논문명: Lost in the Middle: How Language Models Use Long Contexts
논문 링크: https://arxiv.org/abs/2307.03172
Lost in the Middle: How Language Models Use Long Contexts
While recent language models have the ability to take long contexts as input, relatively little is known about how well they use longer context. We analyze the performance of language models on two tasks that require identifying relevant information in the
arxiv.org
정밀하게 파헤치지는 않으나, 흐름을 따라서 추후 해결책 논문들도 아래 링크로 달아둘 예정입니다.
요약
- LLM의 발달로 RAG가 등장함. RAG는 질문에 답하기 위해 관련 문서 K개를 함께 입력해주는 기술을 의미함.
- K = 10이면 10개의 문서인데, 이때 정답과 관련이 깊은 문서가 가운데 있을수록 성능이 저하한다고 함.
- 반대로 관련 깊은 문서가 입력의 초반 혹은 후반에 위치할수록 성능이 높다고 함.
- 그래서 Lost in the middle, 즉 가운데에서 길을 잃는다고 표현하였음.
비유하자면,
- 내가 책 10권을 학생한테 주면서 이 안에서 답을 찾아보라고 함.
- 학생은 제일 위나 아래 책만 살짝 펼쳐봄. 중간에 쌓인 책은 열어보지도 않음.
- 이런 학생의 태도를 거대언어모델(LLM)이 똑같이 한다고 함.

- 20개의 문서를 제공했을 때, 정답 관련 문서가 중앙으로 올수록 성능이 저하하는 모습을 보인다
- 심지어 문서를 제공하지 않을 때보다 성능이 하락할 정도다
데이터셋: 좋아, 어떻게 평가할거야?
: 당연히 평가하려면 모델에게 여러 개를 주고 맞춰보라고 해야 한다. 그래서 2가지를 준비했다.
Multi-Document QA

- "누가 노벨물리상을 처음으로 수상했을까요?"가 질문이다
- 정답 문서는 2번째에 두었다
- 정답 문서의 위치를 번갈아가며 실험한다
- 이렇게 여러 문서를 제공하고 질문에 대한 답변을 생성하는 작업을 Multi-Document QA라고 한다
1개: 정답 문서, K - 1개: 방해 문서
- NaturalQA 데이터셋은 질문과 정답이 있는데, 정답이 나온 위키피디아 문서가 있다고 한다. 그걸 정답 문서로 쓴다.
- 방해 문서는 MSMARCO에서 검색기를 통해 질문과 관련이 깊지만 정답을 포함하지 않은 문서를 뽑아서 사용했다고 한다.
key-value retrieval task

- 파이썬으로 치면 Dictionary 처럼 Key-Value 구조의 데이터를 제공한다. 위에선 JSON을 제공했다.
- 이때, 진하게 칠해진 key 값에 해당되는 value 를 묻는다.
- Key-Value 검색(Retrieval)이 맞는 것 같다.
- 그런데 이 태스크는 도대체 왜 할까? 그 이유를 추론했다면 당신은 천재다. 나는 물론 감자였다.
- 그 이유는 Retrieval 능력만 평가하고 싶기 때문이다. 사실 Multi-Document QA는 정답 문서를 찾는 능력(Retrieval 능력)뿐만 아니라 응용하여 생성할 줄도 알아야 한다. 언어모델이 가운데 문서를 정말로 못 찾는지 확인하려면, 문서 검색 능력만 평가해야 한다는 것. 그래서 이렇게 이상해보이는 데이터셋도 준비한 것이다.
- 최대한 자연어를 제거한 이유도 생성 능력의 관여를 최소화하고 싶기 때문이라고 한다. 오로지 검색능력만!!
모델: 그러면 누가 평가당할래?
: 우선 디코딩 방식은 greedy method 로 고정했다고 한다. 이에 대해선 추후 연구로 남겨둔다고 밝힌다.
Open Model
- MPT-30BInstruct (8192 tokens)
- LongChat-13B (16K)
Close Model
- GPT-3.5-Turbo (4K)
- GPT-3.5-Turbo (16K)
- Claude-1.3 (8K)
- Claude-1.3 (100K)
그 이외에도 정밀한 분석을 위해 2가지 setting 을 준비했다.
Closed-book setting
- 문서 하나도 안 주고 기존에 모델이 가진 지식으로 성능을 측정하는 것
Oracle setting
- 정답 문서만 정확하게 1개 제공하는 상황
- 방해 문서를 단 하나도 제공하지 않았다는 점에 유의하자

- 확실히 정답을 제공하는 순간, 성능이 크게 향상되는 것을 볼 수 있다
- 일단 거대언어모델들은 주어진 단서를 활용할 줄 아는 것으로 보인다
실험
1. 정답 문서가 처음에 있거나 끝에 있을 때 성능이 제일 좋다

- 그림이 오른쪽으로 갈수록 제공하는 문서의 개수가 10개씩 늘어난다
- 하지만 일관되게 가운데에서 성능이 움푹 패이는 걸 확인할 수 있다
- 이유는 모르겠으나, 길이에 관계 없이 가운데는 잘 읽지 않나보다? 수업시간에 처음과 끝에만 생생한 친구들처럼 말이다.
2. 긴 입력에 강화된 모델이 기존 모델보다 더 잘 하는 건 아니네?
- 그냥 모델과 그걸 긴 입력에 강화한 모델들이 쌍으로 있다.
- 위 그래프에서 보면 성능 차이가 거의 없다는 것을 볼 수 있다.
- 긴 입력이 가능하다고 했지, 성능이 더 좋다고 한 적은 없다.
3. 잠깐만, 그러면 검색 능력만 평가해보자. 너 어느 정도야?

- Claude-1.3 and Claude-1.3 (100K) 는 우등생이다. 성능이 일관되게 완벽하다.
- 하지만 나머지 모델들은 성능이 망가진다. 그리고 망가지는 방식이 U자를 그린다. 즉, 가운데로 갈수록 못하는 경향이 여기서도 보인다.
4. 왜 언어모델들은 가운데로만 가면 정신을 못 차려? 왜 일정하지 못한거야?
: 이를 분석하기 위해 추가적인 실험을 진행한다.
ㄱ. 모델 구조때문인 거 아냐? 디코더 모델말고 인코더-디코더 모델도 불러봐

- 초반에는 좀 더 완강(robust)해보이나 점점 길어질수록 구조에 관계없이 무너지고 만다
ㄴ. Query-Aware Cotextualization
: 잠깐만, 디코더 모델은 질문이 맨 뒤에 있으면 그 전까지 질문이 있는지도 모르잖아? 근데 인코더 디코더 모델은 질문이 있다는 걸 다 알고 시작하잖아. 이거 완전 불리한 거 아니야? 경찰 불러. 우리 디코더 모델도 질문 맨 앞으로 옮겨봐.
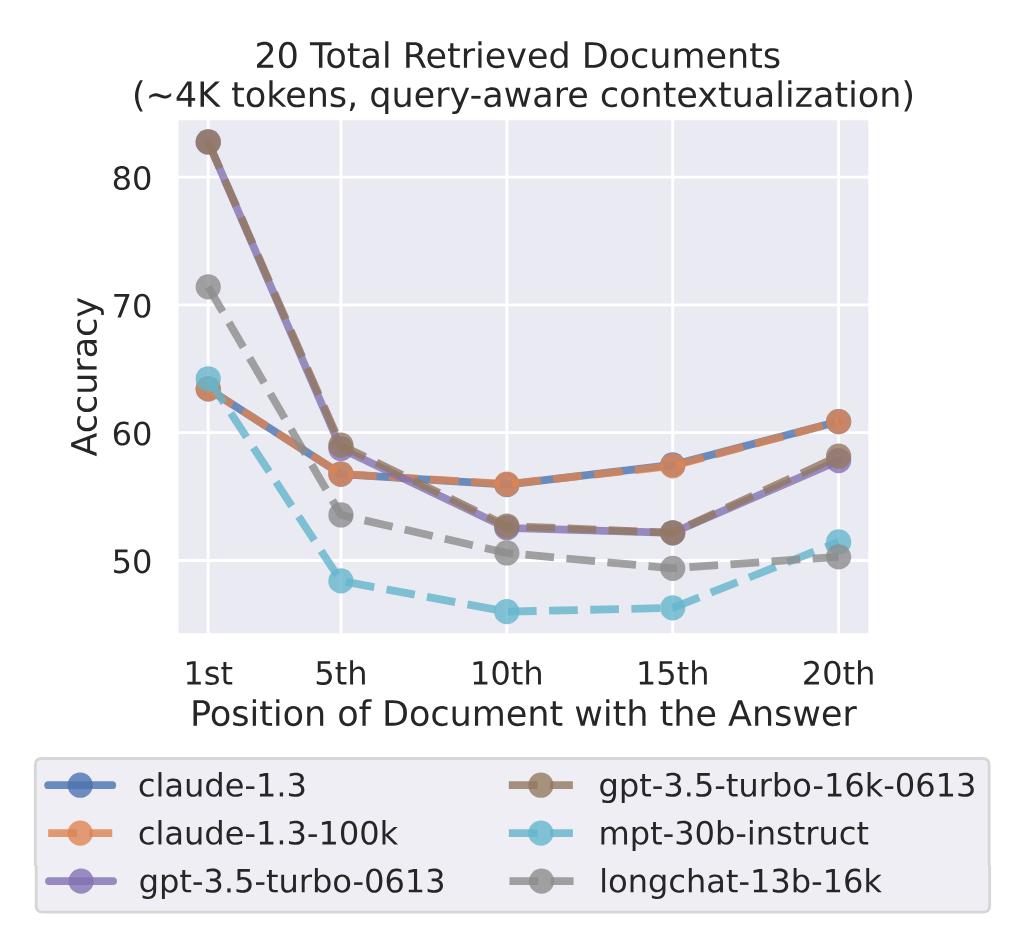
- 질문을 앞으로 옮기니, Key-Value Retrieval 성능은 급격히 올랐다고 한다
- 하지만 위 그래프를 보라. Multi-Document QA는 여전히 엉망이다
ㄷ. Instruction Tuning 이 그래도 도움이 되지 않았겠어?
: 저자는 instruction tuning 이 초반에 주저리주저리 거리니까 U자형 편향이 발생한 게 아니냐고 추측한다. 그래서 Instruction tuning 을 거치기 전 모델로 평가를 진행해서 비교해보자고 한다. 이 편향이 생긴 이유를 Instruction Tuning 이 아니냐고 의심하는 것이다.

- 놀랍게도 둘 다 U자형을 그린다. 저자도 놀랐다고 표현했다.
- 즉, Instruction Tuning 은 성능 향상에 기여했을 뿐 편향을 만들지 않았다는 것이다.
- 기존 언어모델 자체가 처음과 끝에 집중하는 편향성을 갖고 있다는 걸 실험적으로 확인했다.
5. 무조건 문서를 많이 주는 게 좋은거야?
: 문서를 많이 주면 정보를 많이 가져갈 수 있겠지만, 동시에 처리해야 할 양이 많아진다. 이건 데이터셋마다 달라서 일반화하기 어려울 수 있지만 그래도 실험을 진행했다고 한다.

- Contriever: 얘는 문서를 가져다주는 아이다. 당연히 정답이 포함된 문서를 10개 가져오는 것보다 50개를 가져올 때 정답이 포함될 확률이 높다. Recall@K가 문서의 수가 늘어날수록 성능이 급격히 좋아진다.
- Reader: 위에서 Retriever 가 문서를 많이 가져왔다. 그 문서를 다 준다고 해서 성능이 오르는 건 대체로 맞다. 하지만 하락하는 모델들도 있고 무엇보다 변화가 적다. 이럴 거면 많이 가져다주는 게 효과가 크지 않으니 오히려 비용적으로 손해일 수 있다는 말이다.
정리하자면, RAG를 적용하려니 2가지 문제가 있다.
- 입력이 길면 비용만 비싸져. 성능 향상 이득이 없어! (압축, 제거)
- 정답 문서가 가운데 있지 않을수록 좋아. 처음이나 끝으로 이동시켜줘! (재순위)
이걸 어떻게 해결할까에 대한 방법론은 다음 시간에.



