision 으로 불리고 있다.
Automatic Mixed Precision package - torch.amp — PyTorch 1.12 documentation
The following lists describe the behavior of eligible ops in autocast-enabled regions. These ops always go through autocasting whether they are invoked as part of a torch.nn.Module, as a function, or as a torch.Tensor method. If functions are exposed in mu
pytorch.org
설명
배경
- 점차 많은 분야에서 Deep Neural Networks (DNNs) 을 사용하고 있음.
- 이에 따라 점차 복잡해지면서 시간, 비용 등이 많이 요구되었음.
목표
- 위 문제를 계산 방식(lower-precision arithmetic)으로 해결해보자 함.
Mixed-precision training 제시
- 현재는 single precision point format [FP32] 로 많이 계산함.
- 하지만 모든 과정에서 그럴 필요가 없다는 걸 확인함.
- 그래서 적절히 Half-precision floating point format [FP16] 을 섞어서(mixed)
- 최대한 동일한 결과를 내면서도, 시간과 비용을 절약해보자.
이점
- 메모리 사용량 절약
- training, inference 시간 단축
→ 우선 부동소수점에 대해 간단히 짚어봐야 한다. 잘 모른다면, 검색해서 공부하자.
부동소수점: single precision point format [FP32] vs Half-precision floating point format [FP16]
- 컴퓨터는 소수를 정확하게 표현할 수 없음.
- 그래서 IEEE 에서 정한 기준을 주로 따르고 있음.
- [FP16]: 메모리는 적게 사용하지만(16bit), 수를 다소 정확히 표현하지 못한다.
- [FP32]: 메모리는 많이 사용하는 대신(32bit), 수를 보다 정확히 표현할 수 있다.
→ 정말로 [FP16]을 쓰면 부정확할까? 그걸 아래 그림에서 보여준다.
- FP32: 정상적으로 loss 가 감소하는 것을 볼 수 있다.
- FP16 == Mixed Precision, loss scale 1: scale 값이 '1' 이라는 건 곧 FP16 과 동일한 뜻이다. 즉, FP16 을 사용하면 loss 가 오히려 증가하는 것으로 미루어 볼 때, 부정확한 결과를 초래할 수 있음을 보여준다.
- Mixed Precision, loss scale 128: scale 값이 '128' 일 땐, FP32 와 같이 정상적으로 작동하는 것을 볼 수 있다.
→ 그렇다면, 대체 loss scale 은 무엇일까? 바로 설명하기 전, 등장 배경부터 이야기해보겠다.
Loss Scale
DNNs 훈련시, 크게 4가지 종류의 tensor 가 있다.
- 1. activations, 2. weights, 3. weight gradients: 대부분 값이 FP16으로 표현가능하다.
- 4. activation gradients: 상당수가 FP16 으론 표현이 되질 않아, 0이 된다.
- 아래 그림에서 activation gradients 의 66.8%가 표현 범위를 벗어나 0 으로 표기되었다.
- 핵심은 대부분의 activation gradients 가 FP16 표현 범위를 벗어났다는 것이다.
- 이를 해결하기 위해, scale factor S 를 곱해 'shift' 하여 FP16 표현 범위로 옮기려고 한다.
- 위 그림 같은 경우엔, 8만 곱해줘도 충분하다.
- 이 과정을 단순히 하는 가장 확실한 방법은 loss 에 scale factor S 를 곱하는 것이다.
- loss 에 곱하면, 단 한번의 연산으로 위 문제를 해결할 수 있다. 그래서 loss scaling 이라고 부른다.
→ 그런데, weight gradients 값이 작아져서 학습이 안 될 수 있는 거 아니야?
FP32 Master Copy of weights
문제점
- weights 는 역전파로 계산된 weight gradients 를 통해 udpate 된다.
- 그런데, learning rate 와 곱하면서 그 값은 보통 작아지게 된다.
- FP16으로 진행한다면, gradients 값이 0이 되어 update 가 되지 않을 수 있음을 의미한다.
해결책
- FP16 으로 weights 를 복사해서, forward 및 backward 를 진행한다.
- 위 과정을 통해서 FP16의 이점인 메모리 절약 및 시간 단축을 한다.
- 그 후, udpate 할 때만 weight gradients 를 FP32로 변경하여 원본 FP32 weights 를 update 한다.
학습 과정
1. Make an FP16 copy of the weights
- 번역: 현재 FP32 weights 를 FP16 weights 로 복사한다.
- 목적: FP16 weights 를 통해 연산량을 줄이기 위해서다.
2. Forward propagate using FP16 weights and activations
- 번역: forwarding 을 할 때, FP16 weights 로 진행한다.
- 목적: FP16 weights 를 통해 연산량을 줄이기 위해서다.
3. Multiply the resulting loss by the scale factor S
- 번역: 결과로 나타난 loss 에 scaling factor S 를 곱한다.
- 목적: FP16 의 표현 범위를 벗어난 값들을 표현하기 위해서다.
4. Backward propagate using FP16 weights, activations, and their gradients
- 번역: Backward 할 때, FP16 을 사용한다.
- 목적: FP16 weights 를 통해 연산량을 줄이기 위해서다.
5. Multiply the weight gradients by 1/S
- 번역: 3번에서 곱했던 S 의 역수를 곱한다.
- 목적: 3번에서 scaling 했던 loss 값을 되돌리기 위해서다.
6. Optionally process the weight gradients (gradient clipping, weight decay, etc).
- 해석: 부가적으로 weight gradients 에 gradient clipping, weight decay 등 처리를 해준다.
- (이 부분에 대해선 자세하게 알지 못합니다. 큰 그림만 함께 공부해가요.)
7. Update the master copy of weights in FP32
- 해석: FP32 weights 에 weight gradients 를 더해 udpate 한다.
- 목적: 위 목차 'FP32 Master Copy of weights' 에서 설명했으니 넘어가겠다.
결과
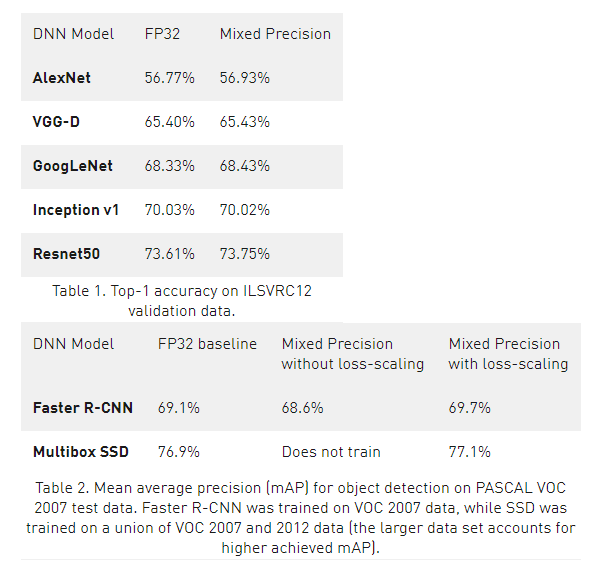
- 성능이 유지되거나 오히려 오른 경우도 꽤 있다.
- 잘 쓰면, 두 마리 토끼를 다 잡을 수 있는 것 같다.
의견
- 이 글은 가볍게 알아보고자 작성되었음을 알립니다.
- 나무보다는 숲을 보자는 마음으로 원리를 가볍게 짚고자 합니다.
- 어차피 연구자가 아니라면, 어떻게 활용하느냐가 훨씬 중요할테니까요.
- 긴 글 읽어주셔서 감사드리고, 어떤 의견이든 환영합니다.
참고
논문 링크: https://arxiv.org/pdf/1710.03740
NIVDIA blog: https://developer.nvidia.com/blog/mixed-precision-training-deep-neural-networks/
Mixed-Precision Training of Deep Neural Networks | NVIDIA Technical Blog
Deep Neural Networks (DNNs) have lead to breakthroughs in a number of areas, including image processing and understanding, language modeling, language translation, speech processing, game playing…
developer.nvidia.com
NVIDIA docs: https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
Train With Mixed Precision :: NVIDIA Deep Learning Performance Documentation
About this task Tensor Core math is turned on by default in FP16. The following procedure is typical of Microsoft Cognitive Toolkit using FP16 in a multi-layer perceptron MNIST example. import cntk as C import numpy as np input_dim = 784 num_output_classes
docs.nvidia.com
'NLP > PyTorch' 카테고리의 다른 글
| [PyTorch] torch.max returns also indices (0) | 2022.08.05 |
|---|---|
| [PyTorch] Is scheduler always good? (0) | 2022.08.03 |

